Related articles



想象一个场景:你让三个 AI 助手协作完成一道数学题。
传统做法是——第一个 AI 把解题思路 「写」 出来,第二个 AI「读」 完再写新的思路,第三个 AI 再 「读」 再 「写」。
这个过程,就像三个人轮流用对讲机传递信息,每次都要先把脑子里的想法 「翻译」 成语言,对方再把语言 「翻译」 回想法。慢不慢?慢。费不费?费。更要命的是,这种 「翻译」 过程会丢失信息——你脑子里想的,和你说出来的,往往不是一回事。
这就是当前多智能体 AI 系统面临的核心困境:「语言税」。
而最近,UIUC、斯坦福、英伟达、MIT 联合提出了一种新思路——RecursiveMAS。它让 AI 们跳过 「说话」 这一步,直接用 「思维」 沟通。在实测中,推理速度提升了 2.4 倍,Token 消耗削减了 75%。
(研究指路:https://arxiv.org/abs/2604.25917)
AI 开会的困境:效率都浪费在了 「说话」 上
过去两年,多智能体系统已经成为 AI 领域最热门的研究方向之一。从 OpenAI 的 Swarm 到微软的 AutoGen,从 LangGraph 到 CrewAI,各家都在探索如何让多个 AI 协同工作以解决单个模型无法独立完成的复杂任务。然而,在这些系统中,多个智能体的协作效率始终被一个基本假设所制约——智能体之间必须通过自然语言文本来交流。
