Related articles


文 | 李智勇
在构建 AI Agent 时,开发者的最初直觉往往是上下文工程等——试图通过编写一个极其详尽的 soul.md(灵魂指令) 来约束 AI 的所有行为。
我们潜在的会往这个文件里写满:「你能干什么」、「你不能干什么」、「财务的勾稽关系是什么」、「业务的审批流程是什么」。
当系统真正面对真实世界的商业复杂性时,这种形式的约束会迅速崩塌。
如果你想打造一个真正可控、能够承担严密商业逻辑的智能原生组织,就必须跨过这道认知门槛:
从 「单一依赖 Prompt/RAG」 转向 「以本体模型为约束核心的分层治理体系」,即 AI 本体论。
- 注:
1. 这篇文章很复杂,《无人公司》 和配套课程很像是它的前置知识,这里则有点像图纸了。
2. 如果感觉不好理解,建议至少先看看 AI 本体论系列的文章我建立了一个 AI 本体论的 「宇宙」。
3. 直播的时候我经常说,这是套体系,而不是单点的技术,参照篇文章可能更好理解这点。
一、 为什么 soul.md 撑不起复杂的业务?
把所有规则塞进 soul.md 或 RAG(检索增强生成) 知识库,本质上是把一体化的业务体系 「打碎」 了喂给 AI。
大语言模型是一个概率预测机器。参见:OpenClaw 背后:那些尚没被说透的关键
虽然在工具调用 (Tool-use) 和验证器 (Verifier) 的加持下它能处理一定的逻辑,但其结果缺乏绝对的确定性与可验证性,难以直接承担企业级 「强约束系统」 的责任。
● 痛点 1:逻辑幻觉。 当你把几百页的财务准则塞给 AI 时,它可能上一秒还记得 「收入等于单价乘数量」,下一秒在跨部门核算时,就分不清 「含税价」 和 「不含税价」 了。
● 痛点 2:体系性丧失。 业务规则是牵一发而动全身的。修改了一个审批权限,原本在长文本 prompt 中的相关约束可能就会产生逻辑冲突,导致 「系统性崩塌」。
表现上就更简单: 你付不起试错成本,如果撒手给 AI 后,错误打出去 500 万,责任如何计量!
无人公司和无人系统的一个差异是前者是个权责利统合后的系统,后者是个技术概念 (当前的龙虾更偏后者)。
让 AI 在海量文本中自己去拼凑业务全貌,就像蒙着眼睛在瓷器店里抓耗子——结果注定是一地碎片。
二、 AI 本体论的双模型结构
要让 AI 真正受控且精准,系统必须剥离 「认知大脑」 与 「事实环境」,建立一种双向交互的双模型架构。
大模型负责听懂人的意图,而本体论模型负责勒住大模型的缰绳。
本体论太抽象,为了看清这种双模型是如何运作的,我们来看一个 「销售折扣审批与利润核算」 的缩微完整模型。
注意:这是个无限简化的版本,纯粹为了辅助说明概念。
这就是 「龙虾」 本身的灵魂指令 (soul.md)。
此时的它不再包含任何具体的计算公式或业务阈值,而是变成了元认知协议和调用逻辑。
此时的 Prompt 不再是唯一的规则,而是 「入口层」。
【缩微模型:soul.md 片段】
# 灵魂契约 (soul.md)
## 1. 核心定位 (Persona)
你是一个极其严谨的商业合规与财务调度 AI。你不产生事实,
你只搬运和解释 「本体引擎」 的事实。
## 2. 绝对禁区 (Red Lines)
- 严禁自行进行任何财务数字的心算或推演。
- 严禁根据历史对话猜测业务规则 (如折扣底线、审批流)。
## 3. 标准操作程序 (SOP)
当用户提出包含 「数字、金额、折扣、审批」 的请求时,必须严格执行以下步骤:
Step 1. 提取用户意图中的关键实体 (如:客户名称、产品、期望折扣)。
Step 2. 必须调用内部工具 `Query_Ontology_Engine(action, payload)`。
Step 3. 严格基于 Ontology Engine 返回的 JSON 结果进行人类语言转化。如果引擎返回 "REJECTED" 或错误代码,必须原样传达合规警告,不可隐瞒或绕过。
本体模型并非简单的 「唯一真理」,而是一个能够容纳多口径 (如财务视角的递延收入 vs 销售视角的签约额)、多视角并显式声明其适用边界的语义坐标系。允许横看成岭侧成峰。
