(本文作者为 有界 UnKnown,钛媒体经授权发布)
Related articles


文 | 有界 UnKnown,作者丨钱江,编辑|山茶
今天,一则折叠的聊天记录,又引爆了 AI 圈。
起因是网友发现了一款名叫 HappyHorse-1.0 的新视频生成模型,它不仅强,还很神秘。
强是因为,它能在 AA 排行榜 (全称 artificialanalysis.ai) 上超越 Seedance2.0,成为全球第一。
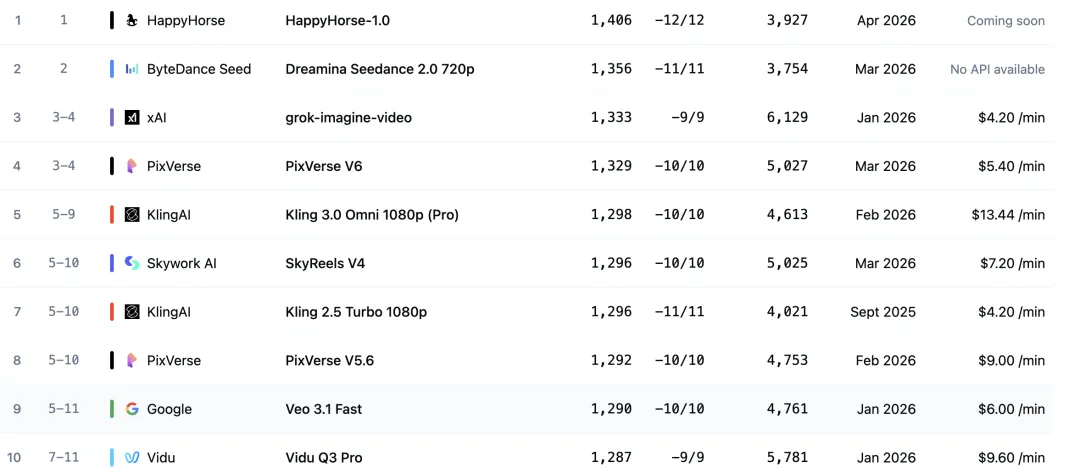
而神秘的是,目前没有人认领这款模型,其官网上也没有任何与其身份相关的标识。
很多人看到这个模型,都不自觉问出曹操那句名言:"我原本以为吕布已经天下无敌了,没想到有人比他还勇猛!这是谁的部将?"

于是,猜测 HappyHorse-1.0 的归属,成为今天行业里最热闹的话题。
当然,「有界 UnKnown」 也积极冲到了吃瓜前线,而我们在吃瓜过程中却发现,HappyHorse 不仅在能力上很突出,它爆火出圈这件事情,也充满了人为操作的痕迹。
一切,可能都是一场精心设计的局。

HappyHorse,厉害在哪里?
作为横空出世的黑马,HappyHorse1.0 自然有其厉害的地方,我们先说这个。