当你让一个 「数学专家」 和一个 「代码审查员」 协作时,整个流程看起来很 「合理」,但拆解开来会发现问题很多:
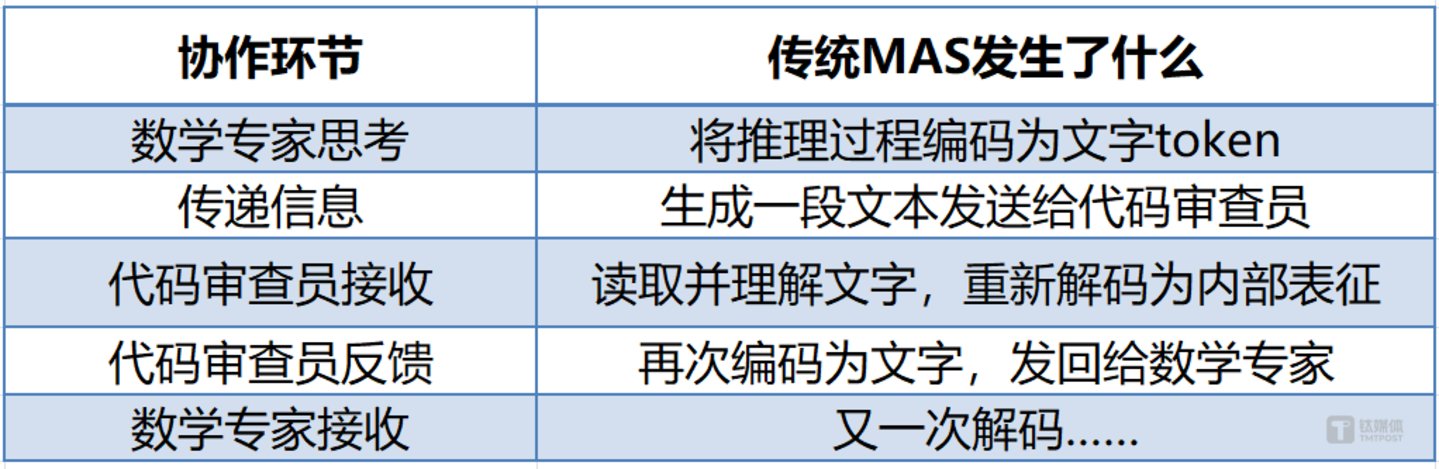
每一次信息传递,都伴随着双重转换:内部思维→文字→内部思维。这个过程消耗的 token 不仅是金钱,更是宝贵的计算资源和时间。更关键的是,这种 「写出来再读进去」 的过程会丢失信息——模型在文本解码时被压缩进文字的丰富语义,下一个模型重新解码时已经无法完全还原。在一个包含五个 Agent 的工作流中,文本编解码的时间开销往往占到总延迟的 60% 以上。
更让人头疼的是,这种范式始终缺乏一个清晰的 「旋钮」 来做系统性优化——增加更多智能体?边际效益递减,且通信开销指数级增长。增加上下文窗口?Token 成本爆炸。增加模型参数?单个 Agent 变强了,但协作效率并没有本质提升——类似于给一群人每人配了更好的对讲机,但他们依然要逐个念文字,沟通方式没变,就算每个人都更聪明了,整体效率也无法有突破。行业内的应对方案,无论是提示词工程还是 LoRA 微调,都只能在一定程度上缓解症状,无法根治这个根本性的架构问题。