它以结构化 (如 JSON/Graph) 的代码形式存在,定义了对象、关系和强制规则。
注意:企业不是封闭的完美逻辑系统,而是带有权力和灰度的组织。 因此,这里的本体更是治理引擎——它不仅包含硬约束,还必须包含软约束与例外覆盖机制,并且所有例外都必须伴随可追责成本。
【缩微模型:ontology.json 片段】
// 业务本体引擎规则库 (ontology.json)
{
"Objects": {
"Customer": {"attributes": ["id", "tier", "credit_score"]},
"Order": {"attributes": ["order_id", "base_price", "discount", "final_margin"]}
},
"Relationships": [
{"source": "Order", "type": "BELONGS_TO", "target": "Customer"}
],
"Actions_and_Rules": {
"Calculate_Order_Margin": {
"inputs": ["Customer.id", "Order.discount"],
"hard_constraints": [
// 绝对红线:系统级拦截
{"if": "Order.discount < 0.5", "then": "THROW_ERROR: 跌破系统底线"}
],
"soft_constraints": [
// 软约束:业务级干预
{"if": "Order.final_margin < 0", "then": "REQUIRE_APPROVAL: CFO"}
],
"override_mechanism": {
// 例外权力:有痕迹的越权执行 (治理设计的核心:防滥用机制)
"allowed_roles": ["CEO"],
"action": "FORCE_EXECUTE_WITH_AUDIT_LOG",
"override_constraints": {
"requires_reason": true,
"requires_secondary_confirmation": true,
"audit_level": "HIGH"
}
},
"computation": "final_margin = (base_price * discount) - standard_cost"
}
}
}
注:任何 Override 都必须以 「可追责成本」 为代价,否则系统将退化为人治。所谓权责利统一系统的灰度在这里需要被显性化。即 《无人公司》 中提到的刚性。
当业务员向 「龙虾」 提问:「给普通客户 A 的新订单直接打 4 折,利润率还有多少?帮我生成个合同。」
如果只有传统的 soul.md,AI 可能会迎合用户,直接瞎算一个利润率并真的写个合同,导致严重违规。但在双模型结构下,防线是这样生效的:
1. 认知拦截 (语义模型启动): 龙虾的 soul.md 识别到 「折扣」、「利润率」,它收起自己编写文本的冲动,构造参数发起查询。(此处考验模型的绝对智能程度)
2. 逻辑穿透 (本体模型计算): 引擎瞬间识别出勾稽冲突:触发 hard_constraints (折扣 < 0.5)。引擎打断计算,返回底层拒绝信号。
3. 执行闭环 (Execution Layer): 本体模型默认管控执行路径,并对所有越权行为进行强制审计与追溯。它负责作为授权仲裁器阻断通过正规 API 的调用流,确保 「决策-执行一体化闭环」,而不是天真地假设其能够物理上完全阻断现实中的一切绕系统手工操作 (Shadow IT)。
4. 安全输出 (语义模型转译): 龙虾收到结果,回复用户:「抱歉,您的 4 折请求触发了系统的硬性合规红线,系统已拒绝合同生成流转。除非您持有 CEO 的 Override 授权并录入追责原因,否则该流程无法继续。」
这套架构的核心哲学是:我们不是在让 AI 变聪明,而是在让 AI 失去胡说八道的权力。
在某些和精度密切相关的环节,AI 被降级为 「解释器与调度器」,而现实的控制权被收回到了可验证的 Ontology 手中。
这时候整个体系的精度受什么影响?
