Related articles


文 | 舒书
2026 年 2 月,全球 AI 产业迎来一个标志性时刻。
一边是英伟达发布史上最强财报后股价暴跌 5.5%,一夜蒸发近 2600 亿美元;另一边是 A 股算力、云计算板块掀起涨停潮,云天励飞、普元信息等纷纷封板。

这冰火两重天的背后,是一个简单却震撼的数据:中国 AI 模型的周调用量首次超越美国。在 2 月 16 日至 22 日当周,中国模型调用量达 5.16 万亿 Token,全球前五模型中中国占据四席——MiniMax、月之暗面、智谱、DeepSeek。
消息传出后,业内一片沸腾。但热闹之余,一个更深层的问题浮出水面:这种优势是昙花一现,还是持久红利?

01 三个支点
中国 AI 的这次突破,建立在三个支点上。
第一个支点:极致的成本优势。
中国西部绿电价格约 0.2-0.3 元/度,仅为欧美的 1/5 到 1/4。加上中国模型普遍采用的 MoE 架构,能让推理时的显存占用降低 60%,吞吐量提升 19 倍。两者叠加,造就了 0.3 美元/百万 Token 的惊人低价——仅为海外对手 Claude 的 1/16。
这不是短期补贴,而是 「能源禀赋+技术选择」 形成的结构性成本壁垒。

第二个支点:算力效率的范式转移。
当全球还在迷信 「堆卡」 时,中国用更聪明的算法,让同样的硬件产出更多 Token。MoE 架构通过 「按需激活」 部分专家网络,大幅降低了单位 Token 的算力消耗。
这意味着什么?Token 增长不再与英伟达 GPU 需求线性挂钩。客户可以用更少的芯片,服务更多的用户。英伟达的 「必买性」 被动摇了。

