文 | 舒书
在武汉经开区南太子湖创新谷,一位智能体创业者点了一杯咖啡,获得了 20 万 Token(词元) 的免费算力额度。
20 万 Token 能做什么?约等于在主流大模型上生成几万字的文本,或处理数十页文档——商业价值约在 0.5 到 1.5 美元之间。与其说这是一笔实质性补贴,不如说是一个具象化的信号:算力正在成为地方政府招商的新筹码。
2026 年 3 月,国家数据局局长刘烈宏正式将 Token 的中文名定为词元,定义为智能时代的价值锚点、连接技术供给与商业需求的结算单位。
需要厘清一个概念:严格来说,算力才是商品,Token 只是算力消耗的计量单位。地方政府发放的 Token 券,本质上是限定本地指定算力平台使用的算力抵扣额度,并非可直接兑换成现金或自由流通的标准化资产。Token 目前仅作为 AI 服务计费计量单位,严禁证券化、代币化和公开交易变现。
过去,地方政府招商靠的是给土地、给税收优惠。如今,新的筹码出现了。2026 年,一场围绕词元的招商竞赛,正在全国悄然展开。
一、Token 调用量:两年千倍的增长曲线
Token 是 AI 大模型处理信息的最小语义单位,具备可计量、可计价、可核销的特征。
据 IDC《中国 AI 算力市场跟踪报告》 及阿里云、华为云公开数据 (统计口径为公有云 API 调用量,不含私有化部署),2024 年初中国日均 Token 调用量约 1000 亿;2025 年底跃升至 100 万亿;2026 年 3 月已突破 140 万亿——两年增长超千倍。Token 调用量已成为衡量 AI 模型活跃度和产业价值的关键指标。
Token 贯穿 「能源—芯片—算力—模型—应用」 五层价值链,成为衡量 AI 产业活力的核心标尺。武汉市经信局人工智能产业处相关负责人直言:「在 AI 产业的飞速发展期,所有人都是站在同一条起跑线上,谁早、谁快、谁主动,谁就最有可能抓住新的机遇。」
但 Token 的消耗量并不等同于价值创造量。一个消耗百万 Token 的客服机器人和一个消耗十万 Token 的代码生成工具,后者可能创造更高的商业价值。Token 计量的只是量,而非质。没有高质量数据喂养,再便宜的 Token 也只能产出低质量内容甚至幻觉。当前 Token 补贴主要覆盖算力消耗,但对高质量语料获取、数据标注、合规数据集建设的补贴同样稀缺——这意味着 Token 的使用成本降下来了,但生成物的价值未必同步提升。
二、地方政府的新玩法:从抢企业到抢 Token
今年以来,武汉、贵阳、庆阳等地密集推出政策,用算力和 Token 作为招商新筹码。