首先,和主流视频模型不同,HappyHorse 是开源的。
其次,它的参数仅有 15B,比大多数模型都小,且 8 步即可完成超快推理 (256p 仅需 2 秒,即使是 1080p 也只需约 38 秒),正式上线时间在 4 月 8 日凌晨。

它主打的优势主要落在两点:生成速度快,以及优秀的音频能力。
首先,是成速度很快。
在已有案例中,仅用一句提示词和一张图片,约一分钟即可生成完整视频。流传的微信聊天记录中,还也特意狠狠踩了一下即梦。
当然,生成速度快的背后,可能是用户数还不多,所以不需要排队。
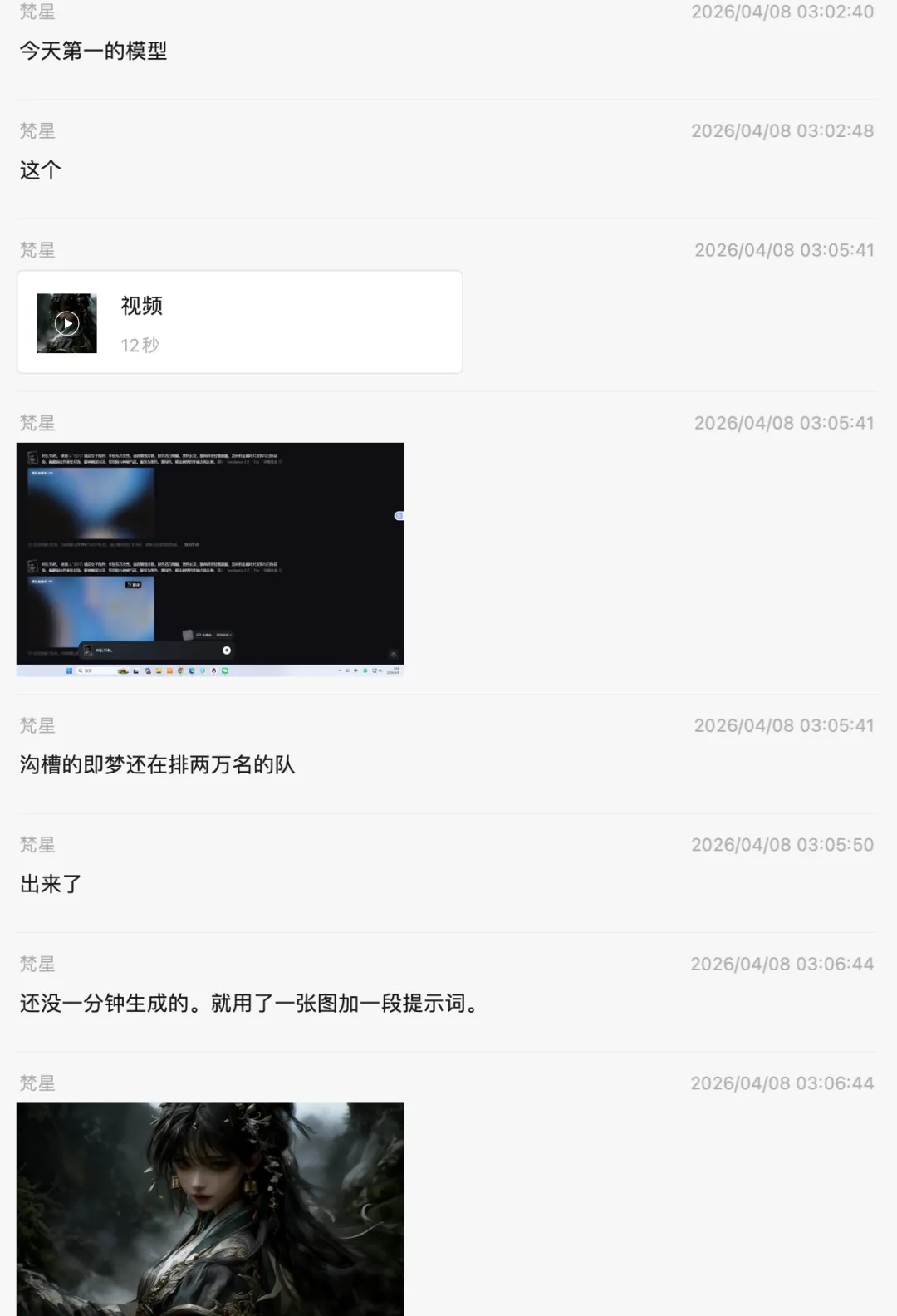
其次,在音频上的能力,HappyHorse 也相对多数视频模型有更明显的进步。
第一,是环境音的匹配。
在 HappyHorse 的案例中,当脚踩到冰面上的时候,可以听到“ 嘣” 得一声;当篮球进入投篮框的时候,会发出和框碰撞的声音;咖啡师倒牛奶时,也能生成倒牛奶的声音。
而之前许多 AI 生成的视频,都容易出现音画不同步,不匹配的情况。
更重要的是,HappyHorse 的声音并不是简单叠加的背景音,而是与画面中的动作形成了基本一致的对应关系。换句话说,声音开始成为“ 视频的一部分”,而不是后期补上的效果。