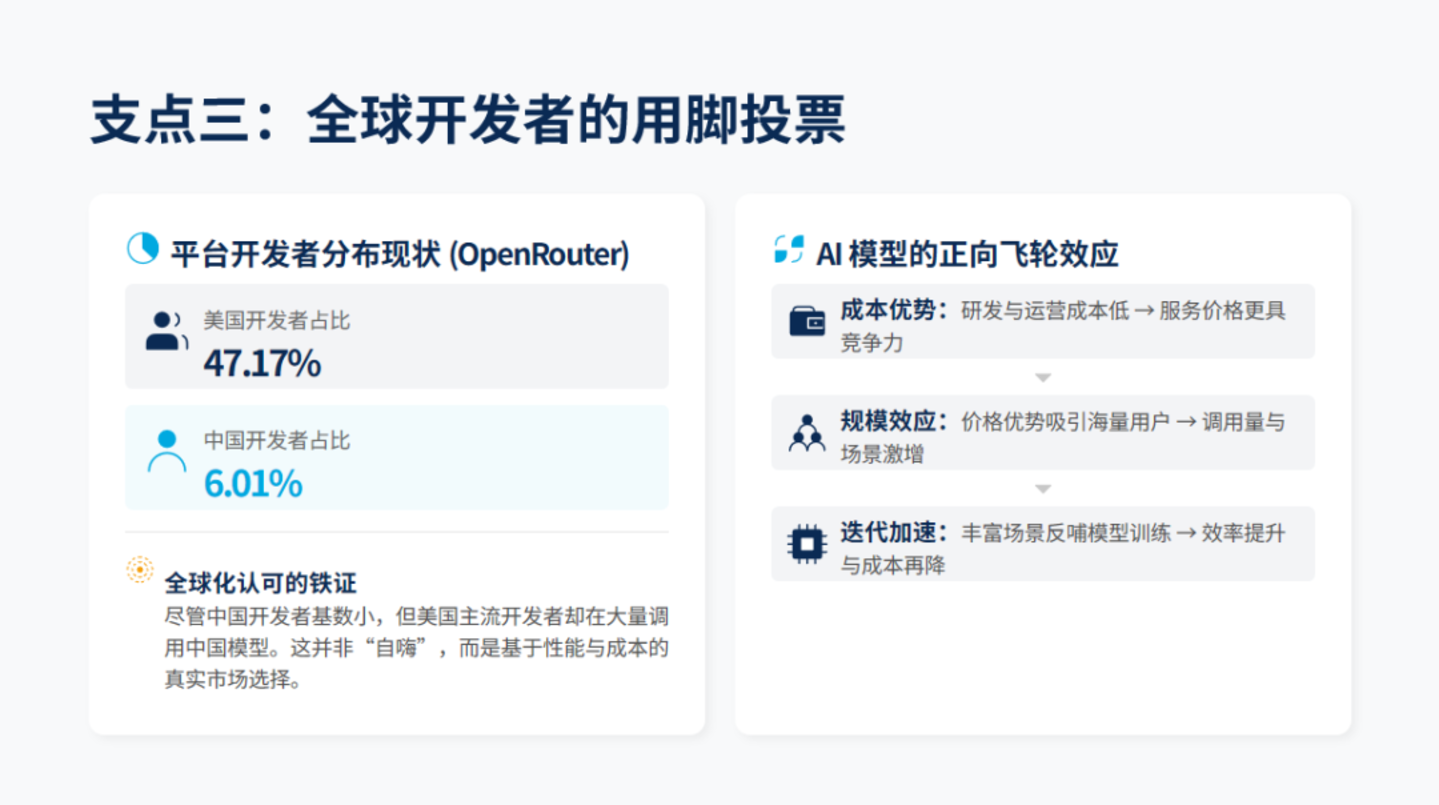
第三个支点:全球开发者的用脚投票。
OpenRouter 平台上,美国开发者占 47.17%,中国仅占 6.01%。但正是这些美国开发者,大量调用中国模型。这不是 「自己人捧场」,而是真正的全球化认可。
三个支点相互强化:成本低→价格低→用户多→调用量大→场景丰富→模型迭代快→效率更高→成本更低。一个漂亮的正向循环。
02 成本优势:能持续多久?
中国 AI 的成本优势,很大程度建立在西部绿电的低价上。
但未来 3-5 年,这个优势正在发生变化。根据预测,西部绿电价格将从当前的 200-250 元/兆瓦时,逐步升至 2028-2030 年的 280-330 元/兆瓦时。与此同时,欧美光伏、风电成本正在快速下降,部分领域 LCOE 已降至 200-550 元/兆瓦时。
这意味着,当前 5-6 倍的价差,3 年后可能缩小到 2 倍左右。
但更关键的变化不在这里。东数西算工程的实质进展,正在改变游戏规则:西部枢纽累计建成标准机架超 1085 万架,网络时延控制在 4.5-14.3 毫秒,绿电使用占比超 80%,部分项目 PUE 值低至 1.04。
真正的护城河不是电价本身,而是 「绿电+液冷+低 PUE」 的系统性成本优势。当算力可以像电力一样 「西电东送」 时,成本优势就固化为基础设施红利。
电价会涨,但系统效率的优势不会轻易消失。

03 效率优势:MoE 之后怎么办?
目前中国模型普遍采用 MoE 架构,这是效率优势的核心来源。但问题是,美国正在快速跟进。
Claude 4.6 已明确采用 MoE,GPT-5 虽未明说,但其 「多模型混合系统」 本质上是类似的思路。当技术趋同,中国的优势还剩下什么?
答案是工程化能力。
当美国也全面转向 MoE 后,竞争的焦点将从 「有没有 MoE」 转向 「MoE 落地得好不好」。这方面中国有独特积累:成本控制能力 (价格已是美国的 1/16)、稳定性运营能力 (支撑 5.16 万亿 Token/周的调用)、场景适配能力 (快速响应不同开发者的需求)。
但隐忧同样存在。在下一代架构的探索上,美国仍保持微弱领先。状态空间模型 (如 Mamba)、世界模型 (如 Genie 3)、持续学习架构 (如 Titans)——这些可能接替 MoE 的方向,美国都走在前列。

中国在基础架构层的原始创新能力,还需要时间沉淀。高校和企业培养了大量应用型人才,但顶尖创新人才更多集中在应用层。专利数量领先,但基础架构专利的质量与美国的差距需要正视。
MoE 带来的窗口期大约 2-3 年。之后,要么在工程化上建立不可替代的优势,要么在下一代架构上实现突破——二者必居其一。

