Related articles

当全行业都在讨论“ 龙虾”(OpenClaw) 能不能帮你自动干活的时候,腾讯的另一款 AI 产品正在尝试另一条路:不是让你拥有一只更聪明的龙虾,而是让你拥有一个越用越懂你的知识大脑。

今天 (4 月 29 日),腾讯正式上线了 ima 的 copilot 模式。这正是促成这次评测的直接原因:当一款产品宣布从“ 工具” 升级为“ 伙伴”,从“ 跑腿” 进化为“ 贴身助理” 的时候,无论此前印象如何,都值得重新看一眼。
ima.copilot(以下简称 ima),2024 年 11 月上线,定位“ 以知识库为核心的 AI 工作台”。和 WorkBuddy 的“ 桌面 Agent 自动执行” 路线不同,ima 的核心叙事是“ 搜读写一体”—— 把散落的信息变成可查询、可调用的智能资产,再基于这些资产帮你问答、写作、分析。
问题是:一个以知识沉淀为核心的产品,在 Agent 时代真的有不可替代的价值吗?
先坦白一件事:在做这次评测之前,ima 在我的电脑上是一个“ 装了但基本不用” 的应用。我的文档绝大部分沉淀在 WPS 上—— 目前体量将近 28G,ima 的知识沉淀从零开始,此前的写作效果也远不如龙虾类产品和通用 AI 助手,所以它一直处于被冷落的状态。坦白说,此前很多办公工具倡导的“ 构建知识库” 这件事,给我这样一个 C 端用户带来的第一反应不是好奇,而是畏难。
但 copilot 的上线在这次体验中确实改变了这个等式。按照官方定义,copilot 是一种全新的 Agent 模式—— 通过统一入口 (One Agent) 实现跨场景的连续对话与认知统一,核心不是“ 替你操作”,而是“ 替你理解”。它能感知你在浏览网页、阅读文档、整理笔记时的当下行为,无需额外上传即可直接调用,并逐步构建对你工作习惯和知识体系的个性化认知。这和 WorkBuddy 的“ 桌面执行” 路径形成了清晰的分野。
带着好奇心—— 和一个 WorkBuddy 等龙虾类产品深度用户的天然对比视角—— 我决定再给它一次机会。
以下是真实体验。
差点放弃的第一个任务
ima 的上手路径很短。下载电脑端 (Win/Mac),登录,进入对话界面。在使用界面上,相对 WorkBuddy 那种本地环境配置——ima 是云端的,开箱即用。
但第一次打开 copilot 功能时,它又提示我需要构建知识库—— 我差点直接关掉。

转折点来自一次对话。我问 copilot 我没有积累任何知识资产,我应该如何开始,它的其中一个回答,给了我能够继续体验下去的想法。比如,它说可以直接它一个 URL,让它自己抓取内容。我的已发布文章大部分发布在钛媒体官网的个人主页“DeepWrite 秦报局” 上,我把这个 URL 给到了 copilot。
有些惊艳的是,大约几十秒内,它就抓取了主页第一屏的 9 篇文章。到这里,事情已经成功了 80%。

