(本文作者为 时间线 Timelines,钛媒体经授权发布)
Related articles


文 | 时间线 Timelines,作者 | 赵明,编辑 | 周易
摩尔线程正在努力重新定义自己。

过去五年,摩尔线程被外界定义为一家国产 GPU 公司;但目前,摩尔线程正在有意推翻这一定位。其中的一个典型例证是,在其上月召开的年度产品发布会上,摩尔线程用接近 2 个小时的时间,一口气完成六大重磅发布:
从万卡级规模的夸娥智算集群,到自研“ 长江”SoC 驱动的智能终端 MTT AICUBE 和 MTT AIBOOK;从数字世界智能体“ 小麦”,到加速物理 AI 落地的首个全栈具身智能仿真平台 MT Lambda,再到持续进化的 MUSA 生态。
通过这一系列动态,摩尔线程全面展示了一个覆盖“ 云 - 边 - 端” 的全栈智算矩阵。

令人好奇的是,作为外界认知中的一家典型的 GPU 公司,这场发布会上却没有发布一款芯片产品,反而将触角延伸到了具身智能、家居中枢以及硬件层面。
所以,一个问题就自然浮现了:这家以 GPU 为基本盘的公司,究竟想要做什么?
从万卡集群到十万卡
如果把时间的指针拨回到一年半以前,摩尔线程的叙事重心还相当简单——GPU。
2025 年底,当摩尔线程登陆科创板时,支撑其 3000 亿估值的核心资产是夸娥 (KUAE) 万卡级智算集群—— 这是一套可以并行驱动数千甚至上万颗 GPU 训练大模型的系统级解决方案。
随后一年半,这套方案拿出了一组关键数据:Dense 大模型训练中模型算力利用率 (MFU) 达 60%,MoE 大模型达 40%,有效训练时长 90%,8000 卡规模的集群训练线性扩展效率达 95%。“ 堆卡易,成阵难”—— 集群越大,系统越脆弱,一次链路抖动、交换机异常就可能触发连锁反应。夸娥能跑出 90% 的有效训练时长,说明它在系统级工程能力上已经越过了国产 GPU 此前普遍被诟病的“ 集群不可用” 这道坎。
2026 年 3 月 30 日,摩尔线程签下了一笔 6.6 亿元的夸娥智算集群合同,单笔订单占 2025 年全年营收的 44%。这是迄今为止国内算力市场最大的国产 GPU 单笔订单之一,证明了摩尔线程的产品已经能够支撑万卡级别的智算集群建设。
4 月 26 日,摩尔线程同时发布了 2025 年财报以及 2026 年一季度财报,进一步回答了云端基本盘的支撑力。
财报显示,2025 年营收 15.06 亿元,同比增长 243.37%;2026 年一季度营收 7.38 亿元,同比增长 155.35%,归母净利润 0.29 亿元—— 这是摩尔线程自 2025 年 12 月科创板上市以来,首次在单季度实现盈利。
基于这样的亮眼成绩,张建中也在公开场合表示,公司正在规划新一代十万卡级智算集群。
这样的扩张节奏折射出一种强烈的乐观预期—— 张建中判断,随着以 OpenClaw 为代表的 Agentic AI 应用深入,Token 消耗量正呈指数级增长,日均消耗量已从一年前的 30 万亿猛增至 180 万亿。
他认为智算时代需要建立“ 三大 AI 工厂”—— 模型训练工厂、Token 生产工厂、智能体生产工厂—— 而夸娥集群的任务,就是同时支撑这三种截然不同却又相互交织的算力需求。
