Related articles

文 | 半导体产业纵横,作者 | 鹏程
在 AI 技术从实验室走向规模化落地的进程中,推理 (Inference) 环节正成为决定体验与成本的核心竞争——专门为推理优化的芯片,已然成为科技行业的新风口。要理解这股热潮,首先要厘清 AI 工作流中训练与推理的本质差异。
在 AI 工作流中,训练 (Training) 与推理 (Inference) 承担着截然不同的角色。训练阶段通过大量带标签数据迭代优化模型权重,使模型能够学习复杂模式;而推理阶段则使用已训练好的模型对新输入进行预测。从性能需求来看,训练如同马拉松,追求整体吞吐量与模型精度的持续提升;推理则如同百米冲刺,核心目标是降低单次预测延迟,实现实时响应。
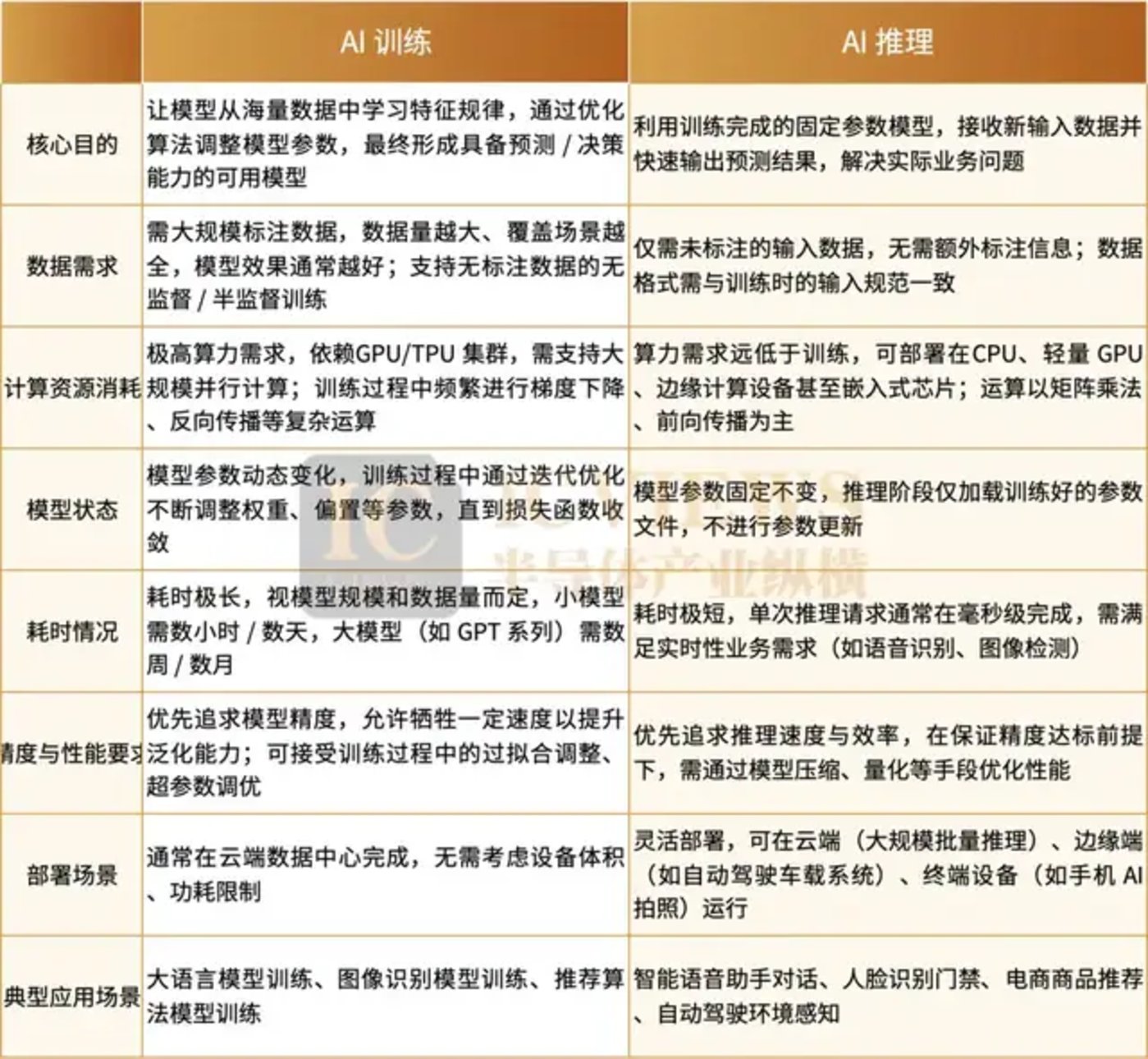
训练阶段需要强大的通用计算平台,通常需要调动成千上万张顶级 GPU,通过海量数据 (如全互联网文本、图片) 进行长时间 (数月甚至数年) 的计算,耗资巨大。训练对算力的绝对性能要求极高,芯片需要具备强大的计算能力和全面的计算能力,能够处理各种复杂的计算任务。目前,英伟达的 GPU 配合 CUDA 软件生态几乎处于垄断地位,难以被其他厂商撼动。
然而,在推理阶段,尤其是大语言模型 (LLM) 的实时交互场景中,情况发生了根本性转变。LLM 的推理过程具有"自回归"特性,即生成第 N+1 个词必须依赖上一轮第 N 个词的结果。这种顺序性导致 GPU 强大的并行计算能力在大多数时间处于"等待"状态,无法充分发挥其优势。
更为重要的是,随着 AI 应用的广泛落地,推理成本在 AI 总成本中的比重日益增加,已成为 AI 企业最大的单项支出。这促使业界开始探索专门的推理芯片解决方案。
为何推理芯片成为刚需?
专门的推理芯片是 AI 发展到规模化应用阶段的必然产物。其主要有以下优势:
第一是性能精准优化。推理任务的核心是高效执行预训练模型的前向计算,如矩阵乘法、卷积运算等。专门的推理芯片 (如 NPU、TPU) 针对这些运算进行硬件级优化,能大幅提高计算效率,相比通用 CPU 或 GPU,可实现更高的吞吐量和更低的延迟。例如,推理芯片可通过定制化的乘加单元 (MAC) 和并行计算架构,加速神经网络的推理过程,满足自动驾驶、智能语音交互等实时性要求高的场景。
第二是能效比优势,推理场景对功耗敏感,尤其是边缘设备和终端应用 (如智能手机、可穿戴设备)。专门的推理芯片通过低精度计算 (如 INT8、INT4) 和硬件级优化,能在保证精度的前提下显著降低功耗,延长设备续航时间。相比之下,通用芯片在低功耗模式下性能受限,难以兼顾性能与能效。
