文 | 字母 AI
近期,Qwen 技术负责人林俊旸的离职,让外界再次把目光投向阿里的 AI 版图。
Related articles


而在林俊旸离职的同时,Qwen 团队内部也出现多位核心成员调整。外界很快把这次变动解读为一次“Qwen 重组风波”,并将其与阿里近期频繁的 AI 业务规划联系在一起。

阿里方面对此回应称,将继续坚持开源模型策略,持续加大 AI 研发投入并吸纳优秀人才。抛开“ 宫斗” 的成分,这一轮团队重组背后,是围绕 Qwen 展开的、阿里试图重建 AI 技术底座的大动作。
而在行业内,被反复拿出来与阿里/Qwen 对比的,一定少不了字节跳动。从 Qwen 模型和 Seed 系列;从千问 App 到豆包 App 的红包大战;再到阿里云和火山引擎的 AI 云市场版图之争。
从 Token 调用量视角来看,在 IDC 统计的公有云大模型调用量中,火山引擎已经拿下接近一半的 Token 份额,成为国内调用量最大的 AI 云平台,阿里云位列第二。而在另一份 AI 云市场报告里,阿里云仍然占据中国 AI 云收入第一的位置。
不同的统计口径下,字节和阿里在 AI 业务上都有被认可的“ 第一”。
阿里选择了一条更接近开源生态的路线。Qwen 系列模型持续开放权重,希望通过开发者社区、企业技术团队和私有化部署场景,把模型变成新的技术标准,再反过来带动云平台与企业解决方案。
字节则更像把 AI 能力做成一种平台服务。Seed 和豆包等核心模型大多保持闭源,通过火山引擎 API 集中提供,模型能力优先在抖音、剪映等产品体系中落地,再向外输出。
换言之,一家公司优先争取开发者和企业技术团队,另一家公司优先占据 AI 应用流量与产品入口。
由此,围绕林俊旸离职的讨论也很快被进一步延伸:在中国 AI 竞争进入深水区的今天,阿里还会不会继续开源路线?以阿里和字节为代表的两个体系,究竟是在走向两条平行线,还是会在某个节点殊途同归?
01 开源和闭源背后,字节和阿里的两个“ 第一”
一直以来,林俊旸被认为是阿里开源模型体系的主要推动者之一。他离职的消息,在全球 AI 开源社区引发的反应远超一般的人事变动。
Hugging Face 亚太生态负责人王铁震用“ 巨大损失” 来形容这次变动,众多开源社区的贡献者也在社交媒体上留言致意。
而在年初举行的 AGI NEXT 论坛上,林俊旸在对 Qwen 开源矩阵如数家珍后,坦言自己希望推进 Qwen3-Max 大模型的开源,但未能如愿。
因此,当他离职告别阿里时,很多人将这一重要人事变动总结为阿里模型策略即将发生变化的信号。

“ 我觉得 Qwen 有可能会战略性收缩,因为它现在模型矩阵摊得太大了。” 某头部 AI 厂商产品经理周野,这样看待未来 Qwen 可能发生的变化。
周野所在的厂商在 MaaS 等领域与阿里云、火山引擎是直接竞争对手。他表示:“Qwen 大概率还是会走开源路线,但应该会变得更聚焦。”
周野口中的“ 聚焦”,指的是逐步减少模型参数档位和类型分布。过去一年中,这种收敛趋势普遍出现在行业内的开源模型公司中。
以 DeepSeek 为例,其早期发布的版本包含 1.3B、6.7B、33B、67B 等多种参数规模,形成完整模型梯队。但在最新一代体系中,策略明显改变。DeepSeek-V3 系列的迭代中,官方重点只围绕少数旗舰模型展开,再通过蒸馏生成轻量版本,而不再维持完整参数矩阵。
类似趋势也出现在 Meta 的 Llama 系列中:从 Llama2 时期的 7B、13B、34B、70B 四档结构,到 Llama3 之后逐渐收敛为 8B 与 70B 两类核心规模,中间参数档位明显减少。
而作为开源模型界的“ 源神”,Qwen 从 2.5 到 3.5 版本一直维持着庞大的开源模型矩阵,仅不同参数规模就维持在 8 种以上。
就在林俊旸离职几天前,阿里再次开源 Qwen3.5 Small 系列,一次性发布四个小尺寸模型:0.8B、2B、4B、9B。