第二种是 HappyHorse 语言能力。

输入提示词后,模型可以直接生成对应语种的语音内容。根据官网信息,目前主要支持的语言是普通话、粤语、英语、日语、韩语、德语和法语。
最后,是在价格上。
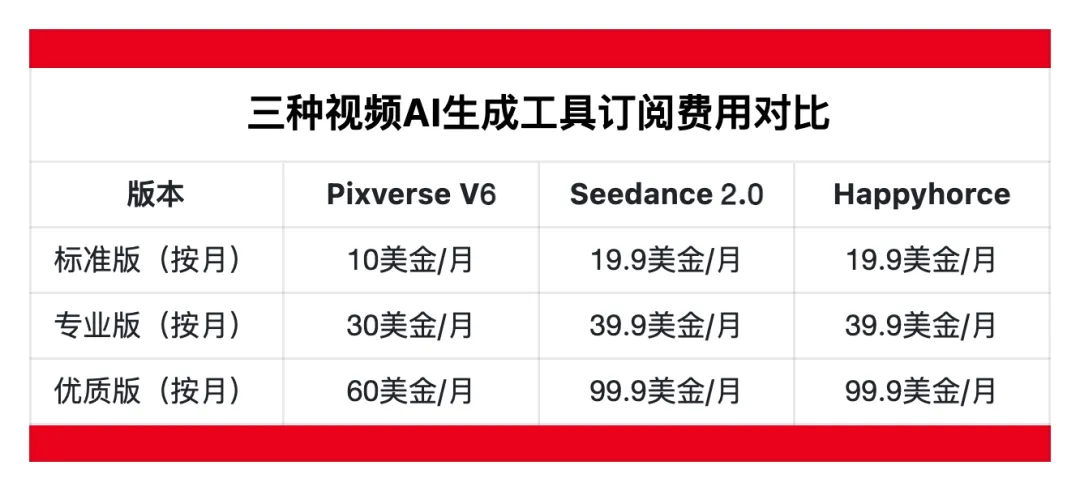
HappyHorse 采用的是积分制,提供按月、按年以及按需三种付费方式。
虽然网络上大家都在说它的价格比 Seedance 2.0 便宜一半,但实际上几乎是照着 Seedance 2.0 订阅价格设置的,比 Pixverse V6 定价也更高,并没有价格优势。
而这些,都让 HappyHorse 成为讨论热点。
人造的“ 黑马”?
虽然关于 HappyHorse 的大多数的讨论都是自然发生的,但种种迹象表明,从故意隐藏信息制造讨论话题,到扔出折叠的聊天记录曝光,引起讨论,这完全可能是一场人为的,精心设计的传播。
首先是榜单,一位在 AI 视频企业工作的朋友表示,AA 的排行榜是可以操作的,只要有预算,他们可以提前给到题目,在这个基础上针对性优化样本的话,拿到高分很容易。
而 HappyHorse 悄悄登顶,又快速撤下,现在市场流传的都是截图,这也给这个猜测制造了基础。