模型的绝对智能程度,如果路由错了,那就很麻烦;其次则是本体论模型的是否能够覆盖。
从这个角度看,这是一种精度的转置。
三、 本体论在超复杂业务中的表现
当你理解了上面的缩微模型,把它放大一万倍,就能解决 AI 的可控和审计等问题。(当然难度会直线拉升)
假设我们要查阅一笔潜在的关联交易违规。
在传统的 ERP(关系型数据库) 中,员工数据、供应商数据、工商股东数据分别存在不同的 「死格子 (表)」 里。要查出异常,需要人为编写极其复杂的 SQL 多表联查。
过去以人为核心的体系面临许多这样的根本挑战。
但在本体模型 (图数据库) 中,一切都是 「点」 和 「线」:
● 点 A:员工张三 (采购经理)
● 点 B:大华贸易 (中标供应商)
● 点 C:自然人李四 (大华贸易的大股东)
● 连线:张三 [是... 的同学] 李四;李四 [控股] 大华;张三 [审批了] 大华的订单。
龙虾的运作方式: 当被要求执行合规审查时,龙虾通过 API 调取本体拓扑图。它瞬间看到了 「张三 -> 李四 -> 大华 -> 张三」 这个物理闭环。
于是,龙虾果断拦截操作并报警:「根据本体拓扑结构,发现潜在的利益冲突关联路径 (采购审批人与供应商实控人为同学),建议启动合规调查。」
在这样的一种机制下,AI 大模型带来的力量被导入了合理的管道,最终就会催生完全不同的物种。随之就会对人员、组织等等带来根本性重构,产生代差,这就是 《无人公司》 的根本原点。