这套逻辑本身并没有什么问题,但它形成了一个颇为微妙的处境:如果摩尔线程要继续巩固其云端基本盘,就必须在十万卡级集群的建设上持续投入。
财报数据显示,2025 年,摩尔线程研发投入达 13.05 亿元,占营收比重 86.68%—— 换言之,公司赚到的每 100 元里,有 87 元被重新投入研发。即便到了盈利明显改善的 2026 年一季度,研发投入占比仍维持在 50% 左右。这一比例,在 A 股所有上市公司中都属极高。相较而言,国内芯片龙头海光信息的研发投入占比约为 18%,寒武纪约为 50%,台积电约为 8%。
这意味着天文数字的资本开支;但仅靠靠 GPU 这条路能否支撑摩尔的估值天花板,又是另一个值得追问的话题。
但摩尔线程的压力也不止于此。
2023 年至今,全球正在经历一场有史以来规模最大的算力军备竞赛。训练一个顶级大模型,需要数以万计的 GPU 集群—— 英伟达 GPU 由此变成了稀缺战略资源,价格高涨的同时还一卡难求。
对中国 AI 产业而言,这场算力竞赛的紧迫性被额外压力所放大。2022 年至今,在地缘政治的影响下,英伟达的 GPU 几乎无缘中国市场。这一背景下,国产 GPU 的战略价值从"可选项"变成了"必选项"。
在这个背景下,包括摩尔线程、壁仞科技、海光信息、天数智芯在内,一批国产 GPU 公司相继登场—— 但在技术变革和激烈竞争的双重维度下,仅靠 GPU 来讲故事,显然已经不是摩尔线程的解法。
从 GPU 到智能 SoC
如果把云端算力比作“ 超级大脑”,那么端侧产品就是 AI 触达每个人的“ 神经末梢”。但 GPU 公司在端侧的布局,通常止步于提供 AI 推理芯片。摩尔线程的做法不太一样。
发布会上,摩尔线程除了延续云端叙事外,重点推出了自研“ 长江” 智能 SoC 芯片、基于它的 MTT AICUBE 家庭 AI 中枢和 MTT AIBOOK AI 算力本、以及名为“ 小麦” 的全域智能体和 MT Lambda 具身智能仿真平台。

“ 长江”SoC 不是一颗简单的 GPU 或 NPU,而是一颗完整的端侧 AI 计算芯片。它内部集成了 CPU、GPU、NPU 和 VPU,异构 AI 算力达 50TOPS,对标对象不是英伟达,而是高通、联发科甚至英特尔的酷睿。
基于“ 长江”SoC,摩尔线程构建了一套完整的产品矩阵:MTT AIBOOK(个人 AI 算力本)、MTT AICUBE(家庭 AI 中枢) 和 MTT E300(工业边缘 AI 模组)。其中 AICUBE 定位“ 智能体 + AI PC + AI NAS” 三合一,搭载全域智能体“ 小麦”,集成 90 余项系统工具和 60 余项技能,支持超 36 款 APP 跨应用控制。
再往上,是一整套软件栈,包括原生 Linux 操作系统、MTClaw 智能体框架、PES 应用市场,以及 MUSACODE AI 编程工具。
这套“ 芯片— 操作系统— 整机— 智能体” 的产品链条,已经覆盖了传统上由四类不同公司承担的角色:英伟达 (GPU)、高通 (端侧 SoC)、联想 (PC 整机) 和微软 (操作系统)。摩尔线程试图把这四件事打包成一个统一的故事—— 智能体时代的基础设施。
“ 整个业界缺少一个 Linux 原生的好产品”,张建中在产品发布会上表示。