第三是成本效益显著。推理芯片的规模化生产可降低单位成本,尤其在大规模部署场景 (如数据中心、边缘计算节点) 中,其性价比优势明显。与通用芯片相比,推理芯片无需支持复杂的训练任务,可简化硬件设计,减少芯片面积和制造成本,更适合高并发、低成本的推理需求。
第四是场景适配性灵活。不同应用场景对推理芯片的需求差异显著。例如,云端推理需处理高并发请求,要求高吞吐量和可扩展性;边缘设备则需紧凑设计、低功耗和实时响应。专门的推理芯片可通过灵活的架构设计 (如存算一体、Chiplet 技术) 满足多样化场景需求,而通用芯片难以在所有场景中兼顾性能、功耗和成本。
最后,专用推理芯片能加速 AI 全民普及。推理芯片降低了 AI 应用的部署门槛,标准化的接口与工具链简化了开发流程,让更多企业与开发者能够轻松落地预训练模型,推动 AI 技术在各行业的渗透,助力 AI 生态持续繁荣。
可以说,推理芯片是 AI 从技术概念走向实际应用的关键支撑,通过性能、能效、成本与场景适配性的综合优化,成为 AI 规模化发展的核心引擎。
推理芯片赛道:百花齐放,群雄逐鹿
随着需求爆发,推理芯片赛道呈现出多元化竞争格局,一批创新产品凭借独特技术优势脱颖而出。
首先是 LPU,全称 Language Processing Unitix,是一种专门为语言处理任务设计的硬件处理器。它与我们熟知的 GPU(Graphics Processing Unit,图形处理器) 有着本质的区别。GPU 最初是为处理图形渲染任务而设计的,在并行计算方面表现出色,因此后来被广泛应用于人工智能领域的模型训练和推理。然而,LPU 则是专门针对语言处理任务进行优化的,旨在更高效地处理文本数据,执行诸如自然语言理解、文本生成等任务。LPU 由前 Google TPU 团队创立,专为大语言模型 (LLM) 推理设计,采用 SRAM-only 架构,无外部存储延迟,单芯片集成 230MB SRAM,带宽高达 80TB/s,延迟稳定,适合流式生成和交互式应用。
另一家公司 SambaNova SN40L 则跳出了传统 GPU 并行计算框架,自研可重构数据流单元 (RDU) 架构,创造性地将神经网络图直接映射到硬件执行。通过将多步推理计算压缩为单一操作,大幅减少数据在内存与计算单元间的往返传输——这正是 AI 推理中功耗与延迟的核心痛点。其第四代 RDU 产品 SN40L,宣称推理性能达到英伟达 H100 的 3.1 倍,训练性能达到 H100 的 2 倍,而总体拥有成本 (TCO) 仅为 H100 的 1/10。