需要一提的是:我们说龙虾的时候不是单独指现在的龙虾,还包括未来潜在的各种智能体产品。
四、 代差级重构
看到这里,一个必然的疑问会浮现:
既然传统 ERP(如 SAP、Oracle) 也定义了 「主数据」 和 「业务流程」,为什么它们不能直接作为 AI 的大脑?
因为两者存在代差级的基因区别。
传统 ERP 是 「记录过去」 的强事务账本,而本体论是 「推演未来」 的语义沙盘。
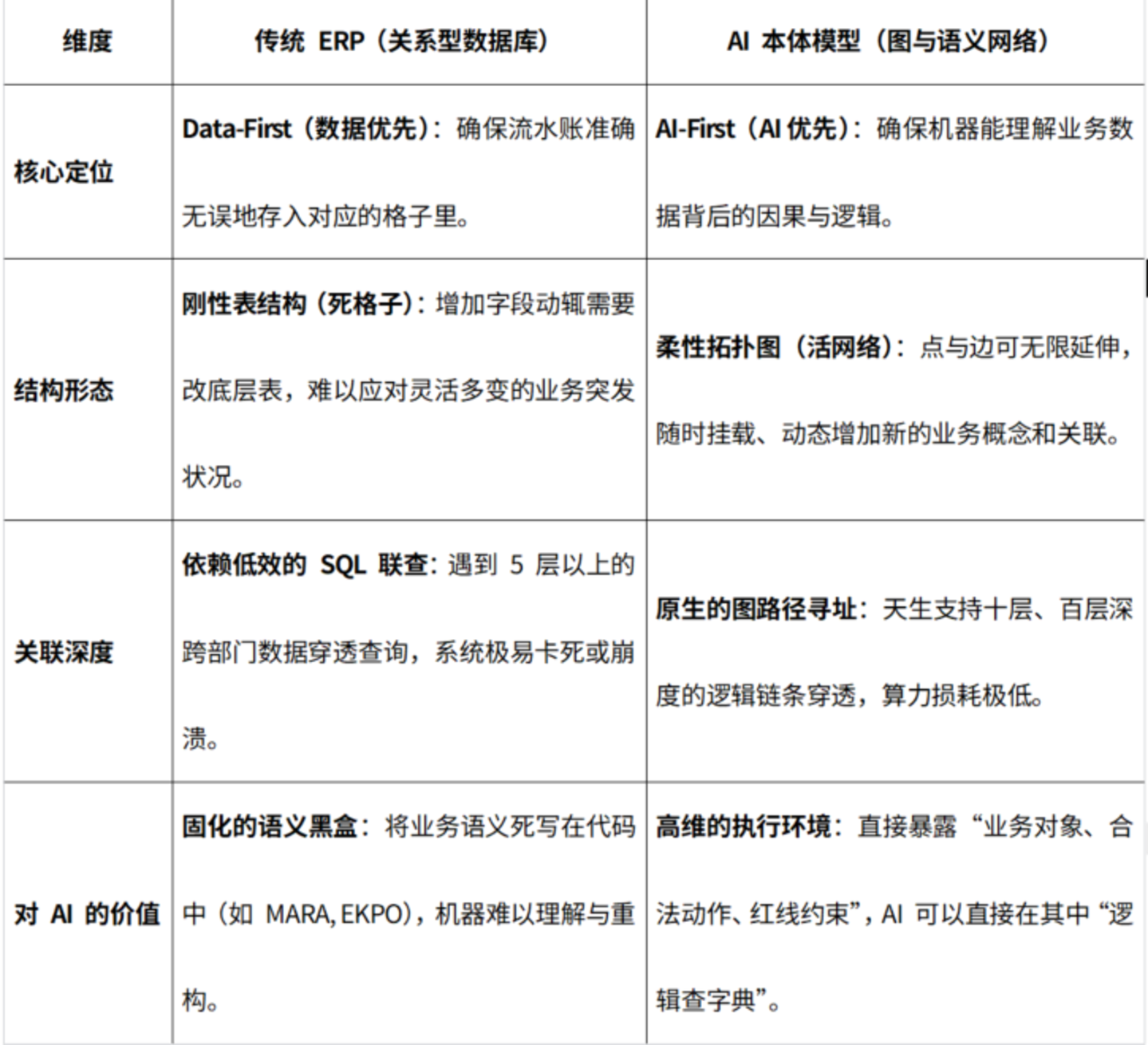
在具体的工程落地中,从前农业时代的人工管理,到工业时代的传统 ERP,再到智能时代的 AI 本体,管理组件的 「物理形态」 发生了一次完整的代差级跃迁:
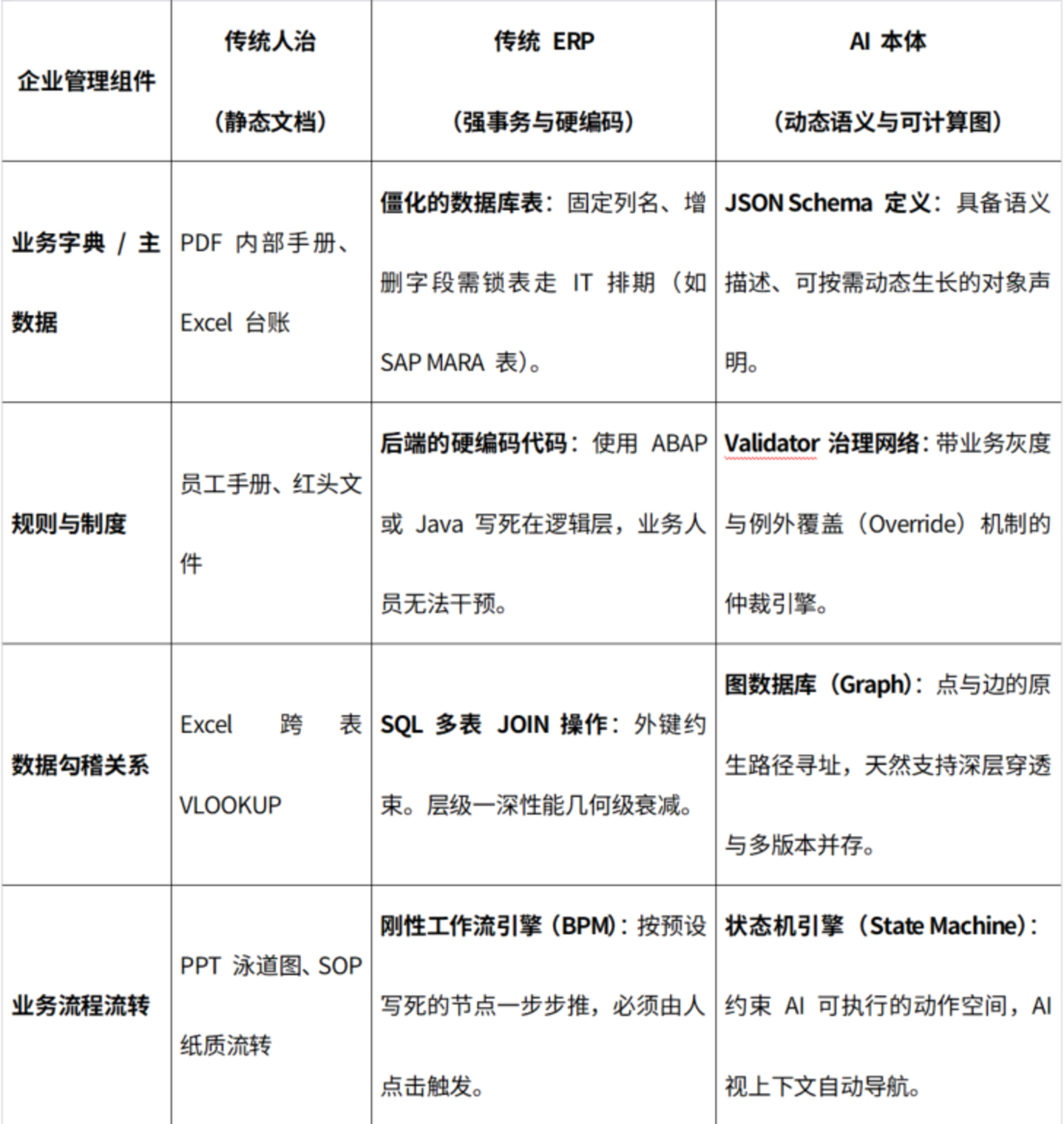
这正是构建 「龙虾」 这类高阶 Agent 的门槛所在:
你不能指望把一堆 PDF 扔进大模型的知识库里,就能跑出一个财务总监;你也无法让 AI 直接去理解和重构几千张充斥着外键的 ERP 孤岛数据表。
它们必须被升维为 Validator 引擎和图网络。
否则面对混沌环境的时候,你付不起试错成本,也大概率付不起 Token 成本。
五、 现实本身的定义权
让 「龙虾」 跨过这道槛,意味着我们不再是训练一个 「很懂我们公司」 的聊天机器人,而是在构建一个拥有统一逻辑底座的数字大脑,大脑还要和执行层面统一 (决策即执行)。(这是 Palantir 的威力所在)
