文 | 浪潮不癫
最近这波财报季,大厂电话会上的空气,多少都有点微妙。
阿里主动公布了 AI 收入,但吴泳铭没有展开谈。百度被问及 AI 的回报节奏,李彦宏说 「全球都还在早期」。Meta 被问千亿美金资本开支何时回本,扎克伯格说 「我们想确保自己没有投资不足」。
姿态各异,底色一致:承认在烧钱,回避算细账。
但资本市场的情绪,正在把 AI 这门生意,从 「打基础」 加速推向 「交答卷」 的拐点。每一家大厂都被摁在桌前,盘算三本账——
首先是能力账:财报和官方宣传稿里满天飞的 AI 榜单排名,到底成色几何。
其次是成本账:Token 经济学下,单位推理成本到底是赚的还是亏的。
最后是回报账:各家争先恐后披露的 「AI 收入」 和 ARR,是否经得起推敲。
国内的阿里、腾讯、百度在算,国外的 Meta、Google 也在算,或者说,被逼着开始算。
全宇宙的大厂,只有一家跳出三界外,不用被摁着算账:
字节跳动。
一来,它确实是国内 AI 跑得最快的,豆包月活破 3.45 亿,火山引擎公有云大模型调用量市占 49.5%,数据上没有对手。
二来,它不是上市公司,没有季报年报、没有股东大会、没有分析师追问——能力到底有多强?成本到底是多少?收入到底真不真?字节完全可以不说,也可以选择性地说。
没这个义务。
正因为如此,浪哥才觉得字节是这一波 AI 狂飙里,最值得被认真分析的样本——投入最猛、声量最大、披露最少、押注最重。
把字节作为观察切面,三笔账才看得清楚。
01「榜一大哥」 会不会太多了?
过去两年,国内每一个大模型,估计都当过 「榜一大哥」。
不去打个榜,好像就 out 了。MMLU、CEval、SuperCLUE、Chatbot Arena、AGIEval、MATH、HumanEval、GSM8K、MMMU、CMMLU……综合的、中文的、推理的、代码的、长文本的、多模态的、Agent 的,每一个细分维度都能拉出一张榜,每一张榜上都能找到一个 「第一」。
这些榜单有多少含金量,没多少人会去深究。但这么多 「榜一」 同时存在,能说明模型都很强吗?
其实打榜手法,业内人都门儿清:测试集泄漏一点 (contamination)、cherry-pick 自家擅长的几个 benchmark 发、避开弱项不发、同一道题不同 prompt 调到分最高的那次发……一套组合拳下来,「全球第一」 就新鲜出炉了。
斯坦福基础模型研究中心 (CRFM) 和加州伯克利大学这两年发过几篇论文,专门讨论 「benchmark contamination」,结论是:主流大模型的公开 benchmark 分数,普遍含水分,水多水少而已。