04 市场优势:全球开发者会一直留下吗?
当前中国模型的海外成功,高度依赖一个事实:美国开发者占 OpenRouter 平台的 47%。
这是成功的证明,也是风险的集中。
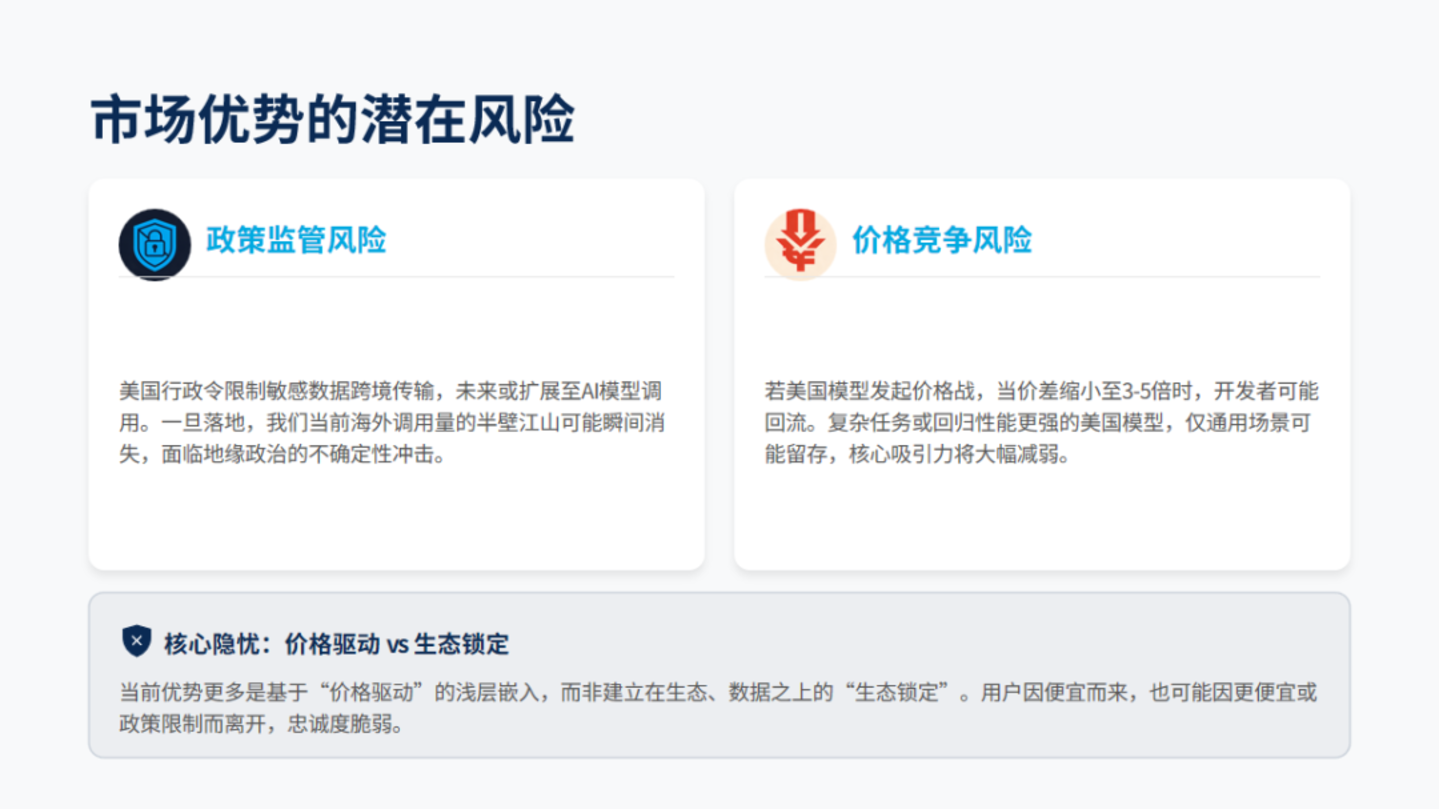
第一个风险是政策。美国第 14117 号行政令已明确限制敏感数据向中国等 「受关注国家」 跨境传输。虽然目前主要针对个人隐私数据,但未来扩展至 AI 模型调用并非不可能。如果美国出台政策限制 API 调用,当前调用量的半壁江山可能瞬间蒸发。
第二个风险是价格。当前 16.7 倍的价格差是开发者选择中国模型的核心驱动力。但如果美国模型继续降价 (OpenAI 已多次下调价格),价差缩小到 3-5 倍,开发者会如何选择?
复杂任务可能回流美国高端模型,因为性能优先;通用场景可能留在国产模型,因为成本优先;企业级应用则可能综合考虑生态、合规等因素。
最乐观的情况是中国模型凭借成本优势守住基本盘。但最悲观的情况是:政策筑墙切断海外市场,价格战压缩利润空间,两头受压。
真正的挑战在于:当前的市场优势是 「价格驱动」 的浅层嵌入,而非 「生态锁定」 的深度绑定。开发者因为便宜而用,也可能因为别人更便宜而走。
05 价值流向:谁赚到了钱?
调用量暴涨,钱被谁赚走了?
先看模型厂商。
智谱、MiniMax 等头部企业已在 2026 年 1 月成功登陆港交所,成为 「全球大模型第一股」 阵营。