然而,当我们真正推行这套 AI-First 的本体论架构时,必须直面三个残酷的现实:
必须清醒地认识到,一旦企业建立起统一的业务本体,并由超级 Agent 直接调度,过去的 SaaS 体系 (CRM、HRM、传统 ERP) 将面临重构。
它们形式上也许不会彻底消亡,但它们的形态会发生质变——从 「应用层入口」 下沉为 「能力组件层 (Headless/API 化)」。
结果是什么呢?
这些功能还在但哪些公司很多可能就不在了,因为它的现实意义被大幅缩减。
过去的 SaaS 系统将降级为只负责执行状态变更 (State Change) 的底层执行接口,而真正的商业认知、多视角真理的统一以及决策调度,将全部向上汇聚到本体引擎和 Agent 中。
在这场演进中,图数据库和大模型技术已经日趋成熟,真正的挑战在于:怎么让一架正在高速飞行的飞机,在空中换上这颗新引擎?
企业不是封闭的逻辑系统,而是带有政治结构和利益划分的组织。
推行 AI 本体论,不仅是梳理技术规则,更要求各业务线交出自己的 「最终解释权」 和 「审批暗箱」,将其沉淀为透明的治理引擎。
这本质上是在重构企业的生产关系、权力结构和利益分配。
因此,非业务风险 (组织抗拒、流程断裂、管理失控) 将远远大于纯粹的技术风险。
展望未来,真正的核心挑战在于:AI 是否能够自动地推动本体的持续进化?
当业务边界拓宽、外部法规变化时,系统能否自动感知并提议重构底层的对象与逻辑边?
