文 | 字母 AI
距离 ClaudeOpus 4.6 的发布仅过去 12 天,Anthropic 就发布了新的中档模型 Claude Sonnet 4.6。
Related articles


这次发布的核心不在于技术突破本身,而在于它以低得多的价格,达到了与竞品齐平的性能。。


Sonnet 4.6 的定价保持在每百万 token 输入 3 美元、输出 15 美元,与前代 Sonnet 4.5 相同。
然而在多项基准测试中,Sonnet 4.6 接近甚至超越了价格高出五倍的 Opus 4.6。
Anthropic 表示,便宜不一定就没有好货。
当然了,在一些关键的测试里,仍然还是 Opus 4.6 领先。
具体表现如何呢?
Sonnet 4.6 究竟有多惊艳?
在 SWE-bench Verified 这个衡量真实软件编码能力的基准测试中,Sonnet 4.6 得分 79.6%,几乎追平 Opus 4.6 的 80.8%,同时略微领先于 OpenAI 的 GPT-5.2。
在代理式金融分析任务中,Sonnet 4.6 以 63.3% 的成绩领先所有竞争对手,包括 Opus 4.6 的 60.1% 和 GPT-5.2 的 59.0%。
在办公任务的 GDPval-AA Elo 评分中,Sonnet 4.6 达到 1633 分,超过 Opus 4.6 的 1606 分和 GPT-5.2 的 1462 分。
过去需要旗舰模型才能完成的任务,现在用 Sonnet 4.6 这种中档模型就能做到。
对于每天需要处理数百万 token 的企业来说,这意味着可以大幅节省成本。
Opus 4.6 仍然在某些高复杂度领域保持优势。
在终端编码任务 Terminal-Bench 2.0 中,Opus 4.6 得分 65.4%,Sonnet 4.6 为 59.1%。
在代理式搜索 BrowseComp 中,Opus 4.6 达到 84.0%, Sonnet 4.6 为 74.7%。
在新颖问题解决测试 ARC-AGI-2 中,Opus 4.6 得分 68.8%,Sonnet 4.6 为 58.3%。
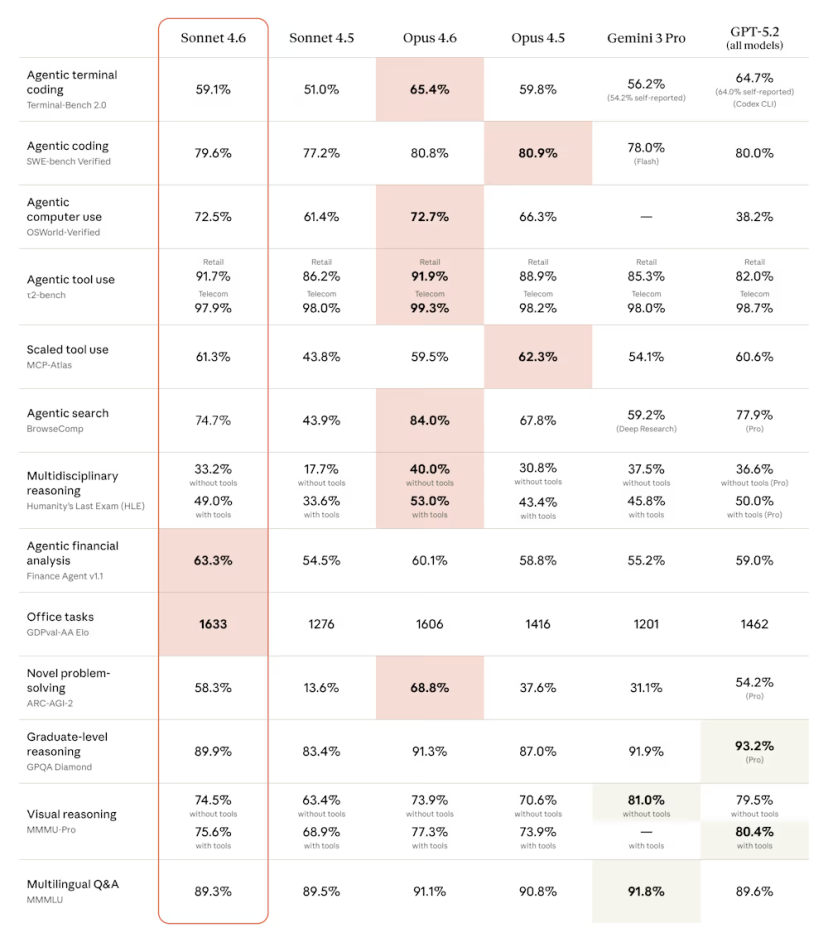
这些差距表明,对于前沿研究和需要顶级准确度的场景,Opus 4.6 仍是最好的模型。但对于大多数生产环境,这个差距已经缩小到可以接受的程度。
Sonnet 4.6 最引人注目的进步出现在计算机使用能力上。在 OSWorld-Verified 基准测试中,它得分 72.5%,高于 Sonnet 4.5 的 61.4%,远超 GPT-5.2 的 38.2%。
计算机使用能力指的是 AI 像人类一样操作计算机的能力,通过鼠标点击、键盘输入来与软件交互,而不依赖 API 接口。
前一阵引发热议的豆包手机助手,其底层的 UI-TARS 模型,就是在 OSWorld 基准上完成了权威测试,取得了 47.5% 的成绩。
豆包手机助手的表现是非常出色的,已经能够完成除了支付以外所有的操作。
那么以此作为判断依据,进而不难推测,Sonnet 4.6 的实际表现将会非常惊艳。
这项能力之所以重要,是因为它打开了最广泛的企业应用场景。
一个能够直接看屏幕并与之交互的模型,可以在不构建定制连接器的情况下,自动操作将所有可交互的系统。
Anthropic 在发布时提到,早期用户已经看到接近人类水平的表现,能够完成复杂的电子表格任务和多步骤网页表单。
保险科技公司 Pace 的 CEO 贾米· 考夫 (Jamie Cuffe) 表示,Sonnet 4.6 在他们复杂的保险计算机使用基准测试中达到 94% 的成绩,是所有测试过的 Claude 模型中最高的。
他说:“ 它以我们之前未见过的方式推理失败原因并自我纠正。”
恶意行为者可能在网页中隐藏指令来劫持模型,这被称为提示注入攻击。
Anthropic 在公告中表示,Sonnet 4.6 在抵御此类攻击方面比 Sonnet 4.5 有重大改进。
对于部署需要浏览网页和与外部系统交互的代理的企业来说,这种安全防护是必须的。
价格只要五分之一
那么 Sonnet 4.6 到底有多便宜呢?