智谱 (02513.HK):IPO 募资约 43 亿港元,上市不到两个月,市值已突破 2500 亿港元,较发行价翻倍。其 API 收入增长 30 倍,日均 Tokens 消耗量增长 150 倍,B 端政企客户贡献超 80% 收入。
MiniMax(0100.HK):创下全球 AI 企业从成立到 IPO 的最快纪录 (仅 4 年),上市首日市值破千亿港元。其 API 收入占总营收 29%,且海外占比超 70%,展现出极强的全球化变现能力。
月之暗面:虽暂未上市,但凭借 Kimi 模型的爆发,API 收入实现 4 倍增长,传闻其上市计划也已提上日程。
然而,上市不等于盈利。
所有模型厂商仍处于 「高增长、高亏损」 阶段。巨额的研发支出和算力成本,使得盈利周期依然模糊。上市后,它们面临的挑战从 「如何拿到下一轮融资」 转变为 「如何在资本市场的高预期下,平衡现金流与持续投入」。若无法尽快证明商业闭环能力,股价波动将成为悬在头顶的达摩克利斯之剑。
再看算力厂商。
中国模型的成功,为国产芯片创造了真实的 「试验田」 和放量机会。
摩尔线程:推理业务占比从 77% 升至 94%,成为国内模型推理的首选国产方案之一。
华为昇腾:2024 年出货 64.4 万片,国内 AI 芯片市占率约 23%,在智谱、百度等大客户的供应链中占据核心地位。