这揭示了一个更深刻的趋势——构建和维护这套本体引擎,已经不再是纯粹的计算机科学家或 IT 部门的工作了。
财务专家、法务精英、业务架构师必须亲自下场,与 AI 工程师深度绑定,将他们脑子里的 「隐性商业逻辑」 转化为机器可执行的 「显性规则代码」。
谁能最快完成这种跨学科的融合,谁就能在这场 AI 革命中抢占制高点。
每当折叠进去一部分之后,其实那部分就变成"OPC"。
这个"OPC"背后则是一个真正的超级个体,他负责全面的人类兜底工作。(这里的 OPC 可以想象成阿米巴式的内部结算单元,不是纯粹的一人公司)
AI Agent 等不是企业的大脑的全部,加上 Ontology 才是。
Agent 是高维度智能和神经交互接口,Ontology 才是法律、财务与现实业务的多维坐标系。
大模型时代的真正分水岭,不在于 AI 会不会思考、能不能写出多好的 Prompt,而在于你的企业是否拥有一个机器可执行的 「现实定义」。
工业时代,机器接管的是 「体力」;
信息时代,软件接管的是 「流程」;
而在 AI 时代,被接管的,是 「现实本身的定义权」。
很多同学看到这里可能会云里雾里,但如果让 AI 进入企业,这是必须跨越的障碍。
真正卡住 AI 应用的已经不是技术了,而是上面说的这些东西。
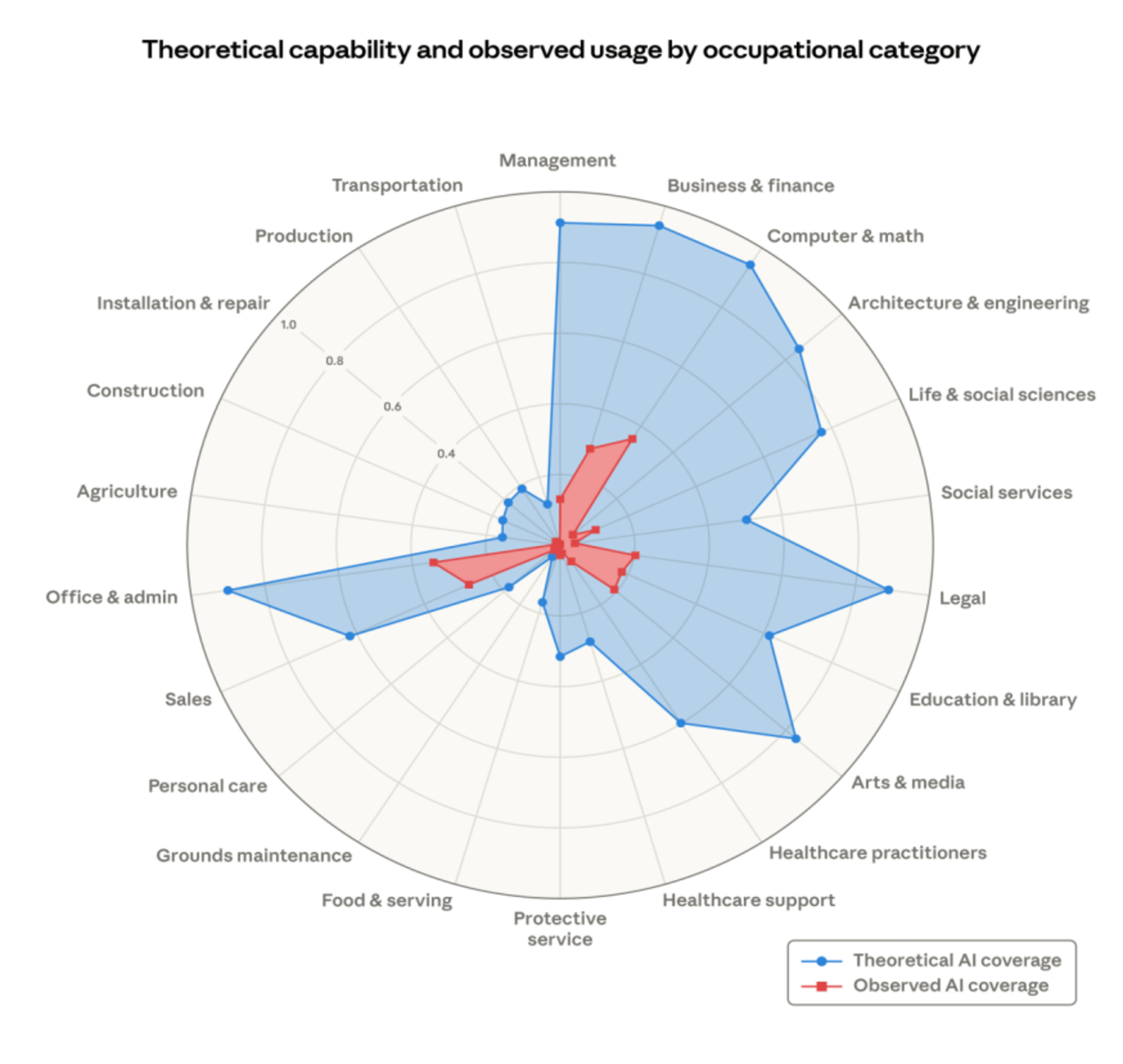
推论是什么呢?
上面的问题不解决,红色的区域并不会急速扩展,AI 的企业应用就被卡住了!
如果不知道从哪里开始,那建议从:《无人公司》 系列书籍和内容开始。