RecursiveMAS:用 「心灵感应」 替代 「对讲机」
RecursiveMAS 的核心思路非常巧妙:既然语言是瓶颈,那就不用语言。
它借鉴了递归语言模型 (Recursive Language Model) 的思想。在传统语言模型中,数据从第一层流向最后一层,线性前进,层数越多,参数越多;而递归语言模型反其道而行——不增加层数,而是把同一组层反复循环使用,让数据在层之间来回 「打转」。数据每经过一次这组层,就相当于多了一轮 「思考」,推理深度得以加深,但参数量却不需要增加。
RecursiveMAS 把这个思路从 「单模型内部」 扩展到了 「多智能体系统」:
每个智能体就像递归语言模型中的一层,它们不再生成文字,而是传递 「思想」——一种连续的、存在于潜空间 (latent space)中的向量表征。
研究者们用了一个诗意的比喻:「agents communicating telepathically as a unified whole」——智能体们像心灵感应一样作为一个整体协作。
具体来说,Agent A1 处理后把自己的隐表征传给 Agent A2,A2 处理后再传给 A3……直到最后一个 Agent 处理完,其隐输出又被直接回传给 A1,开启新一轮的递归迭代。整个过程完全在隐空间中进行,只有到了最后一轮的最后一个 Agent,才将最终的隐表征解码为文本输出。这就好比一群专家围坐一桌,不用说话,不用写笔记,每个人只需默默思考,然后直接把自己脑中的 「思维成果」 传给下一个人——整个过程既安静又高效。
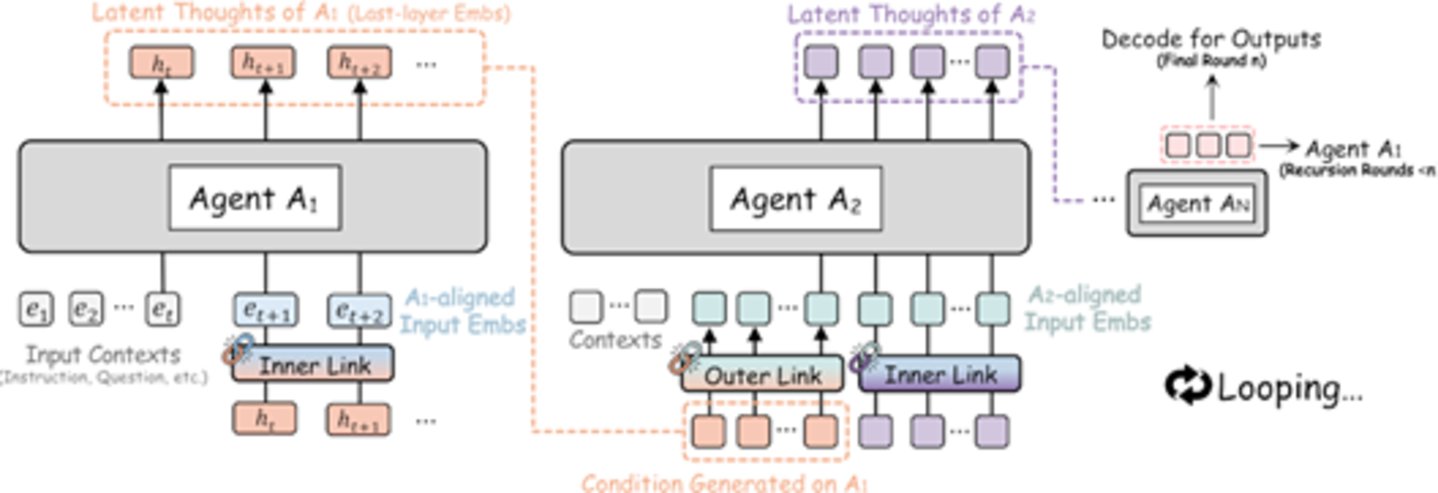
图:RecursiveMAS 架构示意——多 Agent 通过嵌入空间实现闭环递归协作 (来源:arXiv)
这个系统的关键组件叫做 RecursiveLink,一个轻量级的两层残差模块,负责把一个模型的隐层表征保留并转换,然后传递到下一个模型的嵌入空间。语言模型最后一层的隐状态,实际上已经编码了丰富的语义推理信息,RecursiveLink 要做的,就是把这些高维信息完整地 「搬」 过去,而不是先翻译成文字再解读。它分为内外两个版本:

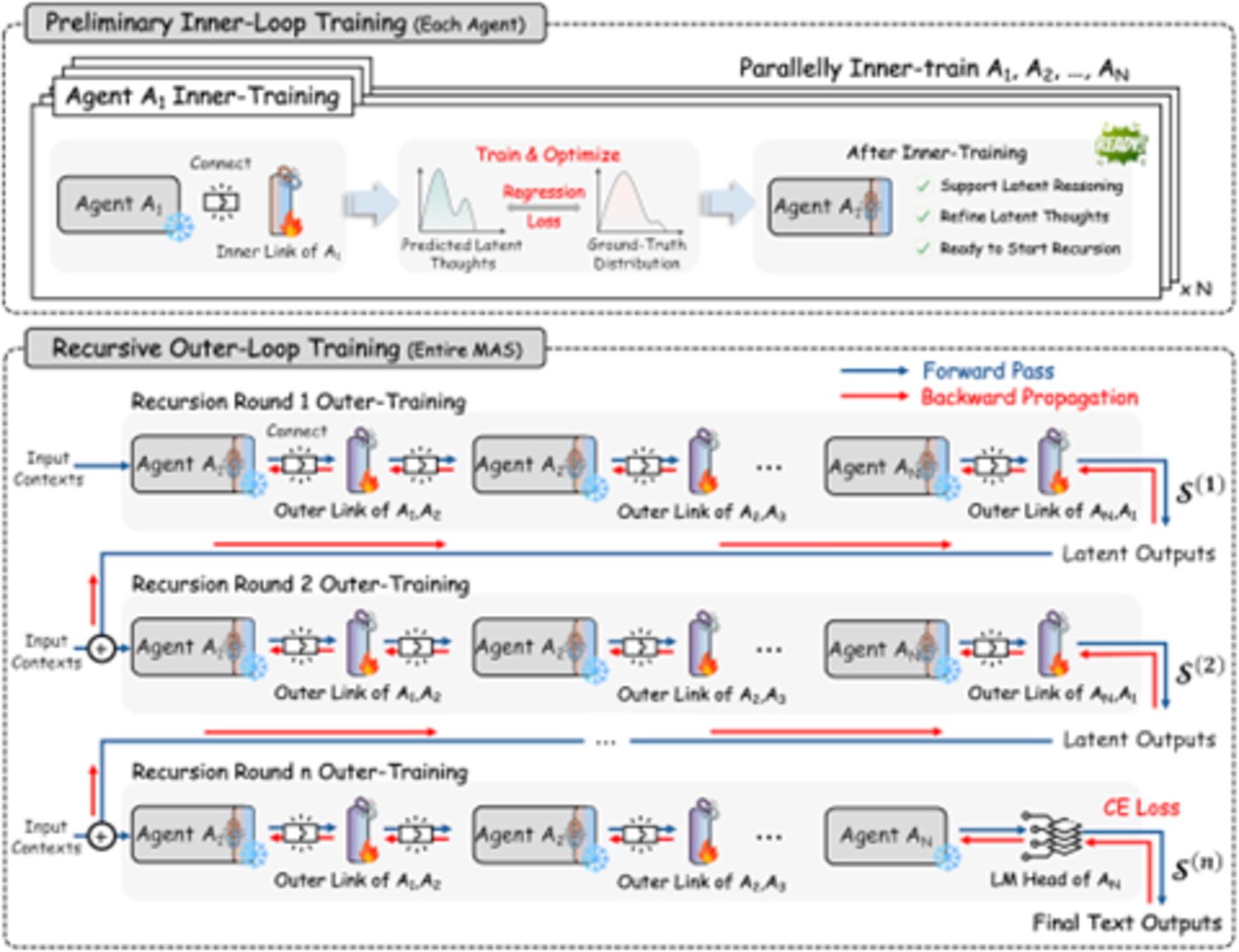
图:递归学习过程——内部链接与外部链接协同训练 (来源:arXiv)
训练策略上,RecursiveMAS 有一个精妙的设计:主干模型权重完全冻结,只需训练 RecursiveLink 模块。