文 | 江瀚视野
最近一段时间,几乎全网都是 OpenClaw 养龙虾的消息,但是在这一众叫好声中却也有不和谐的声音,其中最受关注的无疑是“ 月薪两万,养不起龙虾” 的消息,为啥龙虾会这么贵?
Related articles


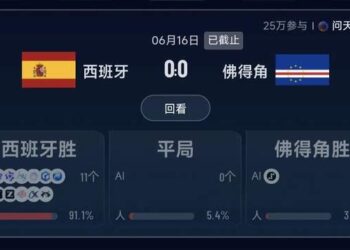
一、月薪两万都养不起龙虾?
据华尔街见闻的报道,朋友圈里有人晒“ 养虾日记”,腾讯大厦楼下近千人排队,还有人愿意掏 500 元请人上门安装,只求赶紧把它跑起来。

很多人没有预料到的是,OpenClaw 的成本并不在软件本身,而在背后的模型调用。它天生就是一个“Token 黑洞”,每执行一个任务,都要消耗大量 Token 与后端大模型交互,一旦任务链拉长、工具调用增多、记忆开启,消耗会迅速抬升。
普通 Chatbot 聊一个来回只需几百 Token;而 OpenClaw 执行同样的任务,可能需要几百万 Token。有用户反映,搜索信息、写一篇 2000 字文档可烧掉 700 万 Token;运行一个简单爬虫测试竟耗费 2900 万 Token;单日烧掉 5000 万 Token 的案例屡见不鲜。
一家 SaaS 公司甚至为全员配置了龙虾补贴,普通员工每日消耗 150 元 Token,技术团队高达 1000 元。更隐蔽的是 OpenClaw 内置的“ 心跳机制”—— 即便在无实际产出的情况下,系统每天仍会自动消耗约 145 元的调用费,折算下来月均损耗超 5000 元。
甚至有自媒体感叹“ 为什么这两天老有人说:月薪两万都养不起 OpenClaw。这话其实没错。你想用得爽,2 万月薪还真不够烧的,只能紧巴巴地体验。”
二、为啥龙虾这么贵?
OpenClaw 作为一款开源软件,本应凭借其开源特性获得更广泛的应用与普及,然而现实情况却是,使用它如同养一只昂贵的宠物,即便月薪不菲也可能会觉得吃力。那么,究竟是什么原因导致其成本如此高昂呢?
首先,开源不等于免费。OpenClaw 的隐性成本的累加,构成了其使用成本的基础框架。很多用户被 OpenClaw 的开源属性吸引,误以为可以零成本享受其强大功能,却忽略了开源软件的核心逻辑,开源是“ 代码开放”,而非“ 使用免费”。开源软件的价值在于降低用户的开发门槛,而非免除所有使用成本,OpenClaw 的使用成本,从部署环节就已经开始累计,且呈现出“ 隐性化、持续性” 的特点。
对于个人用户而言,轻量使用虽可依托现有电脑部署,无需额外采购硬件,但部署过程中需要搭建适配的运行环境,涉及各类开源工具的调试、配置,若缺乏专业技术能力,需额外支付技术服务费用。即使是对于企业用户而言,为保障运行稳定性和并发能力,需采购专用服务器、搭建集群,甚至配置高性能 GPU,这些硬件投入动辄数万元,成为一笔不小的一次性成本。
除此之外,OpenClaw 的日常运行还需要依赖各类第三方服务和插件,无论是语音合成、网页抓取,还是消息平台接入,部分核心功能的扩展都需要支付相应的服务费用,这些隐性成本看似零散,长期累加下来,成为推高使用成本的重要因素。