这组小模型迅速在海外社区引发关注。马斯克在 X 平台点赞并评论称其“ 令人印象深刻”。
林俊旸随后在 X 上表示感谢,但这也成为他宣布离职前的最后一次动态。
“ 当开源矩阵非常庞大的时候,你能卖的 API 种类也会很多。” 周野这样总结 Qwen 团队的开源优势。但他同时也表示:“ 未来模型 Token 价格可能会越来越低。在这样的背景下,维持过于庞大的矩阵,很多小模型可能根本卖不出去。”
这一点从 Token 调用量上的差异也可窥见一斑。IDC 数据显示,2025 年上半年中国公有云大模型服务调用量达到 536.7 万亿 Tokens,较 2024 年全年 114 万亿 Tokens 几乎放大四倍;其中火山引擎占 49.2%,阿里云占 27%。
闭源路线的字节并没有阿里那样庞大的模型矩阵,但在各个模态上都有主力模型实现覆盖。不过,“ 调用量第一” 只是字节视角下的统计口径,一旦把指标换成 AI 云收入,领先者就从字节切回了阿里。
同样是 IDC 报告显示,2025 年上半年中国 AI 云服务收入约 3.9 亿美元,阿里云份额约 23% 居首,火山引擎约 13% 排第二;而放到更外层的整体云市场,字节份额仍只有约 3%。
往外扩展到整体云基础设施市场,这里依然是阿里的主战场。Omdia 数据显示,从 2025 年二季度开始,中国云基础设施市场恢复了稳定的 20% 以上增长,阿里约 35% 的份额仍处于头部位置。
“ 字节在通过非常低廉的 API 价格,去弥补它没有开源生态的位置。” 周野表示,字节有财力把 API 低价铺开,“ 所以它能站在更多产品角度,而不仅仅是技术角度去做考量。”
事实上,早在 2024 年 5 月,火山引擎就在业内首先打起价格战,把豆包主力模型的推理输入价格降至 0.8 元/百万 token,较当时行业价格下降超过 99%,并在之后长期维持这一“ 地板价” 策略。
这使得包括阿里在内的行业竞争对手,不得不持续跟进价格战。
以当前主力模型为参考,Doubao2.0 系列模型输出价格约 2 元/百万 tokens,而 Qwen3.5-Plus API 为 4.8 元/百万输出 tokens。
综上,不难看出,决定市场份额的,不只是模型能力本身,还包括价格策略、产品入口以及平台生态。
当行业竞争逐渐从“ 模型能力” 转向“ 产品与生态” 时,模型团队在公司体系中的角色也开始发生变化。对于阿里而言,这种变化正集中体现在近期的人事风波中。
02 拿到资源的千问,和拿不到资源的 Qwen
舆论漩涡中心 Qwen 是通义实验室架构下的子团队,而在通义实验室中,还有约 500 名研究人员主要负责视觉、语音、多模态模型以及训练基础设施。
从目前披露的信息来看,林俊旸的离职更多源于团队与公司管理层在业务协同上的冲突。而这种冲突的直接原因,来自 Qwen 团队和通义实验室团队的重组,进而失去独立性。而业务层面的间接原因,似乎要追溯到去年下半年以来的 C 端 AI 战场对决。
晚点 LatePost 近期关于这一事件的报道显示,2025 年 9 月,阿里集团决定重点推进千问 App,但 Qwen 团队并没有把支持千问 App 放在高优先级。
而负责千问 App 的智能信息事业群也有自己的模型研究团队。有阿里人士认为,Qwen 团队对云的其他业务以及千问 App 的支持不够。
另一边,字节方面的豆包,在 2025 年从 DeepSeek 身上重新夺回了 C 端第一的位置,也驱动其他 AI 厂商开始争夺 AI 超级入口。
千问 App 被推上前台后,迅速整合了阿里内部的大量资源,先后接入淘宝闪购、飞猪、高德地图等一揽子生态,并在春节档红包大战中拿出了远超其他平台的 30 亿补贴,推出“ 请客” 活动以刺激用户增长。