此外,2024 年发布的第六代 TPU v6(代号 Trillium),也标志着谷歌将主战场从训练转向推理。面对推理成本成为全球 AI 公司最大单项支出的行业现状,TPU v6 从架构到指令集全面围绕推理负载重构:FP8 吞吐量暴涨、片上 SRAM 容量翻倍、KV Cache 访问模式深度优化、芯片间带宽大幅提升,能效比相比上一代提升 67%。谷歌直言,这一代 TPU 的目标是成为 「推理时代最省钱的商业引擎」。2025 年推出的第七代 TPU(TPU v7,代号 Ironwood) 更是聚焦超大规模在线推理场景,成为 TPU 系列首款专用推理芯片。与此前侧重训练的 v5p、侧重能效的 v6e 不同,Ironwood 从第一天起就锁定超大规模在线推理这一终极场景,并在多项关键指标上首次与英伟达 Blackwell 系列正面抗衡,成为全球 AI 基础设施领域的焦点产品。
巨头出手:英伟达 200 亿 「收编」 推理黑马
面对推理赛道的激烈竞争,芯片巨头英伟达祭出重磅大招。
当地时间 12 月 24 日,AI 芯片初创企业 Groq 宣布与英伟达达成非独家推理技术许可协议。根据协议约定,Groq 创始人乔纳森・罗斯、总裁桑尼・马达拉及核心技术团队将正式加盟英伟达,携手推动授权技术的迭代升级与规模化落地。
值得注意的是,Groq 将继续保持独立运营地位,西蒙・爱德华兹已接任公司首席执行官,旗下 Groq 云服务亦维持正常运转,不受此次合作影响。英伟达首席执行官黄仁勋在内部邮件中指出,此项合作将显著拓宽公司技术版图 —— 英伟达计划将 Groq 低延迟处理器整合至 NVIDIA AI 工厂架构,进一步增强平台对各类 AI 推理及实时工作负载的服务能力。
这宗以非独家技术许可为核心的交易,堪称美国科技巨头近年的 「标准操作」。微软、亚马逊、谷歌等企业均曾通过类似模式,在不触发全资收购的前提下,吸纳顶尖 AI 人才、获取关键技术壁垒。其核心逻辑在于,这种轻资产合作方式可有效规避当前美国严苛的反垄断审查。尽管监管机构已开始关注此类交易,但迄今为止,尚无任何一笔同类合作被裁定撤销。
对于手握 606 亿美元巨额现金储备的英伟达而言,这无疑是一笔双赢的战略布局:既消解了潜在的市场竞争威胁,又进一步加固自身技术护城河。据悉,该交易涉及资金规模约 200 亿美元,较 Groq 数月前融资时 69 亿美元的估值溢价近三倍。这一数字,也标志着 Groq 作为独立硬件挑战者的征程暂告一段落,但其核心技术将在英伟达的生态体系中,获得更广阔的研发与应用平台。
对 Groq 而言,200 亿美元的现金流不仅极大缓解了公司财务压力,也为现有投资者创造了丰厚回报。尽管核心团队并入英伟达体系,但 Groq 凭借新 CEO 的到任与独立运营架构的保留,得以继续深耕 Groq Cloud 云服务业务。更重要的是,依托英伟达的资源优势,Groq 的技术有望触达更丰富的应用场景,加速商业化落地进程;同时,这种 「非全资收购」 的合作模式,既规避了品牌灭失的风险,更为企业未来发展预留了充分的自主空间。