潜台词是智能体时代的电脑不应该再跑 Windows。这个判断的根据在于:OpenClaw 主要跑在 Linux 上,AI 训练框架原生跑在 Linux 上,大模型推理服务的部署环境也大多是 Linux。如果智能体真的成为 PC 的主要工作负载,被 Windows 锁了近三十年的消费级 PC 市场,理论上存在松动的可能。
摩尔线程不是在做一台“ 能跑 AI 的笔记本”,市面上现在所有笔记本都能跑 AI。它想做的是“ 让 AI 跑得比 Windows 更顺畅的笔记本”,然后靠“ 长江”SoC、AI 操作系统和自家智能体框架这一整套组合,在 Windows 还没反应过来的窗口期里,卡住一个新的生态位。
这个判断是否能成立,将取决于两个关键变量:第一,对话式智能体是否真的成为主流交互方式;第二,摩尔线程的 AICUBE 能否在被验证之前赢得足够的时间和用户。这是一个关于未来的押注,而任何押注都是有风险的。
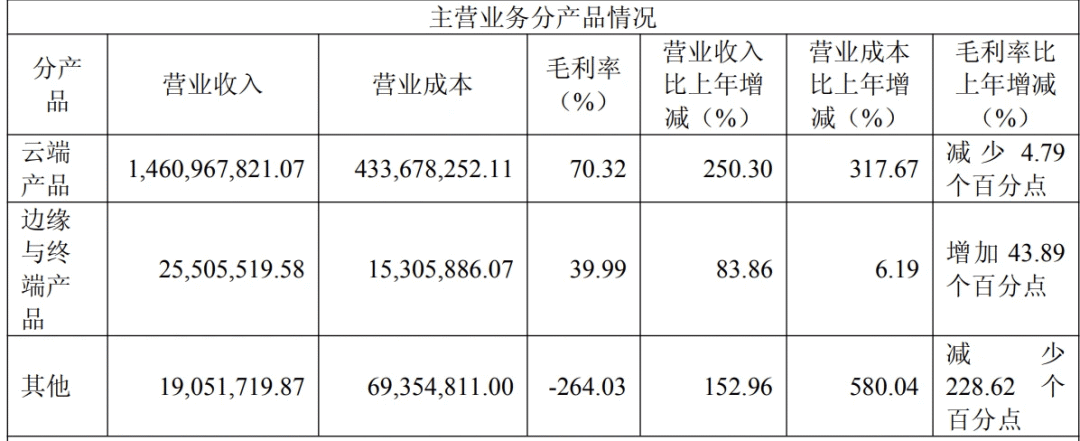
但这场押注也并非毫无根基。2025 年财报显示,摩尔线程边缘与终端产品收入仅 2550.55 万元,占总营收的 1.70%。几乎可以忽略不计。
这意味着,从云端切入端侧,不是因为它已经做大了端侧市场,而是因为它必须用端侧的故事,打开估值想象的第二曲线。在纯 GPU 赛道上,摩尔线程面对的不仅是英伟达的生态壁垒,还有国内对手们在集群和软件栈上的贴身追赶。如果不主动拓展战场,单纯依赖夸娥集群的订单增长,很难撑起 3000 亿市值背后的增长预期。
所以,端侧不仅是产品线的延伸,更是一张对冲估值风险的牌。

MUSA 能否长出独立开发者体系?
硬件可以追赶,生态如何建立?
过去几年,国产 GPU 已经验证了硬件能力—— 通过架构迭代和工程优化,国产芯片能够交出高分答卷。但企业采购 GPU 从来不是只买一张卡,而是在押注其背后的软件生态和开发体系。
与英伟达构筑的 CUDA 护城河逻辑相似,摩尔线程深知单一硬件无法定义未来,因此打造了一个纵深极广的生态系统 MUSA,底层集成了 AI 计算、3D 图形渲染、高性能计算与智能视频编解码的全功能 GPU,以全数据单元的兼容性将算力触角延伸至科学计算、数字孪生、具身智能、量子计算乃至 6G 通信与生物医药等前沿领域。
MUSA(Meta-computing Unified System Architecture) 是摩尔线程自研的全功能 GPU 计算加速统一系统架构,涵盖芯片架构、指令集、编程模型、软件运行库及驱动程序框架。
值得关注的是,MUSA SDK 5.1.0 对标 CUDA 12.8,驱动与运行时层兼容接口数达到 761,核心数学库实现 100% 兼容,PyTorch 全算子 (3194 个)100% 覆盖。这意味着全球数百万 PyTorch 开发者几乎无需修改代码,就能把模型迁移到 MUSA 上运行。
另外,在当前最主流的两个大模型推理框架 SGLang 和 vLLM 上,MUSA 都带来了好消息:
SGLang 方面,MUSA 后端正式加入 SGLang 的官方支持体系,相关代码也已成功合入 SGLang 主线。vLLM 方面,MUSA 成为 vLLM 的官方后端,并开源 vLLM-MUSA,开发者可原生获得摩尔线程 GPU 加速能力。