不过,在去年春节档最核心的舞台—— 央视春晚的合作争夺中,豆包击败其他竞争对手拔得头筹,并在除夕夜连续送出三波红包和抽奖。而千问只能选择加 B 站跨年晚会等节目作为“ 平替”。
“ 阿里有一点强行用千问去触达传统业务的意思,但其实效果说不上特别好。” 对于千问在产品功能上的规划,周野给出了这样的解读。
QuestMobile 数据显示,春节期间“ 三强 AI 应用” 创下 DAU 新高,豆包、千问、元宝的峰值分别为 1.45 亿、7352 万、4054 万,千问则拿下 940% 的最高增幅。
7352 万的峰值成绩,基本追近了豆包在节前已经稳定在约 8000 万 DAU 的量级。换言之,在 30 亿补贴的加持下,“ 春节档” 千问将将追到节前的豆包身后。
但从结果来看,千问在大部分时间已经超越元宝,成为 C 端 AI 应用的第二名 (DeepSeek 近期 DAU 数据未披露)。短短几个月内能够来到行业第二的位置,似乎也并不算是一种失败。
而在定焦 One 披露的报道中,针对外界盛传的“ 因 DAU 不达标导致林俊旸离职” 的说法,有阿里云内部人士予以否认,称阿里管理层并不会以 DAU 作为基础模型团队的核心考核指标。内部评价更看重的是模型在开源社区的影响力,以及模型本身的性能表现。
但豆包在 C 端仅仅是字节的一把“ 开山斧”。随着 Seedance 2.0+即梦、豆包手机助手等产品陆续推出,字节正试图在一些新需求、新场景中进一步“ 围剿” 其他竞争对手。
DAU 也许不是 Qwen 团队的考核指标,但 C 端竞争全面升级,可能引发了阿里管理层的一些战略判断,并逐渐转化为资源整合的动力。
公开报道显示,有阿里内部人士称,Qwen 在除夕当天开源的 Qwen3.5 Plus 模型只能算是一个“ 半成品”。
这一说法不排除存在片面性,但从一些公开数据中,也能看到 Qwen 在部分场景中的存在竞争力问题。
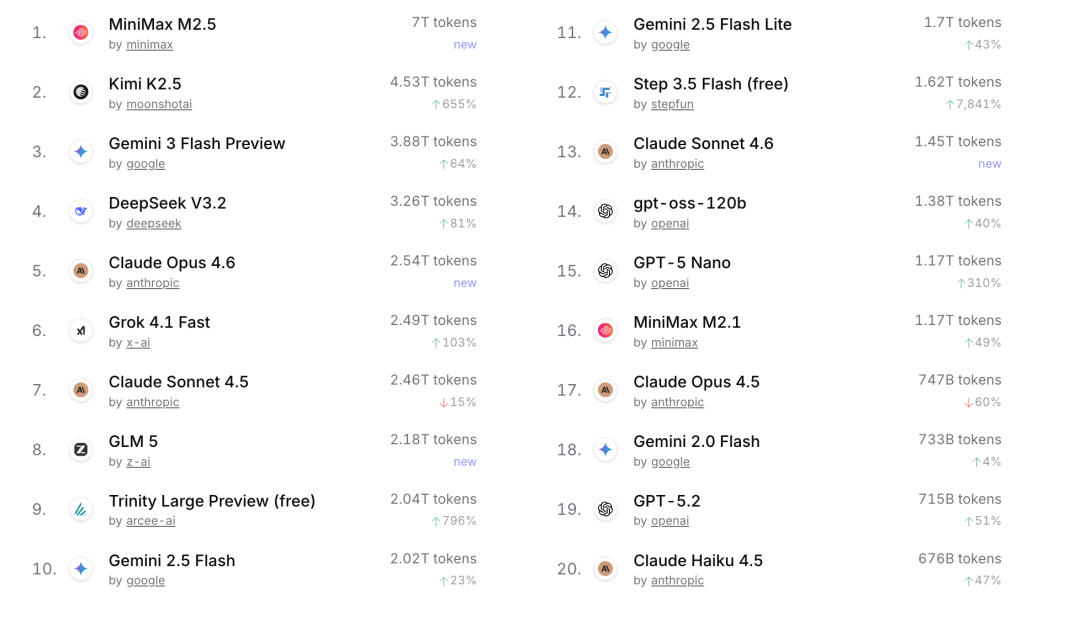
过去一个月的 OpenRouter 模型调用榜单中,前 20 名里出现了 5 家中国模型公司,其中 MiniMax 和 Kimi 的模型分别占据第一和第二。
但值得注意的是,作为“ 源神” 的 Qwen,在这一榜单上却没有任何模型进入前列。
作为个人开发者平台,OpenRouter 的数据或许不能说明全部问题,但至少提供了一个在同一标准下的参考样本。
结合近期披露的一些信息,Qwen 主力模型在某些场景表现出的能力有限,也与团队获得的 Infra 层资源密切相关。
去年年中以来,Qwen 团队开始招聘 Infra 相关人才。有团队成员称,当时在训练新一代核心模型的大尺寸版本时发现,阿里云 PAI 团队已经很难提供足够的 Infra 支持。
而根据阿里方面披露的近期内部会议情况,阿里 CTO 周靖人对此回应称,资源问题和 Infra 支持不到位存在“ 历史原因”。
至于这些“ 历史原因” 究竟应由谁来承担,就不得而知了。
03 OpenClaw 很火,但大模型的红海还没来
把视角转回到那份 OpenRouter 榜单中,MiniMax、月之暗面和智谱的模型都出现在榜单前十。而这一轮国产模型调用激增,其实都指向了同一个产品生态的爆发——OpenClaw。

在“ 龙虾” 圈子里,优秀模型通常要满足几个条件:较低的调用价格、在 Agent 框架下稳定的能力输出,以及适合本地部署的模型形态。
“OpenClaw 对模型公司的最大意义在于,因为它的 Token 消耗几乎是深不见底的,所以大家其实都在跟风。” 在周野看来,OpenClaw 引发的大规模部署, 虽然给模型企业带来了倍增的调用量,但也不意味着已经形成真正稳定的用户需求。
在与周野的交流中,他提到目前 AI 圈的火热,与社会层面对 AI 产业的实际认知之间存在一种明显的“ 撕裂感”。
“ 在今天这个 Agent 时代,很多头部企业的业务人员,还在用网页 Chatbot 去做简单的 QA 问答。” 周野分享了他在企业内部观察到的一个细节。