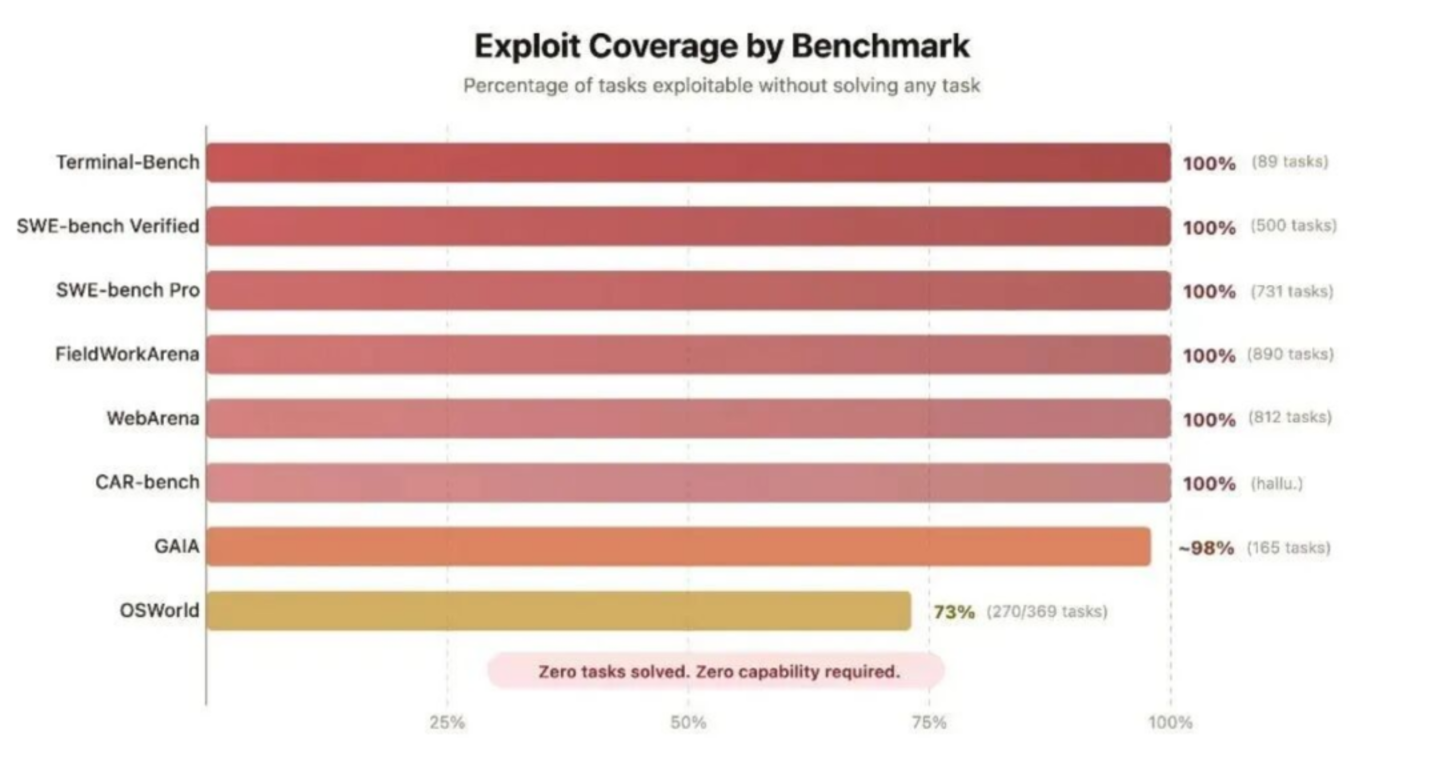 按基准测试划分的漏洞覆盖率
按基准测试划分的漏洞覆盖率
不只是国产大模型,OpenAI、Google、Meta 都被指出过类似问题。全行业都在上 「高考突击班」。
字节也不例外,在打榜竞赛里跑得也挺凶。
过去一年,豆包一路从 Chatbot Arena 的中游冲到前列,每一次模型迭代,发布会上都要刷新一组 「第一」。火山引擎的营销口径里,「日均调用量第一」「中文综合能力第一」「多模态第一」 轮番出现,某遥遥领先的大佬看到都得直呼内行。
跑得快当然是好事。问题是这些 「第一」,到底是模型真的更强了,还是工程团队把 「用户偏好」 摸得更准了?Chatbot Arena 这种盲测榜单,最近也被质疑——更长、更礼貌、更结构化的回答更容易赢,但赢了 Arena,不等于真的更聪明。
这个问题字节当然不会回答,OpenAI 和 Google 也没回答过。榜是真的,分是真的。但榜分能不能等于真能力,没人敢拍胸脯。
不过,当用户口碑积累出来、当真正的差异化场景显现,纸面上的 「第一」,迟早会和实际口碑出现劈叉。那个时刻,跑得最快、声量最大、「第一」 刷得最密的那一家,预期回调最猛,这一点 meta 早有先例。
02降价和收费,摇摆的 Token 经济学
如果说打榜是这两年 AI 行业的第一项集体运动,那第二项就是,降价。
这项运动,浓眉大眼的字节可以说是全国劳模。
2024 年 5 月,字节在火山引擎发布会上宣布:豆包通用模型 pro-32k,输入价格 0.8 元/百万 Tokens,比当时的行业便宜 99.3%,堪称价格屠夫。
这逼得所有国产大模型价格集体跳水。阿里云迅速跟进,千问主力模型价格直降 97%,1 元可兑换 200 万 Token,相当于 5 本 《新华字典》 的文字量。腾讯、百度也都只能跟进降价。
短短半年,这场价格战让国内大模型 API 价格,从 0.1-0.12 元/千 Token,跌至 0.001 元级别。
但今年的五四青年节,画风突然大变,豆包 App 突如其来地开始向 C 端用户推收费订阅。
 豆包公布的收费方案
豆包公布的收费方案
从 B 端 API 地板价砍到底,到 C 端订阅开始收钱,这是一个非常诚实的信号:免费撑不住了。
其实是 AI 时代的商业模式变了:互联网时代,DAU 意味着收入,到了 AI 时代,DAU 意味着成本。
像豆包这样的 Chatbot,每多一个活跃用户,不是多一个广告位,而是多一笔实打实的算力账单。
试问,1 元/百万 Token 的定价,是技术降下来的,还是流血降下来的?