但我想更进一步—— 看看它能不能抓取 2026 年的所有文章。这个任务暴露了 ima 的一个局限:网页翻页操作无法完成。它花了大约 10 分钟到 20 分钟,尝试了各种关键词搜索方式,最终额外找到 5 篇。我的主页 2026 年共发布了 19 篇文章,它找出了 14 篇 (其中第 14 篇似乎归纳错误那篇署名不是我)。另外 4 篇 ima 没有通过搜索找到 (同时以我署名发在其他账号的文章也有不少,但 ima 没有询问我是否把这些纳入其中)。如果执行前先确认一下搜索范围,效率会高很多,类似龙虾执行任务的某个节点先进行确认。

这个任务耗时较长,我一度想暂停但又怕前面的工作白费。这里其实是一个体验优化点:如果 ima 判定任务耗时超出合理范围,应该主动询问——“ 立即输出现有结果,还是继续执行?”—— 而不是让用户陷入“ 停也不是、等也不是” 的尴尬,这也直接导致搜索来源消耗掉足够多的算力,后续成稿算力不足。
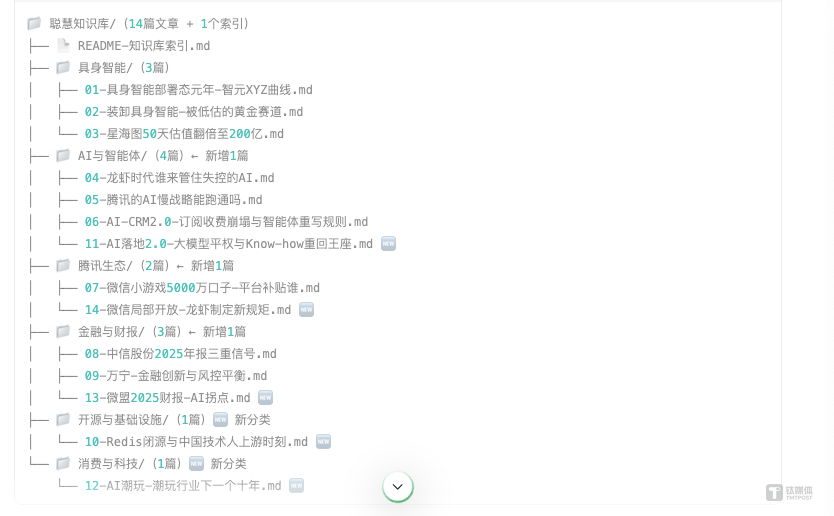
抓取完成后,ima 无法将文章批量添加到知识库,但它提供了一个 14 篇文章的 md 压缩包下载。作为一个“P 人”,看到那个压缩包时脑子里闪过的念头是—— 这个事情好像没那么难。于是我手动完成了上传,顺利建好了一个足以支撑本次评测的知识库。
也是在完成搭建之后,我才真正感受到 ima 和 WorkBuddy 的差异:WorkBuddy 解决的是“ 帮你做”,ima 解决的是“ 帮你懂”。
copilot 到底是什么?
在继续评测之前,有必要交代一下 copilot 这次上线究竟带来了什么。官方将其定位为“Knowledge Agent”—— 不是帮你搬资料的工具,而是真正懂你知识资产的伙伴。具体来说,copilot 具备四个核心能力:
• 自主进化的记忆系统。包含四层结构化存储:copilot 设定 (Soul,即人设)、用户档案 (User)、长期记忆 (Memory)、经验技巧 (Agent)。这意味着你不需要在每次对话中重复输入上下文,它会主动记住你的习惯、偏好和积累。
• 全场景感知。当你使用 ima 浏览网页、文件、知识库或笔记时,copilot 全程伴随。你不需要额外上传文件,直接就能对当前内容提问——“ 这个网页讲了什么?”“ 这份报告的核心结论是什么?”—— 它的感知范围覆盖了你使用 ima 的所有场景。
• 内置增强 Skills。copilot 预装了一组与 ima 深度结合的实用技能:知识库操作 (可读取文件正文,进行跨文件信息汇总)、笔记操作、创建自定义 Skill、生成 PPT、生成报告、浏览器自动化操作。
• 开放生态。支持用户自由配置各大模型的 API Key,通过对话装载其他 Skills。理论上,通过配置可以实现生成视频、制作网页等更复杂的自动化流程—— 不过这部分的实测体验已超出本次评测的范围。