英伟达的推理芯片野心,如何通过 LPU 技术降低推理成本
显然此次获取到 Groq 的技术许可,将有利于降低英伟达未来推出的推理专用芯片的成本。
通过此次合作,NVIDIA 成功斩获 Groq 核心知识产权,得以直接应用其 SRAM 架构技术,一举绕开 HBM 高带宽内存与台积电 CoWoS 先进封装的双重限制。不妨设想:依托这项技术,NVIDIA 有望打造一款专攻 AI 快速推理的芯片产品,凭借极致的运算速度,再搭配 NVLink 互联技术,实现多颗 LPU 芯片的无缝协同,释放更强劲的算力效能。
Groq LPU 芯片的核心优势,在于将 AI 模型的核心权重数据,从传统方案依赖的外置 HBM,迁移至芯片内置的 SRAM 中。这一设计使得芯片无需频繁与外部存储交互调取数据,算力效率自然实现跃升。而且,SRAM 的读写速度可达 HBM 的 10 倍。HBM 方案的弊端则十分突出:不仅需要依托台积电的 CoWoS 封装技术,还受制于存储厂商的产能限制,早已成为制约 AI 芯片大规模量产的关键瓶颈。
一旦跳过 HBM 与 CoWoS,直接采用 SRAM 架构,芯片的生产效率将迎来质的飞跃。更值得一提的是,若在电路板中集成 NVIDIA 的 NVLink C2C(芯片间直连技术),LPU 芯片的扩展能力还将远超当前水平,从而让数据传输更迅捷、更稳定。
如此一来,NVIDIA 既无需依赖美光、三星、SK 海力士等厂商的 HBM 产品,彻底摆脱内存供应瓶颈;又能规避台积电 CoWoS 封装的产能掣肘,实现供应链的自主可控。
此外,尽管 Groq LPU 芯片受限于内存容量,更适配轻量级 AI 模型,但在低延迟场景 (如机器人实时控制、端侧 AI 交互) 中具备得天独厚的优势。而这恰好与 NVIDIA GPU 擅长处理大模型的能力形成互补——LPU 化身 「高效快手」,GPU 担当 「算力基石」,二者强强联合,将进一步巩固 NVIDIA 在 AI 领域的霸主地位。
恰逢 CoWoS 封装产能紧张、HBM 成本居高不下的行业背景,NVIDIA 这套 「SRAM+NVLink」 的组合拳,堪称破局关键。200 亿美元的合作对价看似不菲,但对于 NVIDIA 这样的行业巨头而言,无疑是一笔 「花小钱办大事」 的划算买卖。合作达成后,Groq 可保持独立运营,NVIDIA 则收获核心技术与顶尖人才,最终实现双赢。
对于普通消费者而言,这场技术革新的红利同样触手可及:未来的 AI 推理将更快速、更经济,聊天机器人的响应会变得毫秒级迅捷,服务机器人的动作也将愈发流畅自然。与此同时,SRAM 市场的热度或将持续攀升,英特尔等相关产业链企业也有望从中分得一杯羹,推动整个行业生态的繁荣发展。