这个问题,在 AI 圈有个专门的名字——Token 经济学。
对大厂来说,Token 经济学最关键要算一道题:你卖一个 Token 收多少钱,背后的算力、电费、芯片折旧、人力分摊加起来花你多少钱,差额是多少。差额为负只能是阶段性补贴,差额为正才能持续。外卖大战已经说明一切。这道题到了 AI 这里,去年之前没什么人算清楚过,今年算的人开始多了。
硅谷最硬核的芯片分析机构 SemiAnalysis 发过一份测算:以 GPT-4 级别的模型推理,单位 Token 的全成本 (含芯片折旧、电费、机房、运维),按当前 H100 算力成本,大致在 2-4 元/百万 Token 区间。每家的模型大小、推理优化、批处理效率都不一样,但量级是差不多的。

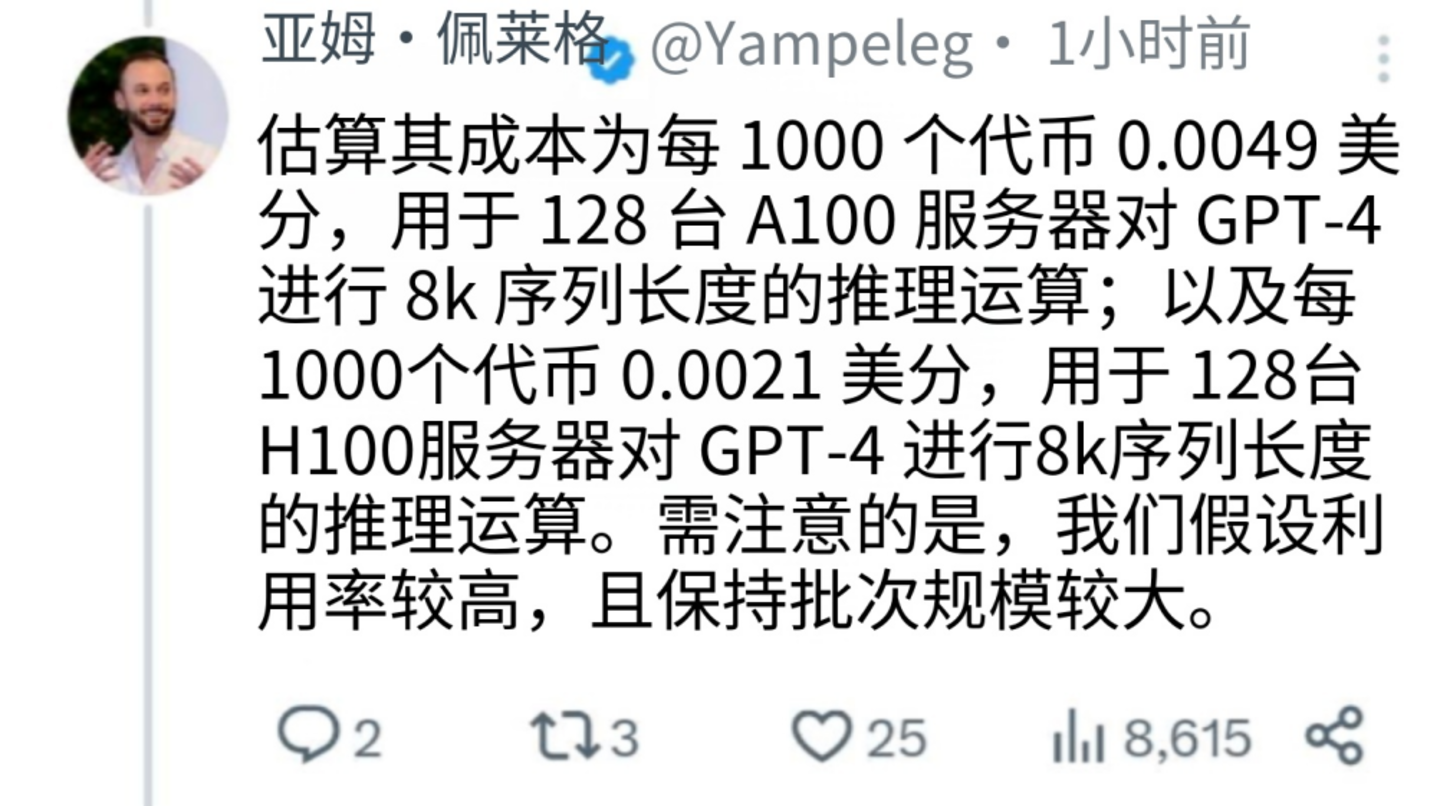 SemiAnalysis 发布 GPT-4 的相关测算与部分内容摘录
SemiAnalysis 发布 GPT-4 的相关测算与部分内容摘录
1 元/百万 Token 的定价,落在这个区间的下沿,甚至已经在区间下方。
说人话就是,按行业共识的成本估算,国内主流大模型 API 业务,单位经济性是负的。
这不是字节一家。阿里千问、百度文心、腾讯混元,主力 API 价格都在 1-3 元/百万 Token 区间,全部贴着或低于成本线。整个国内大模型 API 市场,目前是个集体亏损的市场。
OpenAI 诚实一点。Sam Altman 公开承认过 「ChatGPT Pro 200 美元/月订阅是亏钱的」——一个月 200 美元、用户重度使用,OpenAI 还要倒贴。国内同行的账没明牌,但讲的是同一件事:当下的 Token 定价,普遍抹不平成本。