其次,大模型 API 的调用成本构成了 OpenClaw 日常使用的核心支出。OpenClaw 的核心能力依赖于后端大模型的推理能力,而每一次交互、每一个决策、每一行代码的生成,都在实时消耗着 Token。根据当前媒体统计,即便是个人用户的轻量级使用场景,如日常问答辅助、简单的文件整理或基础的邮件回复,每月的 Token 消耗量也轻松落在 100 万至 300 万的区间,折合人民币约 20 至 80 元。
这看起来似乎微不足道,但一旦进入高频自动化使用场景,成本曲线将呈指数级上升。当用户利用 OpenClaw 进行批量文件处理、多任务 Agent 协同作战或是大规模的网页爬取时,月均 Token 消耗量将飙升至 300 万至 1000 万甚至更高,对应的费用则高达 80 至 300 元,乃至更多。
对于一个依赖自动化生存的企业或重度个人用户而言,这笔看似不起眼的“ 流量费”,在规模化放大后,足以吞噬掉大部分的人力替代红利。Token 不再是抽象的技术指标,而是数字经济时代的“ 石油”,其价格波动直接扼住了自动化应用的咽喉。对于大部分的大模型公司来说,这件事反而成为了一个最赚钱的路径,仅以其中比较有名的月之暗面来看,月之暗面不仅在 20 天的时间内收入超过了 2025 年全年,同时释放了一个信号:海外收入在此时首度超越国内;产品端,面对爆火的 OpenClaw,月之暗面迅速推出 Kimi Claw,限定 199 元级别以上的付费用户可体验,成为国内"五小虎"中首个亲自下场做的云端 Agent 产品,可见 token 的生意到底是一个多赚钱的活计。
第三,自动任务频繁,无形中加剧 token 消耗。OpenClaw 引以为傲的自动化能力,其背后隐藏着大量“ 看不见的工作”,这些静默的算力损耗是造成成本高昂的隐形杀手。很多用户对于成本的理解往往局限于“ 我看到了什么结果”,而忽略了“ 机器为了这个结果做了什么”。OpenClaw 的核心价值在于其 Agent 属性,能够自动化地进行模型处置、任务规划和自我迭代。但这恰恰是成本最容易失控的环节。
想象一下,OpenClaw 在执行一个看似简单的“ 整理会议纪要并提取待办事项” 的任务时,它并非直接给出答案。在后台,它需要先进行语音转文字,再调用大模型进行语义分析,接着进行格式化处理,最后可能还需要进行自我反思以校验准确性。这一连串的“ 思维链” 过程,每一个步骤都需要消耗大量的 Token。这些是用户看不见的“ 后台劳动”,也是成本激增的根源。
更关键的是,为了保证自动化任务的稳定性,OpenClaw 往往需要进行大量的试错。模型在输出最终答案前,可能会在内部进行多次推演、自我纠错。对于传统软件,运行一次代码是固定的算力消耗。而对于 OpenClaw 这样的 AI Agent,同一个任务可能因为上下文理解的偏差或随机性,导致 Token 消耗量呈几何级数增长。
这种不确定性成本,是传统软件工程中从未出现过的。用户看似只是让“ 龙虾” 爬行了一小步,但它在底层逻辑中可能已经进行了无数次的“ 心算”,每一次心算都在扣费。这种“ 黑盒” 式的成本产生机制,是导致用户感觉“ 没干什么大事却花了很多钱” 的根本原因。
第四,Token 正日益成为制约 OpenClaw 普及的结构性瓶颈。从经济学的逻辑来看,一项技术的普及程度取决于其边际成本是否低于其所替代的人力成本。当前,Token 的高昂价格正在构建一道高高的门槛。如果 OpenClaw 无法在算法效率上取得突破,或者大模型厂商无法大幅降低 API 定价,那么其应用场景将被迫局限于高价值、低频次的领域,而无法渗透到海量的长尾场景中。
对于广大中小企业和个人开发者而言,如果自动化带来的收益无法覆盖 Token 的消耗成本,那么“ 养龙虾” 就成了一种奢侈的消费行为,而非生产力的升级手段。这种成本结构的失衡,会导致技术鸿沟的进一步拉大,只有资本雄厚的大玩家才能负担得起大规模的自动化部署,而普通用户只能望而却步。
因此,Token 问题不仅仅是技术优化问题,更是商业模式能否跑通的生死线。如果不能有效解决 Token 消耗的性价比问题,OpenClaw 的普及必然会受到严厉的限制,甚至可能陷入“ 叫好不叫座” 的尴尬境地。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App