特别是在几乎一边倒的赞扬声之中,X 也有一些网友表示,从生成的效果来看,真人感比较弱,所以也有可能 Happyhorse 的榜单是刷来的。
比如,有 X 网友发现,官网公布的 demo 虽然画面不错,但在物理性上表现有一些差距。比如在呈现快速运动时,仍然存在 AI 运动伪影,尤其是一些带有条纹、线条的物体。
其次,HappyHorse 因 AA 榜单登顶而火,前后不过两天,其官网已经有完整的、关于为什么火的蹭热点的展示,效率真的很高。
第三,目前全网流传的素材十分单一。
「有界 Unknown」 试图付费测试一下视频,但多次尝试之后没有打开,其给到的免费积分不足以支持测试。
而现在网上流传的视频也十分单一,与之前在微信群里,通过折叠聊天记录传播的内容基本一致,而没有新的,更多的视频内容。
这就很有意思了,当全网都在说它比其他模型牛逼的时候,证据却只有官方给到的视频案例,确实有点意思。
而有趣的是,这个聊天记录里,明里暗里地对标友商,突出对比,制造话题,不知道友商现在什么心情。
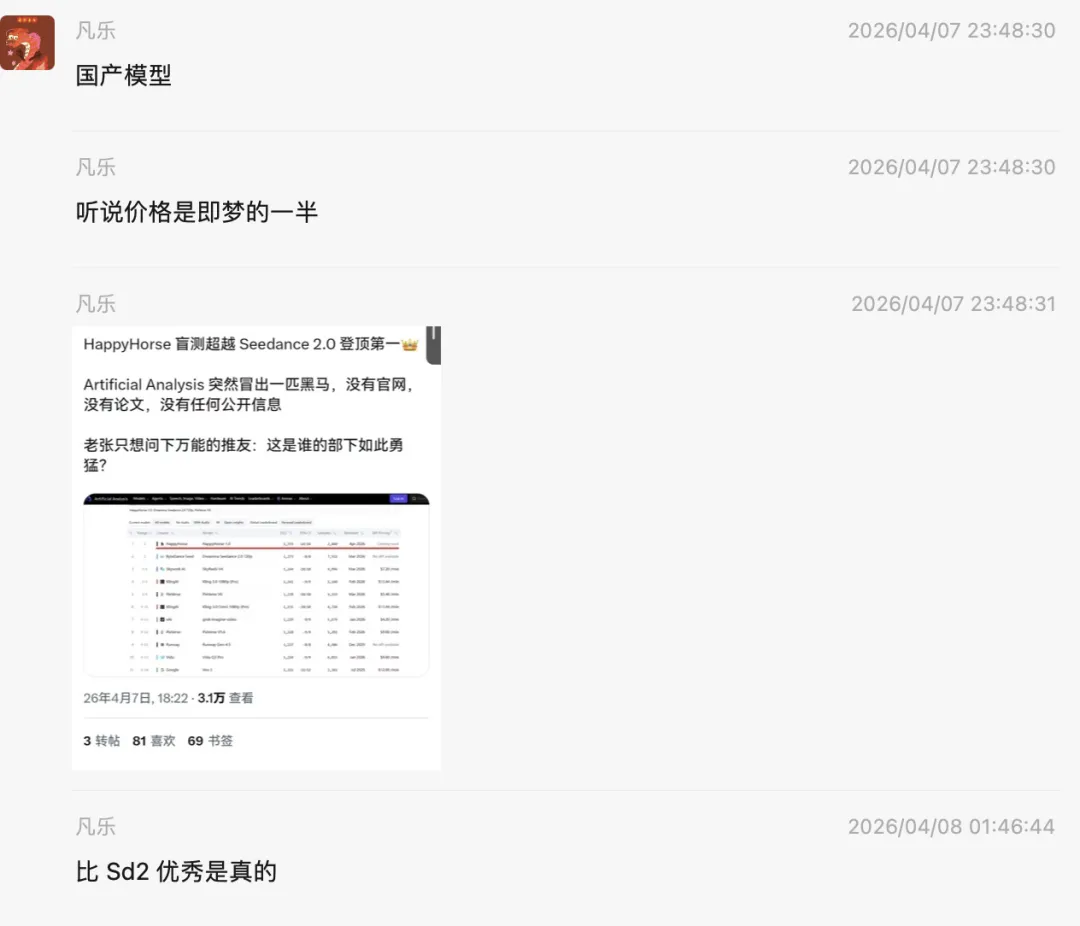
当然,这一切也都瑕不掩瑜。
退一万步来讲,即便这是一波精心策划的营销,但只要产品本身能打,剩下的一起都不是问题。
HappyHorse 带来了什么?