一条值得注意的产品逻辑:ima 强调“ 零门槛”。不需要懂编程,不需要配 API,只要你平时在用 ima 存东西—— 读书、存图、写笔记——copilot 就在侧边自动内化、自动关联、自动变强。官方原话是:“ 以前你存东西是‘ 堆积’,现在你存东西是‘ 投喂’。”
这个设计理念值得肯定。但理念落地到体验,中间还有不少摩擦。接下来的评测会逐一层层剥开。
知识库:ima 的灵魂,也是最大的摩擦点
我把 copilot 搜集到的 2026 年以来的 14 篇文章导入了 ima 知识库,涵盖具身智能、AI Agent、腾讯生态、金融财报、开源基础设施、消费科技六个主题,然后设计了一套五道从浅到深的测试题。
五题四满分,最意外的是“ 跨篇关联”
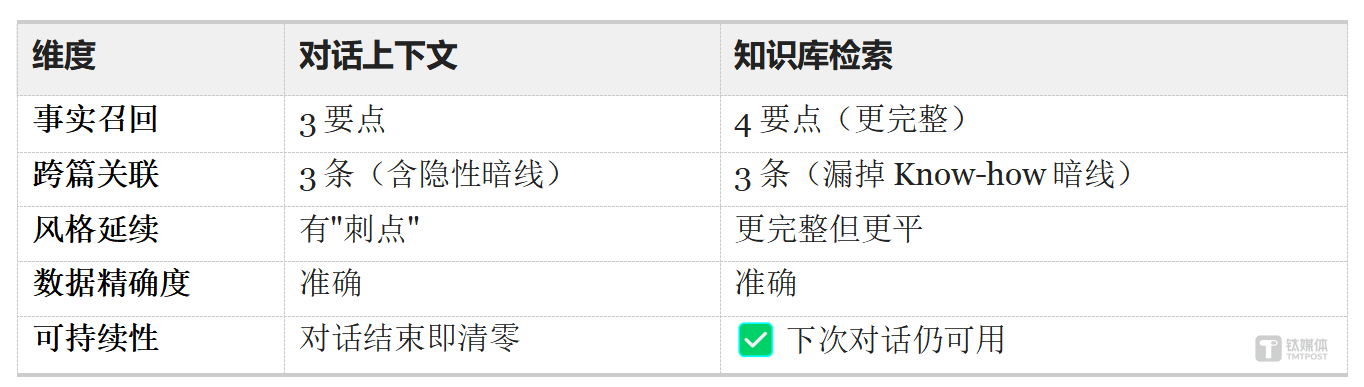
事实召回、精准定位、数据精确度三项,ima 表现扎实—— 比如微盟财报的 AI 收入数据,准确召回了 8 个关键指标 (AI 全年收入 1.16 亿元、下半年 8200 万元、环比增速 137.5% 等),无幻觉。
最让我意外的是跨篇关联题。当问“ 几篇 AI Agent 文章之间有什么交叉洞察” 时,ima 从四篇文章中提炼出三条交叉线索——Agent 安全困境、计费模式重构、行业 Know-how 大于通用模型能力。这种跨篇关联分析,在没有知识库的情况下几乎不可能完成。

这是 ima 最有价值的时刻:它不只是帮你找到信息,而是帮你在信息之间发现联系。
唯一扣分的是风格仿写。ima 能还原我的文章结构和判断句式,但缺少“ 刺点”—— 那个让人一眼记住的戏剧性场景或反直觉收刀。它写出来的东西“ 像” 我写的,但不够“ 是” 我写的。
对话上下文 vs 知识库检索:两种模式,两种答案
做完第一轮测试后,我开了一个新的 ima 对话,用知识库检索的方式重新问了同样的五道题。结果值得展开说。
知识库版本事实更完整(Q1 多出 2 个要点),数据同样准确 (Q5),但漏掉了一条隐性暗线——“ 行业 Know-how 才是真正的壁垒” 这条洞察横跨四篇文章,知识库检索版完全没有发现。这说明知识库检索擅长“ 显性关联”(安全→ 安全),但在语义层面的暗线串联上仍有提升空间。
风格仿写题差异更明显,知识库版本更长更工整,但冲击力偏弱。一句话总结:对话上下文赢在深度关联和风格刺点,知识库赢在持久性和跨对话一致性。
另外,知识库检索会混入平台共享知识库的内容—— 搜索“AI Agent 安全” 时,结果中出现了腾讯云 EdgeOne 等产品介绍。好处是信息更丰富,风险是当你只想要“ 基于我自己的资料” 回答时,噪音就成了干扰。理想状态下,ima 应该提供“ 仅搜索我的知识库” 的开关。
摩擦点:数据从哪来?