这和 LoRA(低秩适配) 的精神有相似之处,但 RecursiveLink 更轻量:整个系统只需更新约 1300 万个参数,仅占总可训练参数的 0.31%。峰值 GPU 显存需求在所有对比方法中最低,训练成本比全量微调降低 50% 以上。你可以把它理解为一个 「轻量级转接头」,直接插在现有 Agent 生态上,无需从头训练新模型。如果多个 Agent 基于同一个基座模型 (比如都用 Qwen),它们甚至可以共享同一份模型权重,进一步节省显存。
训练分两阶段进行:
内层循环热身: 各个智能体独立训练自己的 Inner RecursiveLink,让它们学会在潜空间里 「想问题」 而不是 「写问题」。这个阶段可以并行进行,就像让每个人先练习 「内心独白」。
外层循环训练: 将所有智能体串联成完整的递归链路,以最终文本输出质量为优化目标,通过共享梯度联合优化所有 RecursiveLink。这个阶段解决的是 「credit assignment」 问题——如何把最终结果的成败,准确归因到每个 Agent 的贡献。这种分阶段策略避免了 「一步到位」 可能带来的训练不稳定问题。
研究者们在理论上证明了递归训练的梯度能够保持稳定,不会出现 RNN 中常见的梯度爆炸或消失问题,同时在运行时复杂度上也优于传统文本型 MAS。
实测效果:精度、速度、成本 「三杀」