事实上,HappyHorse 真的带来了一些新的东西,一种新的技术范式。
现在主流的视频生成模型,基本采用的方式都是先把视频压缩,再交给 Transformer 去一点点“ 去噪生成”。
而不同的企业在具体的操作上也有不同。
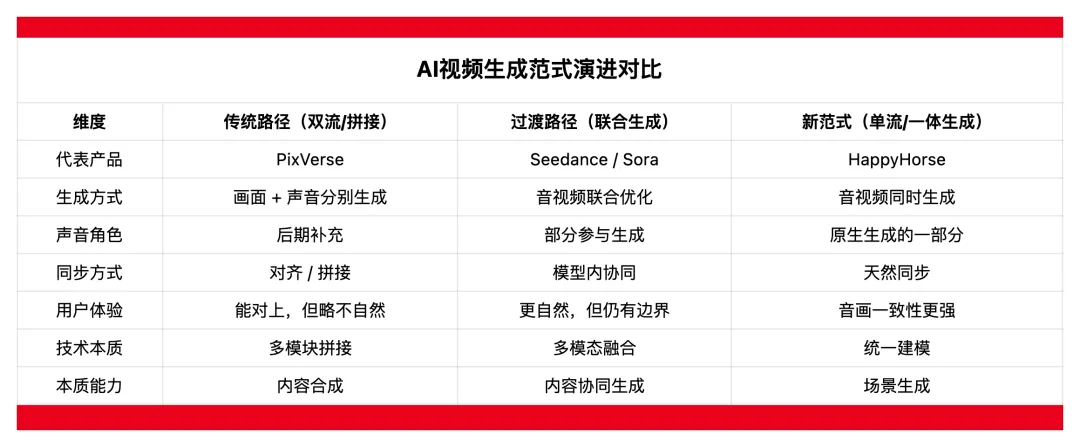
比较传统的方式,也是现在的主流方式,是视频和音频先分开处理,再融合,如 HunyuanVideo、PixVerse、早期的 seedance1.0 都是如此,它们会先把文本、视频,或者空间、时间分开处理,后面再合到一起。
剑走偏锋的方式的是优先提速,比如以色列的公司 Lightricks 开发的 LTX,其重点不是结构多复杂,而是先把视频压得更狠,让 token 变少,这样生成更快。
而未来,行业逐渐演变的趋势是:一套大主干统一生成。
过去,先分开处理,再融合的方式,在技术上,这通常被称为“ 双流 (two-stream)”。
画面和声音分别由不同模块生成,最后再通过对齐机制拼在一起。这也是为什么,在很多情况下,音画虽然能够对上,但仍然会有一丝不自然—— 因为它们从一开始就不是一起生成的。
而现在的一套大主干统一生成,则趋向于“ 单流 (single-stream)” 生成方式,即把画面和声音作为同一生成过程中的不同部分,一起完成。
也就是说,声音不是后加的,而是和画面一起“ 长出来” 的。
这一差异,可以从具体效果中看到。比如脚踩冰面的破裂声、篮球入框的碰撞声,这些声音不是简单叠加,而是随着动作同步出现,具有明显的因果关系。
现在市面上最新的模型如 Sora、Veo、Seedance2.0 都在向这方面靠拢,这也是目前的技术方向。
HappyHorse 采用的就是这个方向,但它做得更激进,更强调“ 全部放在一起统一处理”。(起码在他们官网上是如此宣称的)
这具体表现在:
1、结构上更统一,强调单流、无 cross-attention;
2、模态上更统一,不仅文本和视频一起处理,连音频也想一起纳入;
3、推理上更激进、8 步生成、强调低延迟,速度快。
用更直白的话说,视频生成的效率更高了,如 seedance 排队的情况可能会变少。一致性更好了,音话不同步,口型不同步,动作还得时序等问题都能有较好的提升。
HappyHorse 是谁的部将?