外媒报道,一些早期的 Sonnet 4.6 用户表示,原本企业需要花五倍的钱才能买到的能力,现在用 Sonnet 4.6 就能获得差不多的效果。
这意味着运营成本可能直接降到原来的五分之一,而工作质量几乎不受影响。
数据分析平台 Hex Technologies 的 CTO,同时也是 Anthropic 联合创始人、首席产品官的凯特琳-科尔格罗夫 (Caitlin Colgrove) 说,公司正在将大部分流量迁移到 Sonnet 4.6。
她指出通过自适应思考和高努力模式 (high effort mode),“ 除了最困难的分析任务外,我们在所有任务上都看到了 Opus 级别的性能,且配置更高效灵活。以 Sonnet 的价格,这将降低工作成本。”
云存储公司 Box 的 CTO 本· 喀什 (Ben Kus) 表示,Sonnet 4.6 在真实企业文档的重度推理问答中,比 Sonnet 4.5 的表现提高了 15 个百分点。
Sonnet 4.6 配备了 100 万 token 的超长上下文窗口,以容纳整个代码库、法律文件或数十篇研究论文。
Anthropic 声称模型能够在整个上下文中有效推理,并通过 Vending-Bench Arena 这个基准测试来表现出 Sonnet 4.6 的有效推理。
Vending-Bench Arena 测试的是模型运营模拟企业的能力,不同 AI 模型相互竞争以获得最大利润。
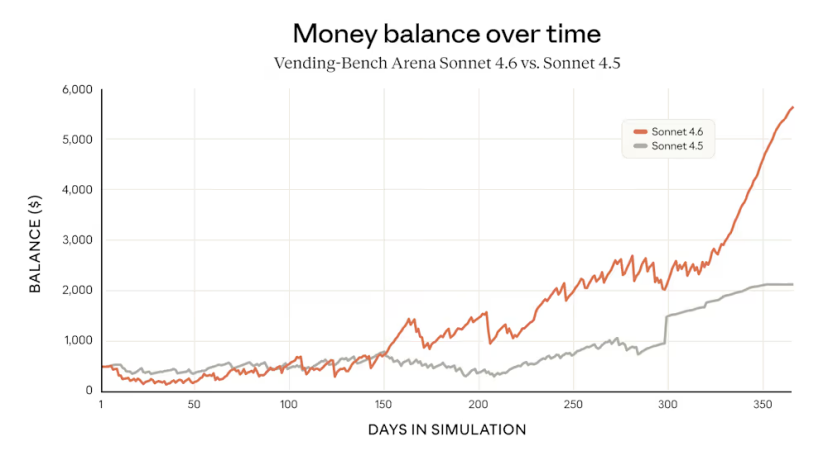
在没有人类提示的情况下,Sonnet 4.6 发展出一种新颖策略:在前十个模拟月份中大量投资产能,支出远超竞争对手,然后在最后阶段急转弯专注于盈利能力。
模型在 365 天模拟结束时的余额约为 5700 美元,而 Sonnet 4.5 约为 2100 美元。
Anthropic 开启印度市场
Anthropic 正处于上市前最关键的阶段,因此他们不止要发布模型,还要借着模型去扩张业务。
在 Sonnet 4.6 发布当天,印度 IT 巨头 Infosys 宣布与 Anthropic 合作,构建企业级 agent,将 Claude 模型集成到 Infosys 的 Topaz AI 平台中,服务于银行、电信和制造业。
与此同时,Anthropic 也在印度的班加罗尔开设了首个印度办事处,印度现在占全球 Claude 使用量的约 6%,仅次于美国。
Anthropic 的进步也导致了最近几天软件股的大规模抛售,就连业绩大涨的微软,也经历了股价暴跌。
投资者越来越担心 AI 对这些业务的潜在颠覆,Sonnet 4.6 可能会加剧这种不安的氛围。
也不知道是不是 Anthropic 飘了,他们还将其免费层级默认升级到了 Sonnet 4.6,开发者可以通过 Claude API 直接调用。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App