ima 支持多种导入方式—— 本地文件、网页链接、公众号文章、微信文件、腾讯文档。但对我来说,核心痛点没解决:我的资料都在 WPS 上,ima 只打通了腾讯文档。生态围墙内很丝滑,墙外还是得手动搬运。
不过,ima 提供了一个值得关注的改进方向:知识库支持以固定链接为知识来源。比如把我的文章主页 URL 设为一个知识库链接,它就可以实时追踪新发布的文章。虽然我没能充分验证效果,但“ 订阅式” 知识更新是一个正确的方向。
写作能力:能模仿结构,但缺“ 现场感”
我让 ima 用我的写作风格写一段关于 AI Agent 安全的开头。结构上确实还原了我的风格—— 场景切入、反共识定义、短句收刀。作为一个科技作者,我的写作动力来自现场的冲击感。ima 能还原结构,但还原不了这种“ 人在现场” 的情绪张力。
不过,如果降低预期—— 让它帮你搭框架、找素材、润色表述—— 效率的提升是实实在在的。在现有素材范围内写作,ima 的风格还原度处于“ 可用” 水平。我让它基于 14 篇文章直接输出评测初稿,约 3200 字,用时约 2 分钟,框架和结构都可用,我只需要补充真实操作感受和现场体验。
把它当作一个读过你所有文章的助理,而不是一个替代你的写手,体验会好得多。
知识管理+AI 辅助并非腾讯一家在做。Notion AI 走“ 文档即知识库” 路线,飞书智能伙伴把 AI 嵌入协同办公全流程,Kimi 以长上下文和联网检索切入知识获取,Perplexity 代表“ 搜索即答案” 的另一种范式。各家路径不同,底层竞争的是同一个问题:如何让 AI 真正理解你的信息。
ima 的切入点是“ 以知识库为核心枢纽,把搜索、阅读、写作串成闭环”。优势在于资产沉淀—— 越用越厚;劣势在于门槛—— 你必须先“ 建库” 才能享受复利。
回到腾讯自家产品线,ima 和 WorkBuddy 的差异不在功能列表,而在产品哲学:
• WorkBuddy 是“ 数字手脚”—— 替你操作,核心价值是执行效率
• ima 是“ 数字大脑”—— 替你记忆和理解,核心价值是认知效率
用我具身智能相关稿件来类比:WorkBuddy 像“ 本体”—— 干活利索但每次任务完成就归零;ima 像“ 大模型”—— 持续学习,越用越聪明,但不直接替你动手。理解在前,执行在后,两者恰好互补。
copilot 的上线强化了这条路线。官方将 copilot 定义为“Knowledge Agent”,强调它不只是“ 帮你搬资料的工具”,而是“ 真正懂你知识资产” 的伙伴。四层记忆系统 (Soul、User、Memory、Agent) 和全场景感知能力的加入,确实让“ 越用越懂你” 从一句口号变成了可感知的产品特性。至少在认知层面,ima 正在走出一条和 Agent 执行派完全不同的路径:大部分 Agent 忙着解决“ 手脚” 的自动化,copilot 聚焦于“ 大脑” 的知识化。
不足与遗憾
1. WPS 等外部生态未打通。腾讯文档一键导入体验好,但这份“ 好” 建立在你是腾讯生态用户的前提下。
2. 跨篇关联的“ 隐性暗线” 盲区。ima 擅长主题词匹配式的显性关联,但语义层面的暗线串联力有不逮。
3. 桌面操作的边界。WorkBuddy 能操作电脑桌面,ima 不能。网页翻页等操作只能通过关键词搜索迂回,完成路径更绕更慢。
4. 风格延续的“ 最后一公里”。能学会你的“ 形”,学不会你的“ 经历”。
谁该用、怎么用
适合谁:有大量资料需要整理检索的人、需要基于自有知识体系深度创作的人、希望把碎片信息沉淀为“ 第二大脑” 的人。
不适合谁:需要 AI 自动操作电脑的人 (WorkBuddy 的强项)、资料主要在非腾讯生态的人、期待 AI 完全替代写作的人。
最佳用法:龙虾的价值在执行效率,ima 的价值在认知效率。认知效率的真正杠杆来自龙虾做不了的事:跨篇关联分析、基于个人知识体系的风格延续、长期沉淀后"越用越懂你"的复利效应。
但飞轮要转起来,前提是摩擦够小。目前 ima 的摩擦点——WPS 未打通、桌面操作受限、检索偶有漏失、算力管理不够灵活—— 都是飞轮上的阻力。
copilot 的上线让 ima 完成了一次关键的定位升级—— 从“ 云端收藏夹” 变成了“ 知识伙伴”,从“ 工具” 变成了“Agent”。这在产品逻辑上是自洽的,方向也值得看好。但当前版本在工作体验上仍有不少摩擦,写作风格还原度处于也算得上够用 (遇到负责任务可能产生较大算力消耗而导致任务中断),期待后续功能完善—— 尤其是桌面操作能力的补齐、算力管理机制的优化—— 成为一款真正好用的办公助手。
当全行业都在追 Agent 的执行能力时,ima 选择的路径是:先让人把知识沉淀下来,再让 AI 基于这些知识为你服务。这条路不性感,但它解决的是一个更底层的问题—— 在信息爆炸的时代,真正稀缺的不是执行力,而是理解力。
龙虾帮你把活干了。ima 帮你把活想明白。
而最好的状态,是左手龙虾,右手知识大脑。
(本文首发钛媒体 APP,作者 | AGI Signal,编辑 | 秦聪慧)
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App