Happy Horse 之所以出圈,一半因为能力,另一半则是因为神秘。
关于它的“ 身份”,网上几乎没有给出任何有效信息。其官网的介绍也极为克制,只留下一句:“Happy Horse 1.0 由 Happy Horse 团队开发”。
HappyHorse 越神秘,大家越好奇,于是大家都在互相打听,HappyHorse 究竟出自哪里,市面上也很快出现了多个猜测。
目前最被大家相信的,是来自张迪领衔的淘天集团未来生活实验室。张迪此前曾负责快手 Kling 项目,再往前,则是阿里妈妈大数据与机器学习工程架构负责人。

关于这个来源,目前有很多信息,有一些自媒体还做出了报道,但官方还没有肯定,也没有权威信息来源。
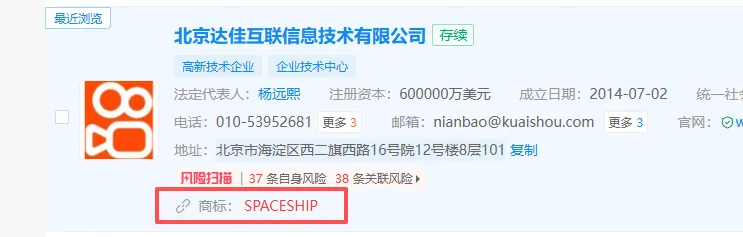
在此之外,最开始被怀疑的,是快手系。
有人注意到,官网留下的了 spaceship.com相关痕迹,而“spaceship” 恰好与快手关联公司商标重合,因此推测该项目可能出自快手。
第二个被怀疑的,是腾讯系,或者 Grok(因为都跟马有关)。
事实上,我们之前怀疑是爱诗,但沟通后对方否认了这件事情,并反向猜测可能与腾讯有关。我们后来在 X 上也找到了一些蛛丝马迹,微信曾在去年 8 月于 X 上发布过一条帖子,刻意提及 “HappyHorse” 关键词。
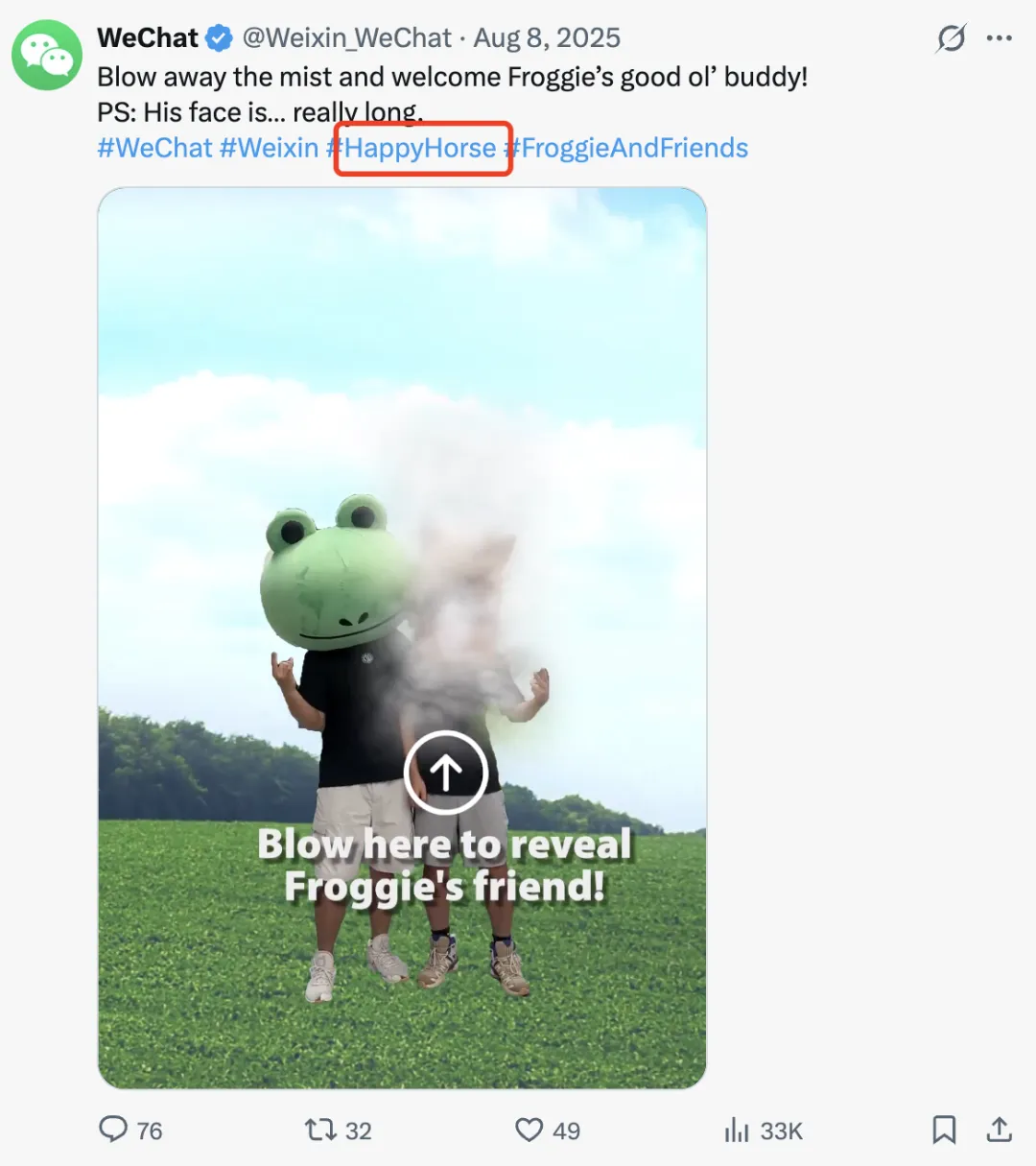