三类典型打法
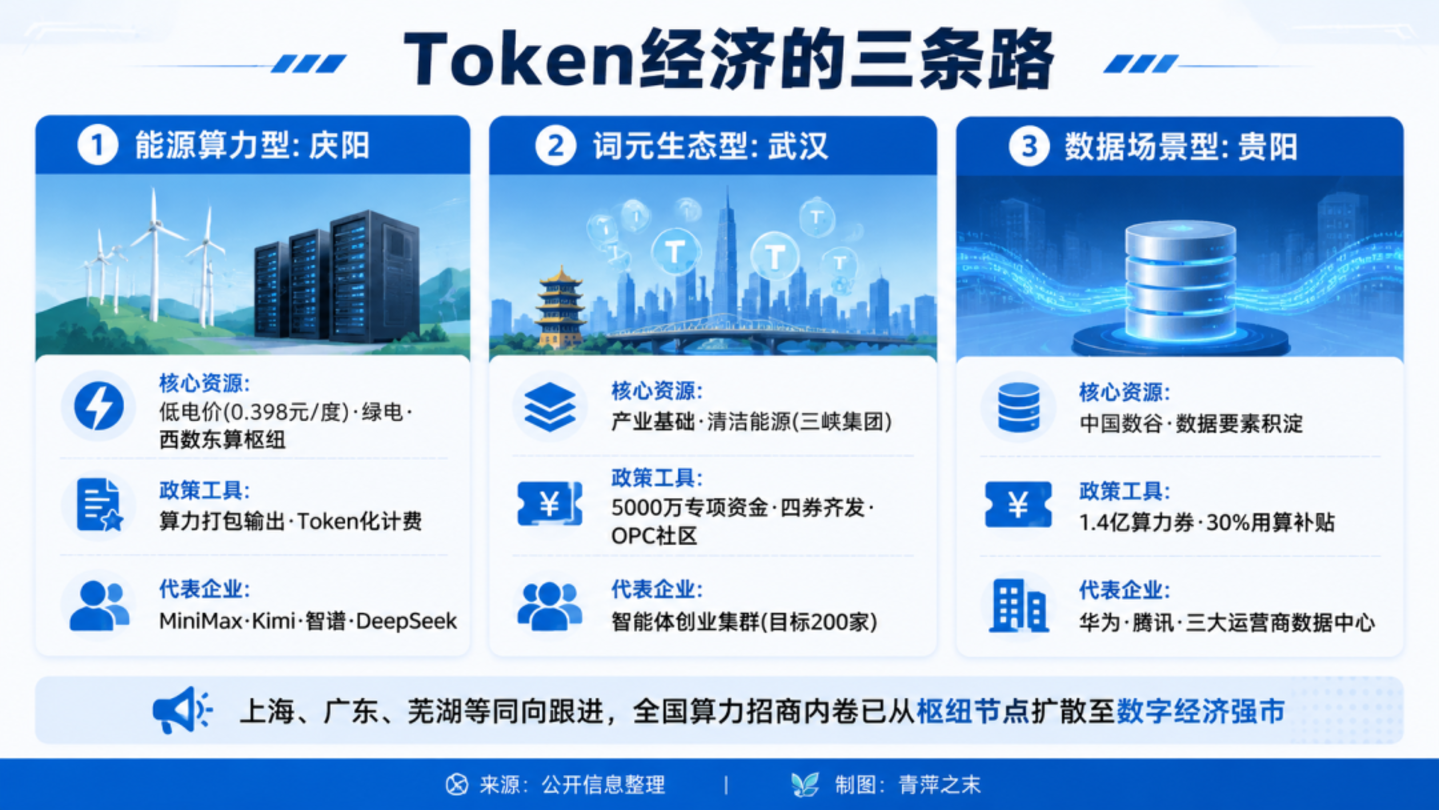
第一类:能源算力型城市——卖算力服务而非卖机架
甘肃庆阳是典型代表。作为东数西算八大国家级枢纽节点之一,庆阳拥有低至 0.398 元/千瓦时的电价优势,数据中心 PUE 值稳定低于 1.2。据庆阳市政府公开数据,累计对接 (指签署意向协议或进行实地考察) 数字经济企业 8126 户,签约 1760 户,落地注册 571 户。MiniMax、Kimi、智谱、DeepSeek 等头部模型均在庆阳部署了训练业务——庆阳已成为 Kimi 大模型核心算力供给地。
2026 年 1 月,总投资 200 亿元的麦子智云万 P 绿色智算中心项目签约落地庆阳,规划部署 20 万台服务器、配备 8 到 10 组万卡集群,核心算力规模达 10 万 PFlops。
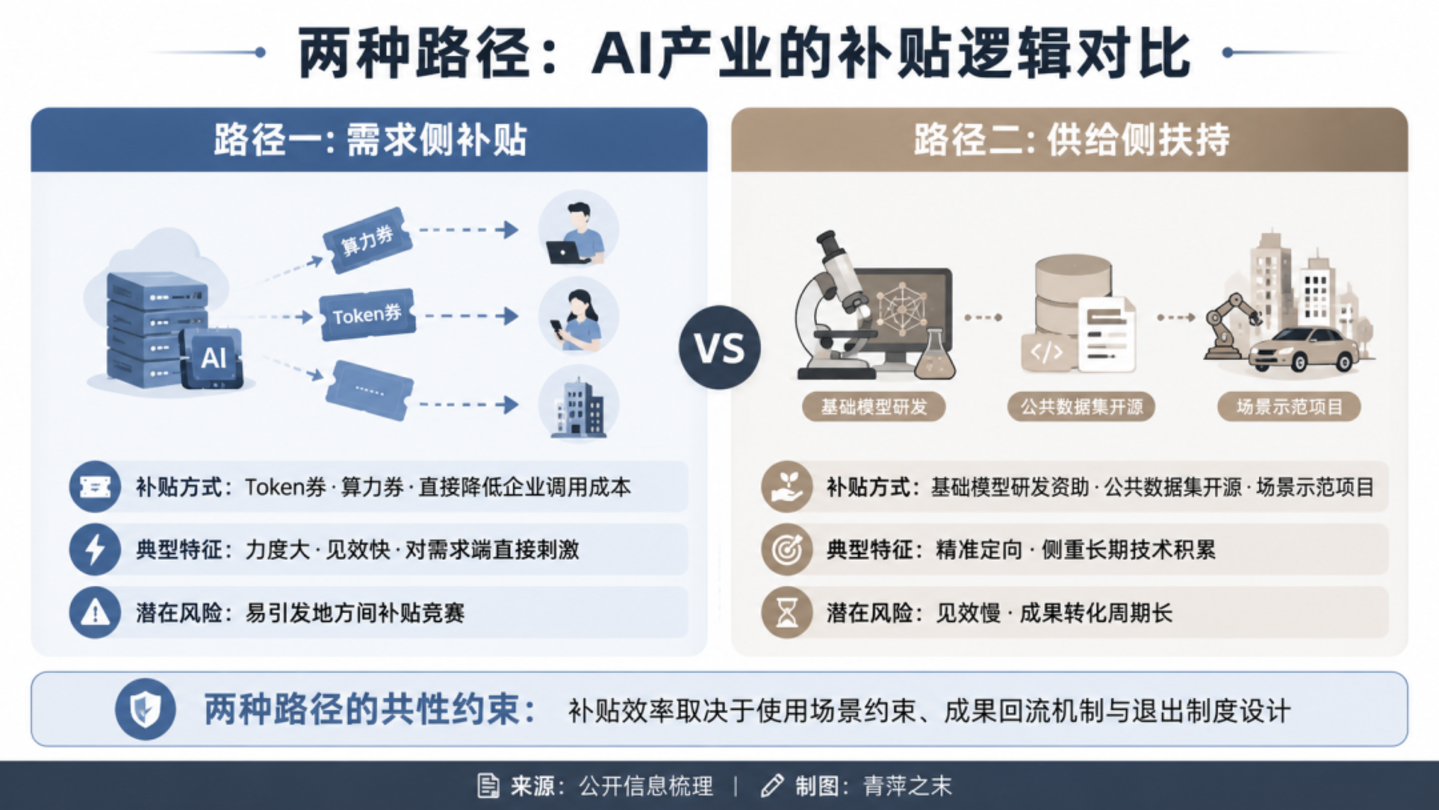
第二类:词元生态型城市——「券+资金」 组合拳
2026 年 4 月,武汉江岸区召开 Token 经济大会,宣布全力打造 Token 经济第一区。江岸区每年统筹 5000 万元专项资金,推出组合拳:
1、每年 1000 万元 Token 券,补贴企业 Token 使用成本
2、每年 1000 万元算力券,支持企业优先应用绿色算力
3、每年 500 万元模型券,支持大模型与智能体研发
4、每年 500 万元数据券,支持数据产品采购与交易
5、每年 1000 万元场景资金,遴选标杆应用场景
6、每年 500 万元支持线上 Token 服务平台建设
7、每年 500 万元支持线下 OPC(AI One-Person Company,人工智能一人公司) 生态社区建设
据江岸区政府公开信息,通过绿电和算力补贴,预计可为企业降低 30%-40% 算力成本。到 2028 年,江岸目标 Token 经济相关产业规模突破 200 亿元,集聚企业超 200 家。
武汉市层面更是大手笔——宣布发放 1 亿元算力券,年内可用算力规模达 1.5 万 P,算力公共服务平台可实现 Token 化服务,高校科研院所、企业、入驻 OPC 社区的个人创业者均可申领。
第三类:数据场景型城市——用数据换产业
贵阳立足中国数谷积淀,自 2026 年 4 月起面向全国发放 1.4 亿元算力券,符合条件的企业最高可享 30% 用算补贴,从算力、数据、模型、业态、场景五大维度协同发力。
保定则依托国家数据标注基地优势,同步布局词元经济。2026 年 3 月发布的支持政策中,对年度采购算力超 30 万元的企业给予最高 30 万元数智券补贴。