理论说得再好,终归要用数据说话。研究团队在涵盖数学、科学与医学、代码生成、搜索问答等领域的 9 个主流基准测试和 4 种协作模式 (顺序推理、混合专家、知识蒸馏、协商式工具调用) 上进行了全面评估。实验使用的开源模型阵容相当 「豪华」——Qwen、Llama-3、Gemma3、Mistral,这些模型被分配了不同角色,组成了多种协作模式。
对比基线阵容同样硬核:LoRA 微调、全量微调 (SFT)、Mixture-of-Agents、TextGrad、LoopLM,以及使用相同递归循环结构但强制文本通信的 Recursive-TextMAS。最后这个对照尤其关键——它证明了 RecursiveMAS 的优势确实来自 「跳过文本解码」,而非来自递归结构本身。所有对比都在相同训练预算下进行,公平公正。
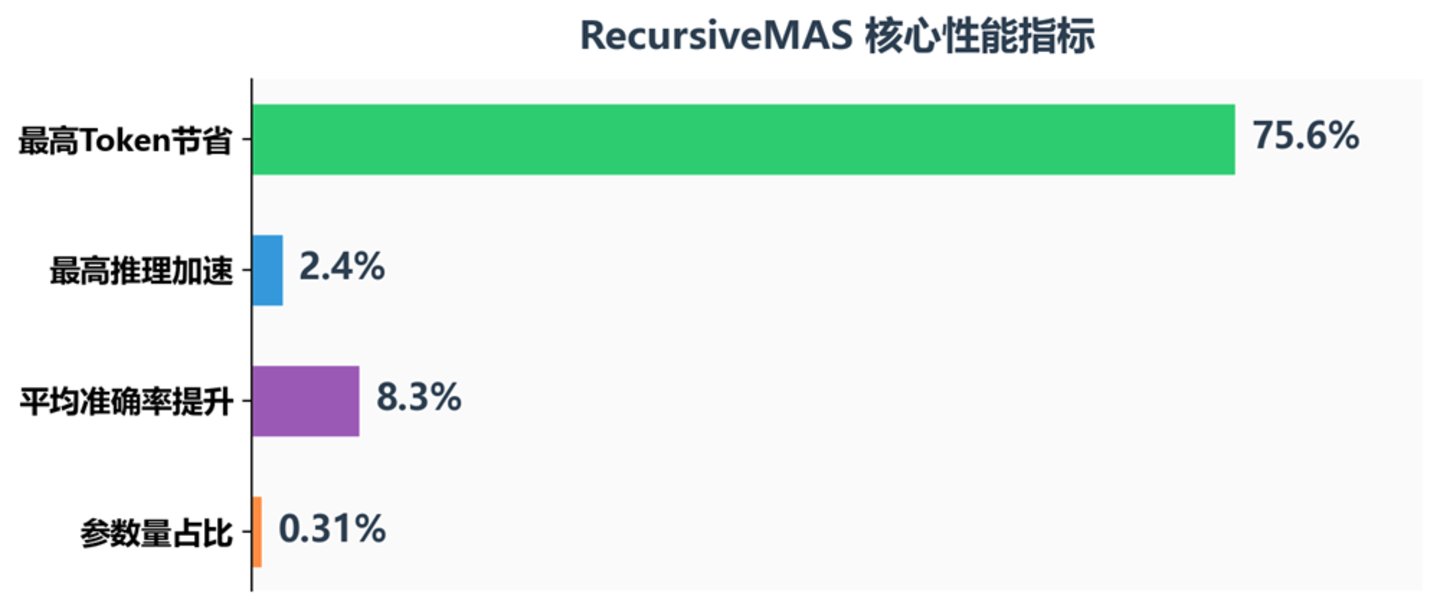
RecursiveMAS 核心性能指标
结果显示,RecursiveMAS 在所有指标上都实现了一致性提升:
精度: 平均准确率提升 8.3%,在 AIME2025 数学竞赛上比 TextGrad 高出 18.1%,在 AIME2026 上高出 13%。跳过文本解码不仅没有损失信息,反而让模型保留了更丰富的隐层语义——毕竟,把思维压缩成文字再解压,这个过程中信息的损耗远比我们想象的大。