在此之外,还有一些更“ 轻量” 的猜测:比如来自阿里 WAN 2.7,因为名字有 horse(马),所以和“ 马 (云)” 有关;还可能是 Minimax,理由是他们“ 喜欢用动物命名”。
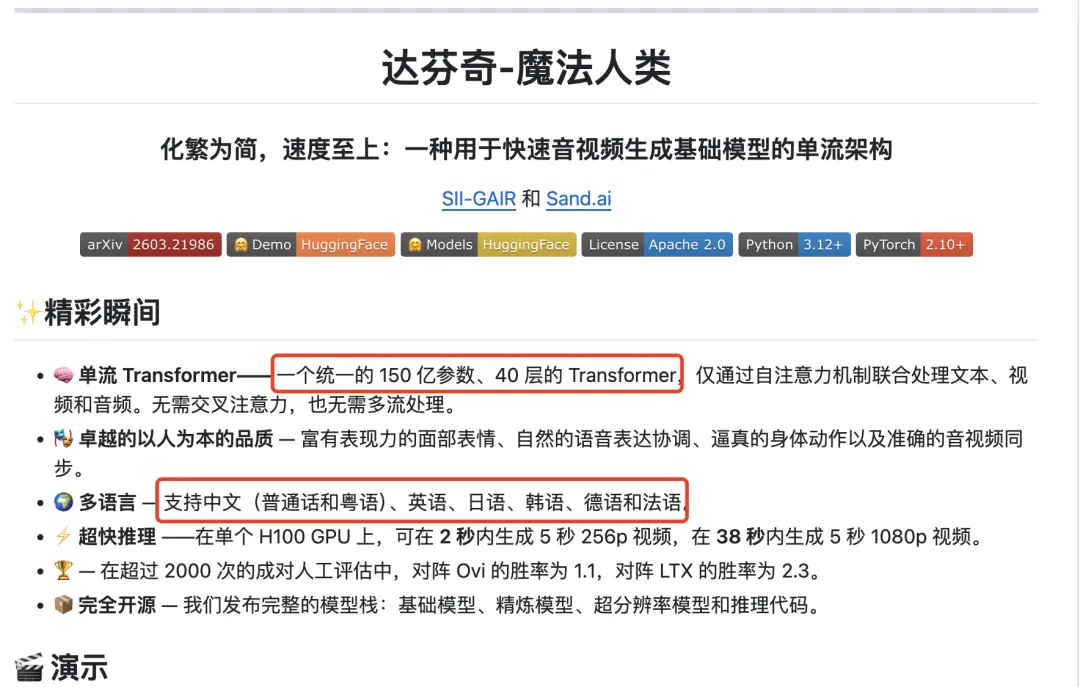
还有一类更具体的说法:认为 HappyHorse 的幕后团队,可是上海创智学院 (SII) 生成式人工智能研究实验室 (GAIR) 与 Sand.ai 联合研发的 daVinci-MagiHuman 项目的一部分。
因为其官网公布的 150 亿参数、支持的语言等能力,与 SII-GAIR 在 github 上公布的文件“daVinci-MagiHuman” 直接吻合。
但无论 HappyHorce 最终归属于谁,这明显都是一次成功的营销。
当一个模型在能力上足够“ 出挑”,但信息又足够模糊时,市场会脑补它一个身份,扑朔迷离的身份攒足了好奇心,也是一种有利的营销方式。
但如果这是一场有组织的传播行为,那么有一个相对明确的判断是:它大概率不是字节跳动。因为几乎所有版本的对比和叙事,都是在直接对标 seedance 和即梦。
所以,它到底会是谁呢?我们就坐等谜底揭晓吧。
* 文中配图来源于网络
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App