全国算力招商内卷正在蔓延。 上海年度算力券投放规模达 6 亿元,芜湖推出最高 100 万元单企业算力补贴,广东、安徽等地同步跟进。算力补贴已从东数西算枢纽节点扩散至各大数字经济强市,成为地方政府产业招商的标配工具。
三、政策落地:理想与现实的温差
政策设计很美好,但落地效果并非没有温差。
问题一:算力券与 Token 券的认知混淆
多位业内人士指出,很多人没有区分算力和 Token。绝大多数 AI 企业的成本压力主要来自 Token 消耗,拿到手的却是用不上的算力券。有专家表示,在人工智能时代,每一个 Token 的流转都是可追溯的:谁提供了算力,谁用了多少,模型消耗了多少资源,清清楚楚。技术上毫无障碍,问题出在政策设计上——深层矛盾在于政策供给与市场需求的错位:有的政策听起来很美,却因脱离企业实际经营场景而难以落地;另一些则因申报门槛高、流程繁琐,将需要扶持的中小企业挡在门外。
问题二:补贴流向头部大厂,中小企业获得感有限
综合多地算力券申报规则,多数地区设置营收、团队规模准入门槛。以武汉江岸区算力券申报公开细则及多位受访 AI 创业者反馈为例,申请门槛要求上年度营收不低于 500 万元或团队规模不低于 20 人,绝大多数 10 人以下团队连申报资格都不具备。即便符合条件,补贴券绑定本地算力平台,而该平台对 PyTorch、vLLM 等主流推理框架的适配度低于企业原本使用的云服务,额外投入的迁移和适配人力成本,可能已经抵消了 Token 价格上的优惠。
业内警示,当前算力消耗线上核验机制尚未全覆盖,存在虚构用算数据骗取补贴的监管漏洞。多地财政审计报告已提示,属地绑定的算力补贴模式下,存在企业异地注册、依托算力平台虚增 Token 消耗套取政策红利的风险隐患。
问题三:国企算力中心承压
地方政府补贴使用端,但不补贴供给端。据 《瞭望》 新闻周刊报道,一家地方国企负责人透露,其建设的算力中心重要任务之一就是服务政府招商。「政府想要提供更便宜的算力吸引企业,民营算力企业不愿干,只能国企干,相当于国企承担了政府招商成本。算力中心建设运营费用都很高,政府的补贴只给算力使用方,不给我们。我们仅能打平运营成本,无法覆盖高昂折旧费。」
被忽略的另一面:传统产业的沉默代价。 财政资源向 AI 新赛道倾斜的同时,也对传统产业数字化扶持资金形成分流。缺乏算力、数据、场景禀赋的三四线城市,如果盲目跟风投放算力补贴,很难实现全域产业转型升级,容易造成财政资源闲置浪费。

四、需要正视的三个核心问题
热潮之下,三个深层问题值得追问:
第一,算力会白菜化吗?——不会全面白菜化
通用推理算力会因地方补贴竞赛而持续降价,但高精度训练算力、私有化部署算力、安全合规算力依然稀缺高价。补贴红利大部分被头部大模型企业拿走,中小创业者看似拿到低价 Token,却面临算力资源被大厂挤占、高峰期算力排队、算力虚标、服务缩水等隐性成本。
更深层的隐患是量质错配:当前词元统一按调用数量计费,同等 Token 消耗下,商业高价值场景与普通闲聊场景定价一致,可能引发逆向选择——企业刻意压缩提示词、降低模型输出质量以节约 Token 成本,而非优化商业价值。这是市场定价机制本身的缺陷。
第二,Token 标准谁来定?——统一计量难度极大
当前国家层面尚未出台统一的 Token 计量和定价标准。不同模型架构、精度、部署方式下 Token 消耗规则不统一;私有化部署 Token 不进入公共统计,无法纳入统一计价;绿色算力、合规数据训练产生的 Token 是否差异化定价,也无明确规则。
更深层的技术障碍在于:不同厂商模型的 Token 切分规则不统一。同样一段中文文本,在 GPT-4、国产模型甚至同厂商不同版本模型下,消耗的 Token 数可能相差数倍。如果 Token 连跨模型的计量一致性都无法保证,统一结算单位的基础就存在根本性缺陷。
更底层的问题是芯片生态的割裂。各地建设的算力中心大量采用国产 AI 芯片 (如昇腾),而主流大模型的训练和推理框架 (PyTorch、vLLM、Triton) 对国产芯片的适配度参差不齐。同样一段文本,在英伟达 GPU 上生成 Token 的能耗和时延,与在国产芯片上可能相差数倍。有效算力的转化率不统一,Token 就更难成为跨平台、跨架构的通用计量单位。
若各地缺乏协同,将导致市场分割、交易成本高,阻碍词元要素跨区域自由流动。有从事数据要素行业的人士建议,国家层面应探索建立词元统一计量和定价标准,完善词元经济治理体系。
第三,补贴能持续多久?——财政可持续性存疑
多地每年数千万专项补贴,若 AI 产业税收长期无法覆盖补贴支出,必然出现政策退坡。一旦补贴取消,依赖低价 Token 生存的初创企业将面临批量淘汰风险。有分析认为,当前 AI 产业存在热闹多、闭环少的风险,不少 AI 企业的收入增长仍建立在资本开支扩张上,尚未形成稳定、可复购的商业模式。
从历史经验看,光伏、新能源汽车等行业均采取了阶梯式退补方案:早期高补贴、中期逐年递减、后期完全退出,并配套技术门槛 (如光伏转换效率、新能源车续航里程) 倒逼企业升级。Token 补贴若要避免断奶即死的结局,同样需要类似的制度设计——限时、退坡、叠加技术进步考核。