速度: 端到端推理速度提升 1.2 倍至 2.4 倍,且随递归轮次增加而持续增长。这对实际应用场景意义重大:在需要实时响应的 AI 客服或代码辅助系统中,2 倍以上的速度提升意味着用户体验质的飞跃。
成本: 与 Recursive-TextMAS 相比,Token 消耗降低 34.6% 至 75.6%。这不仅仅是成本的节省,更意味着在相同 token 预算下可以尝试更深层次的推理。
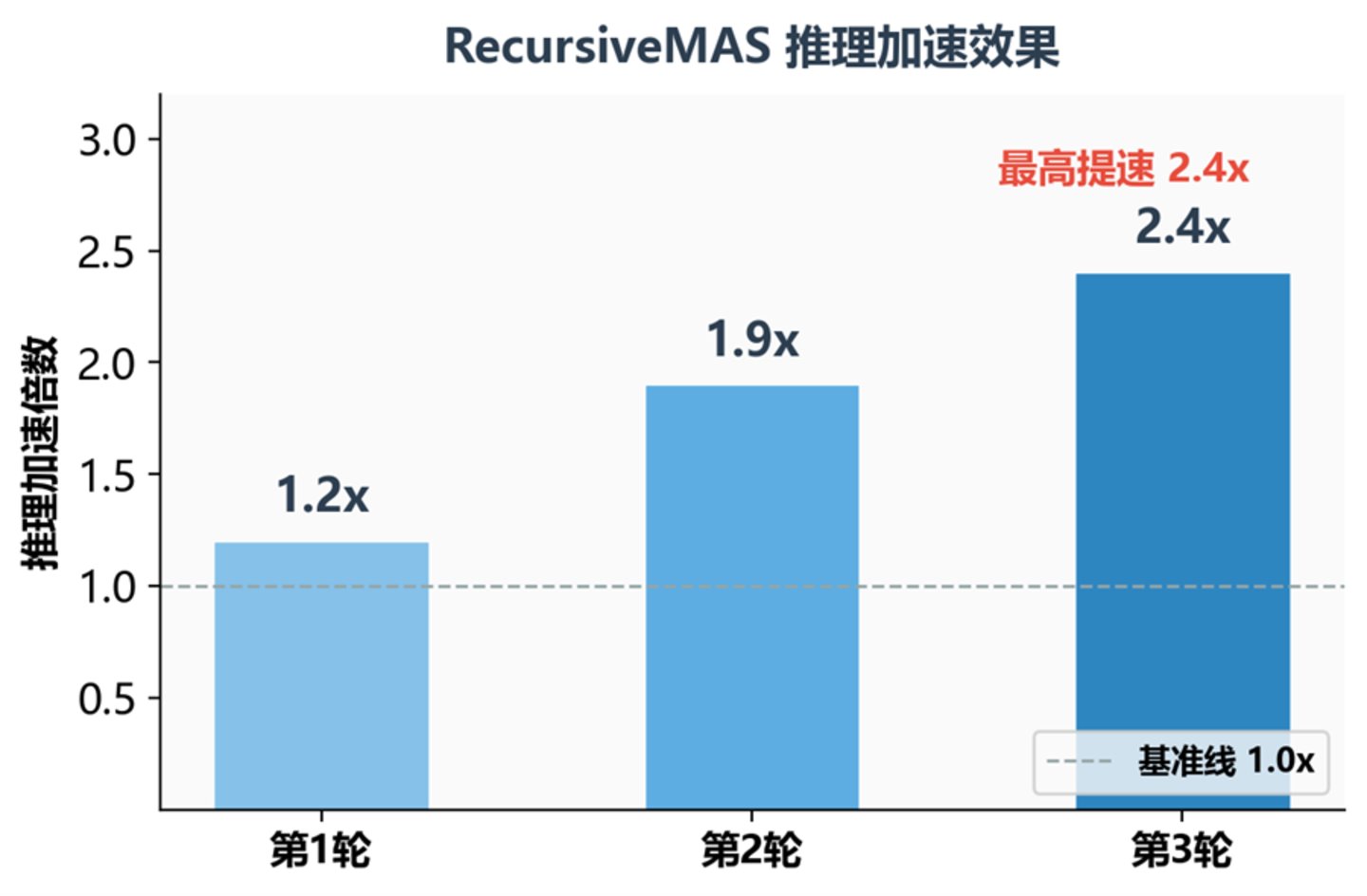
不同递归轮次下的推理加速倍数
这里有一个关键洞察:递归深度越大,收益越高。加速效果随递归轮次增长:第 1 轮平均 1.2 倍,第 2 轮 1.9 倍,第 3 轮 2.4 倍。原因很简单——省掉的是每个 Agent「把想法写成文字」 的时间,Agent 越多、轮次越多,省的时间就越多。
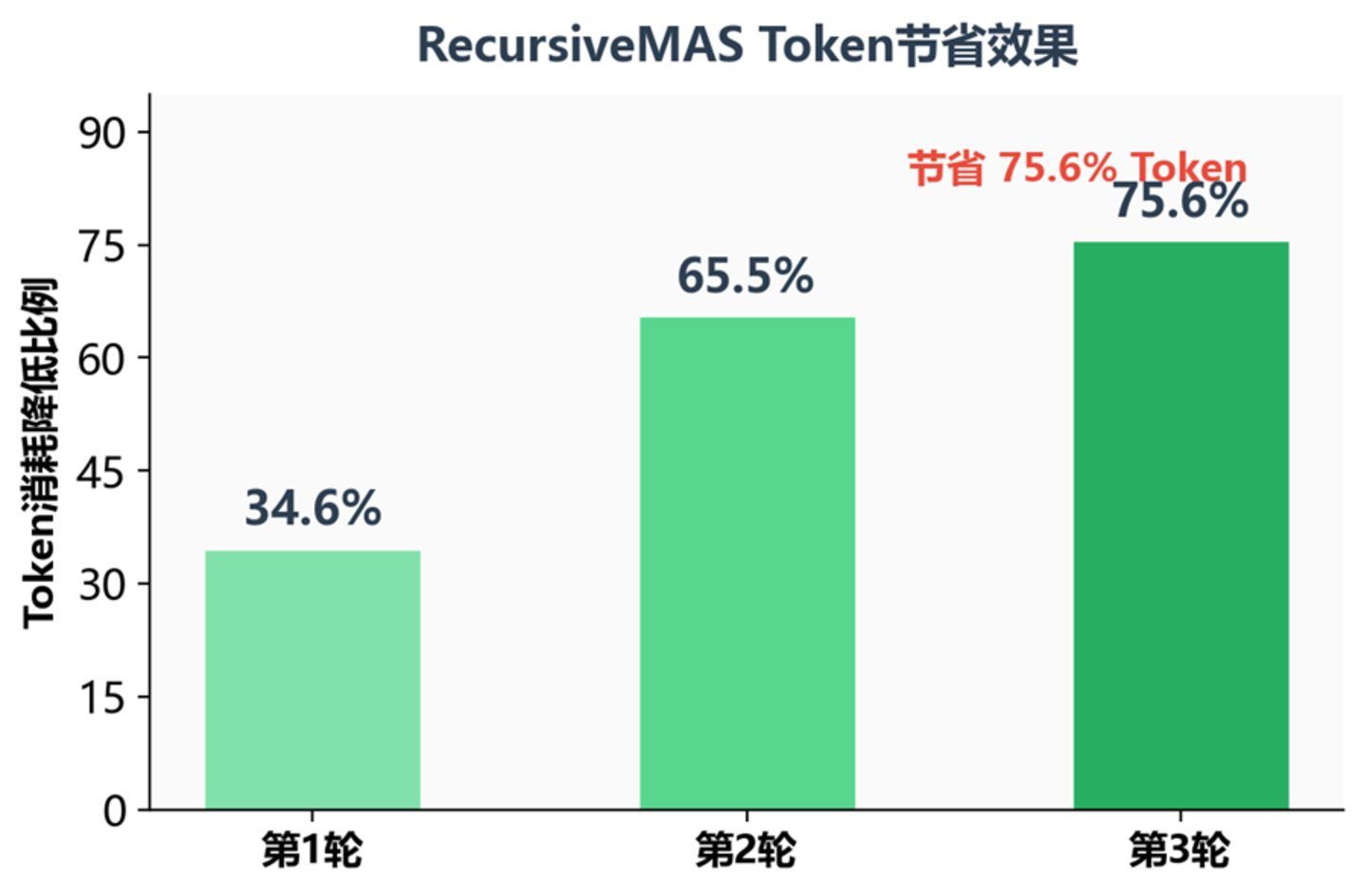
不同递归轮次下的 Token 节省比例
在第三轮递归时,Token 消耗降低了 75.6%——这意味着同等性能下,运行成本可以压缩到原来的约四分之一。对于需要复杂多步骤推理的生产环境,这无疑是巨大的吸引力。
为什么这项研究值得关注?