基础设施层依然是最大赢家。
无论模型厂商谁胜谁负,无论是否盈利,算力消耗是刚性的。
百度智能云:AI 收入增长 34%,AI 高性能计算设施收入增长 143%。
阿里云:AI 收入连续 8 个季度三位数增长。
数据中心:中国 AI 数据中心市场规模年复合增长率超 50%,「东数西算」 节点满载运行。
结论很清晰:
当前阶段,基础设施层和算力层是确定的获利者,它们赚取了产业爆发的 「过路费」 和 「基建费」。
模型厂商虽然通过上市获得了巨额资金支持和市值溢价,但本质上仍在 「用资本换时间」。未来 3-5 年,它们必须从 「流量变现」 转向真正的 「价值变现」,否则可能面临市值回调的风险,甚至沦为基础设施层的 「高级打工者」。
06 产业格局:谁主沉浮?
「百模大战」 正在走向分化。
创业模型厂商中,智谱聚焦 B 端,约 80% 以上收入来自政企客户;MiniMax 侧重 C 端全球化,超 70% 收入来自海外;月之暗面凭借 Kimi 模型实现 API 收入爆发。未来 2-3 年,头部厂商有机会成为独立玩家,但大多数会被并购或退出。
国产芯片企业迎来历史性窗口。但窗口期可能只有 2-3 年——美国可能放松芯片管制,国产芯片同质化竞争加剧,下一代算法架构可能改变算力需求特征。国产芯片需要在这期间完成从 「可用」 到 「好用」 的跨越,并建立自己的软件生态。
全栈巨头正在形成协同优势。华为拥有昇腾芯片+盘古模型+鸿蒙系统,形成 「算力-模型-终端」 闭环;联想布局 AI 服务器+混合式 AI+AI PC,覆盖 「云端-边缘-终端」。当行业从 「技术探索期」 进入 「规模化应用期」,这些巨头的渠道能力、客户资源和产业链整合能力将成为核心优势。
未来 3-5 年,产业格局将呈现 「分层分化」:头部创业厂商有机会独立存活,国产芯片迎来有限窗口期,全栈巨头可能成为最终的产业底座。
07 全球博弈:美国会如何反应?
中国的这一轮突破,必然会引发美国的反应。从目前看,反应将分三个层面展开。
市场层面,美国模型已经开始降价。如果价差从 16.7 倍缩小到 3-5 倍,中国模型的 「性价比」 优势将大打折扣。但美国模型不可能降到和中国完全一样的水平——其电力、人力、合规成本都更高。
政策层面,数据跨境监管已经收紧。最坏情景是禁止联邦机构使用中国模型,限制美国企业调用中国 API。这会导致当前调用量的核心来源大幅萎缩。
技术层面,美国在下一代架构上仍保持微弱领先。如果美国在 SSM、世界模型等领域取得突破,重新拉开代差,中国可能面临 「刚追上又落后」 的困境。这是最根本的挑战,也是最难应对的。
最核心的问题在于:中国 AI 的竞争力,目前更多建立在相对优势 (成本、效率) 上,而非绝对优势 (技术代差) 上。这意味着,我们更容易被追赶,也更容易被政策切断。
08 窗口期与抉择
把以上分析串联起来,中国 AI 的 「成本 - 效率 - 市场」 三角结构,是在美国芯片封锁倒逼创新、能源政策提供红利、工程师红利集中爆发这三重历史条件下形成的。这不是偶然,而是多种力量共同作用的结果。
但这个结构并非稳态。综合判断,窗口期大约为 3 年。
在此期间,三重优势正在收窄:电价差将从 5-6 倍缩小至 2 倍左右;MoE 带来的效率红利仅剩 2-3 年;地缘政治筑墙的风险可能导致海外市场收缩。三个维度虽仍有余地,但倒计时已经开始。这 3 年,是中国 AI 从 「借势」 到 「造势」 的关键时刻。
窗口期结束后,产业将走向两条截然不同的道路:
要么完成跃迁,要么陷入红海。
未来一:完成跃迁。从 「性价比优势」 升级为 「技术定义权」——在下一代架构 (状态空间模型、世界模型、持续学习) 上实现突破,建立不可替代的技术壁垒。从 「价格驱动」 转向 「生态锁定」——让开发者不是因为便宜才用,而是因为好用、离不开才用。当生态形成,用户粘性本身就是护城河。从 「单点突破」 转向 「系统协同」——算力、模型、应用形成正向循环,产业链各环节都能捕获价值,而非只有基础设施层获利。这是跃迁之路。难,但可期。
未来二:陷入红海。成本优势被拉平——当电价差缩小、MoE 趋同,价格战的空间消失。技术趋同导致同质化竞争——大家都在用类似的技术,拼的是谁更能 「卷」。海外市场受政策挤压——美国开发者市场萎缩,只能向内寻找增长。国内模型厂商在价格战中耗尽利润——最终沦为基础设施层的 「附庸」,为云厂商、算力厂商 「打工」。这是红海之路。易滑入,难挣脱。

2026 年 2 月的这个 「反转时刻」,真正的意义不在于证明 「我们赢了」,而在于提醒我们:窗口期已经打开,但正在倒计时。
如果只有兴奋,没有警觉;只有欢呼,没有行动——3 年后回头看,今天可能只是红海前的最后一次高光。如果能在窗口期内完成从 「借势」 到 「造势」 的跃迁——今天就是未来 10 年的起点。
接下来的 3 年,中国 AI 产业需要回答的根本问题是:当电价红利消退、MoE 红利趋同、海外市场承压之后,我们还能靠什么赢?
是靠下一代架构的原创突破?是靠生态锁定的用户粘性?还是靠全栈协同的系统能力?
这个问题没有标准答案。但每一个答案,都将决定未来 10 年中国 AI 的江湖地位。
窗口期已开。时钟在走。