与单纯地多支持了一个框架相比,加入大模型推理框架官方后端矩阵意味着,国产 GPU 在生态适配上拥有更充分、更直接的兼容路径。
此外,摩尔学院平台已汇聚超 45 万名开发者与学习者,合作院校超 200 所。对于一个成立仅六年的公司,这个增长速度确实不慢。但 45 万与 CUDA 数百万级的开发者规模之间仍然存在数量级的差距。
MUSA 的真实挑战在于:依赖兼容 CUDA,它的生态故事永远是一个跟随者。
所以,对于摩尔线程来说,它真正需要建立的是独立、独特的技术体验,让开发者因为 MUSA“ 做某件事更方便” 而选择它,而不是因为它“ 兼容 CUDA”。
高增长的另一面
对于摩尔线程来说,单季净利润转正被市场解读为关键拐点信号—— 但这个信号背后,其实也存在一些隐忧。
此前,摩尔线程在回复投资者提问时,将 2025 年收入高增归因于两层因素:一是 AI 大模型快速迭代、应用扩张,带动 GPU 需求迅速增长;二是高端 GPU 出口限制持续收紧,为国产 AI 芯片打开了替代窗口。
从这个角度看,摩尔线程这轮收入放量,踩中的既是 AI 算力扩张周期,也是国产替代加速的产业机会。
但是,需要注意的是,摩尔线程一季报显示,当期非经常性损益合计 8364 万元,其中计入当期损益的政府补助为 7006 万元,占比约 84%。
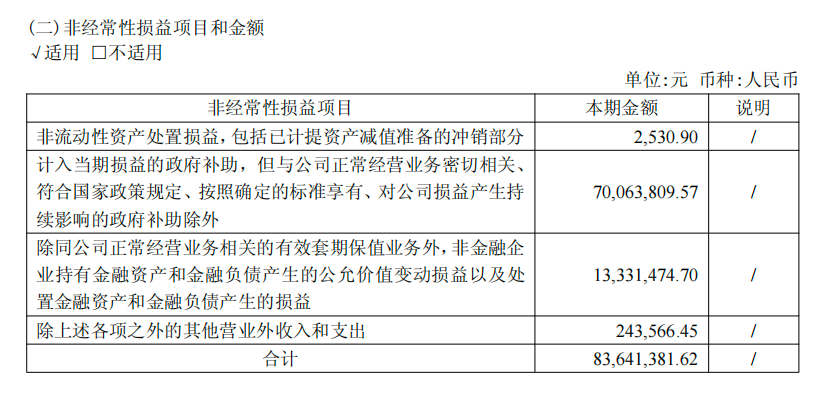
假如剔除上述项目,摩尔线程当季归母扣非净利润亏损 5428 万元,虽然同比收窄 60.1%,但亏损依然存在。
换言之,这次的账面盈利,是通过政府补贴,才越过了关键的盈亏线。当下,摩尔线程的主营业务自身尚未实现收支平衡。
对于摩尔线程来说,真正需要破局的,是能否逐步把收入来源延伸到更广泛的商业客群,需要在两方面同步推进:首先是产品性能和稳定性的持续提升,其次是 MUSA 软件生态的开发者规模扩张。
而从芯片到集群,从集群到软件,从软件到终端,从终端到 Agent,再从 Agent 到具身智能—— 这条链路拉得越长,竞争对手追赶的难度就越大。
回头再看摩尔线程的路径选择可以发现,这并非一条“GPU 公司横向多元化” 的常规商业扩张,而是一家从 GPU 出发的硬科技公司,试图用自己最擅长的算力能力,向下扎到 SoC,向上伸到 OS 和智能体的战略故事。
云端的夸娥集群,解决的是"算力从哪来"的问题。"长江"SoC 和 AICUBE,解决的是"算力到哪去"的问题。MUSA 生态,解决的是"开发者为什么留下来"的问题。智能体"小麦"和具身智能平台 MT Lambda,解决的是"AI 最终以什么形态触达物理世界"的问题。
这四层逻辑环环相扣,拼在一起,是一张从硅片到场景、从训练到推理、从虚拟到物理的完整版图。
把眼光再放长远一点,摩尔线程押注的是一个根本性判断:AI 计算不会永远停留在"训练大模型"这个单一场景里,它终将渗透进每一个终端、每一个物理空间、每一次人机交互。从这个角度来看,摩尔线程从云端向端侧的延伸,并不是一家 GPU 公司的"跨界",而是一次顺势而为的生态升维。
只是,要想最终印证这个判断,摩尔线程需要的不仅仅是时间,也需要一个能够持续造血的商业正循环。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App