五、算力版图正在重塑,但远非西算通吃
Token 经济的兴起,正在重构中国的算力版图。但西部能源转 Token 输出的判断需要审慎看待。
西部的机会确实存在。庆阳、包头等地依托风光电资源,把电力资源转化为可按词元计价的算力服务。中国电信宁夏分公司 2026 年 4 月启动 Token 工厂生成能力服务集采,项目框架协议规模达 174.38 亿元。本次集采并非直接采购标准化词元资产,而是将算力服务、模型调用能力统一以 Token 作为计费口径开展大规模集中招标采购。
但西部的局限同样明显。风光电存在消纳波动、季节性供电不稳定,绿电算力无法全天候稳定供给大规模模型训练,西部只能承接离线大模型训练,高频实时推理、智能体应用依然需要东部低时延算力支撑。东数西算本身已有跨区域算力调度规则,地方依托 Token 券设置区域算力壁垒,或将与全国一体化算力调度的顶层设计产生潜在冲突。
顶层设计正在跟进。 从东数西算工程到全国一体化算力网建设,从高质量数据集建设到数据要素市场化改革,政策链条逐步成型。但如何平衡地方招商竞争与全国要素自由流动,仍是未解的难题。
六、一条被忽视的隐形风险:数据安全与合规
大量企业依托异地公共算力平台训练模型,企业商业数据集、用户提示词伴随 Token 跨区域流转。数据出境、隐私泄露、训练数据集版权侵权等合规风险,尚未纳入各地算力补贴前置审查范畴。一旦发生大规模数据泄露或版权纠纷,不仅影响企业自身,还可能对整个词元经济的合法性构成冲击。这一维度的制度建设,目前仍处于空白状态。
结语
从东数西算到送 Token 券,算力正在从国家战略基础设施下沉为地方政府招商筹码。这不是一场所有城市都能参与的竞赛。 庆阳靠的是西数东算加极低电价,武汉靠的是产业基础加清洁能源,贵阳靠的是多年数据产业积淀。更多三四线城市既无绿电、无数据、无 AI 场景,盲目跟风大概率造成财政浪费。
Token 能否像水电一样成为普惠资源,还是会被少数算力枢纽城市垄断?答案取决于三个变量:统一计量规则何时出台、补贴退出机制如何设计、跨区域流通如何实现。
未来词元经济良性发展,需要三层制度约束:一是国家出台跨模型、跨芯片架构的 Token 统一计量国家标准;二是各地算力补贴绑定企业本地税收、就业、知识产权落地绩效,设置 3 至 5 年阶梯退补机制;三是搭建全国一体化算力券通用核销平台,破除地方算力属地壁垒,让词元要素自由流动。
真正的挑战不在于选择市场还是补贴,而在于如何设计一套让两者共存的制度——让市场发现价格,让补贴校正市场失灵,同时避免补贴扭曲价格信号。这个平衡点的寻找,才刚刚开始。