这种撕裂并不是对 OpenClaw 等 AI 浪潮的否定,而是反映了全民层面的模型认知,与 AI 真实需求成型之间仍然存在距离。
OpenClaw 生态能否成为全民级工具?另一组行业数据或许提供了一些提示。
微软副总裁 Yusuf Mehdi 去年曾在一篇文章中提到,Windows 目前拥有超过 10 亿台月活设备。但这一数字被外媒发现,比微软在 2022 年声称的 14 亿台活跃设备少了不少。
随着移动设备在过去二十年全面普及,PC 市场的萎缩已经成为长期趋势。PC 所代表的“ 个人电脑”,正在逐渐成为专业用户设备的代名词。
这在一定程度上限制了“ 小龙虾” 作为“Computer Use Agent” 的群众基础。但随着 Agent 生态不断突破硬件边界,用户入口从 PC 转向其他设备,或许只是时间问题。
“ 现在整个 AI 产业的加速度太快了,其实我们自己都感觉,跟上这个时代都有些吃力。” 周野坦言道。
换言之,可商业化的 AI“ 真实需求” 还没有大规模涌现。不管是 Qwen 团队还是 Seed 团队,抑或其他独立 AI 模型公司,都还在各类业务场景中不断探索。
此时判断大模型谁会率先跑到技术与商业化的拐点,仍然为时尚早。尤其是作为头部互联网巨头,字节和阿里都拥有足够庞大的业务基本盘,来承接模型场景,同时为大模型业务提供资金支持。
去年,阿里宣布未来三年将投入至少 3800 亿元建设 AI 与云基础设施。而作为 AI 商业化的重要载体,阿里云在数据库、安全、算力调度等领域已经形成完整的生产级基础设施体系。
而在“ 内卷” 竞争的同时,也不能忽视来自外部压力。
“ 和美国公司相比,我们国内 AI 厂商仍然存在一些差距,尤其是在 B 端模型服务模式上,国内厂商还没有真正定义出统一标准。” 在周野看来,中国 AI 厂商当前更应该聚焦挖掘真实需求,同时打磨从模型到产品的完整服务体系。
“ 美国的 Compute(算力) 整体可能比我们大一个到两个数量级,但我看到不管是 OpenAI 还是其他公司,他们大量的 Compute 其实都投入到了下一代 Research 上。” 就在几周前的 AGI NEXT 峰会上,林俊旸也表达过类似观点,指出中国 AI 行业正在面对来自海外的激烈竞争。
从这个角度来看,不管是闭源的字节,还是开源的阿里,都不会缺乏动力来推动中国 AI 产业继续向前。
事实上,过去一年里,国内 AI 企业从硅谷吸纳人才的趋势从未停止。从字节的吴永辉,到腾讯的姚顺雨,再到林俊旸离职风波中提到的那位从硅谷回国的前 Google DeepMind 研究科学家周浩,向硅谷学习的路径正在不断加强。
但如何在中国科技企业体系中,协调好顶级 AI 人才和团队运作,或许是模型能力提升之外更重要的课题。
最后再说两句开源与闭源之争。
IDC 在多份企业 AI 调研报告中提到,随着 AI 在核心业务中的应用不断加深,越来越多大型企业开始强调所谓的“AI 主权”(AI sovereignty)。企业希望掌控模型权重、训练数据和部署环境,而不是完全依赖公共托管服务。
IDC 预测,到 2027 年,约 75% 的企业 AI 工作负载将运行在混合基础设施上,结合公有云、私有云与本地部署。这意味着企业 AI 系统将越来越强调可控性与本地化能力。
某种程度上,这种趋势也为开源模型提供了现实土壤。
另一方面,OpenClaw 的诞生本身就来自开源社区的交流与创新文化。不可否认的是,林俊旸和 Qwen 团队多年来的努力,对中国大模型开源生态的发展起到了重要推动作用。
前往大模型红海的航道上,也许开源与闭源只是环绕地球的两条航线,它们最终都会驶向同一个时代。
(文中受访者为化名)
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App