如果只是数字上的提升,这篇论文或许还不足以引起如此关注。真正让它值得关注的,在于它可能重新定义多智能体系统的 Scaling 方向。
过去几年,多智能体领域的 Scaling 尝试主要围绕三条路:增加智能体数量、扩大上下文窗口、堆叠更大模型。但这些方法都面临各自的瓶颈——智能体多了通信爆炸,窗口大了成本爆炸,模型大了训练爆炸。
RecursiveMAS 提供了一条新路:加深递归深度。它把 「多智能体协作」 从并行的、文本交互的范式,转化为深度的、潜空间递归的范式。就像递归语言模型通过反复处理同一个问题来深化推理,RecursiveMAS 让多个智能体能够反复 「推敲」 彼此的 「想法」,而不必每次都 「说出来再听回去」。
研究者们在论文中提出的核心问题是:「智能体协作本身能否通过递归来扩展?」 答案似乎是肯定的。
当系统不再需要把内部表征 「翻译」 成人类可读的中间格式时,协作效率的上限就有望被进一步打开。
当前的行业背景也为这项研究提供了切实的落地场景。百度 2026 开发者大会以 「万物一体 (Agents at Scale)」 为主题,Anthropic 推出 Claude Managed Agents,OpenAI 持续推进 GPT-5 级推理的实时化——整个行业都在寻找让 Agent 协作从 demo 走向生产环境的方法。而三座大山——计算成本、推理延迟、显存限制——恰恰是 RecursiveMAS 试图用 0.31% 的参数开销来撬动的。
当然,这项研究目前仍处于早期阶段,有几个问题值得关注:
数据可信度待验证。 目前的结果均为作者自报,尚未有独立团队完成复现。学术圈对新技术的态度往往是 「大胆假设,小心验证」。在这个 「论文爆炸」 的时代,独立复现是检验技术真实价值的最佳方式。
异构智能体的兼容性。 Outer RecursiveLink 虽被设计用于连接不同架构的模型,但论文未详细披露跨架构传递潜表征的细节。如果只能用于同构智能体,其实际应用范围将大打折扣。毕竟,真实场景中很多时候我们需要混合使用 GPT-4o、Claude 等闭源 API。
可解释性下降。 当 Agent 之间传递的不再是可读的文本,而是一堆向量表征时,整个协作过程变成了 「黑箱」。在需要对 AI 决策负责的生产环境中,这种不透明性可能带来合规和审计挑战。
生产环境的复杂性。 论文测试的是相对干净的协作场景,真实生产环境往往涉及外部工具调用、人机交互、动态工作流等复杂因素。
RecursiveMAS 的提出,本质上是将 「递归」 这一在单模型时代被证明有效的 Scaling 策略,引入到了多智能体时代,挑战了 「智能体之间必须通过自然语言传递信息」 这一默认假设。如果数据可复现,MAS 赛道下一阶段的 Scaling 轴可能要从 「堆智能体数量」 转向 「加深递归深度」。
当然,这项研究仍需在更多独立基准上验证,需要解决异构模型互联的问题,需要在真实生产环境中证明自己。但至少,它让我们看到了一个可能性——
AI 智能体之间的协作,可以不必总是 「鸡同鸭讲」。
((本文首发钛媒体 APP,作者 | 硅谷 Tech_news,编辑 | 焦燕))