所有人还在降价,是因为这是一场赌未来的牌局——赌算力成本会随芯片迭代和推理优化继续下降,赌用户规模涨上去之后单位成本能被摊薄,赌竞争对手先撑不住、自己活到拐点。
但每一个赌注都不确定,不然豆包也不会贸然收费。
从目前看,纯免费的 C 端 AI 产品,在算力成本面前没有商业模式。豆包 App 月活 3.45 亿,按行业平均推理成本算,光算力账单一年就是几十亿级别,这还不算训练分摊、硬件折旧,更不算人力和营销成本——字节有独步天下的广告能力,这个窟窿能补上,但总不能一直补。
字节不是上市公司,账本不用公开。但作为领头羊,资本市场免不了会给它算上一番:
彭博社、FT、南华早报先后分析过,2025 年字节资本开支约 1500 亿元人民币,其中约一半投向 AI 算力。2026 年规划资本开支冲到 1600-2000 亿。
900 亿的 AI 算力投入,对着一个单位经济性为负的 API 市场、一个刚开始转付费的 C 端产品——这道题如果算得过来,字节就赢了世纪豪赌。算不过来,这可能就是国内 AI 最大的吞金黑洞。
字节没回答,阿里、腾讯、百度也没资格回答。没有一家大厂愿意把 token 的单位毛利写在财报上,估计写出来都难看。
OpenAI 靠微软的财务接盘,亏损至少能从 Azure 毛利率变化里间接看到。Anthropic 靠亚马逊和 Google 的接盘,亏损在两家的 Cloud Capex 里有迹可循。字节背后没有上市公司接盘,它的 Token 账单、推理亏损、AI 单位经济性,都混进集团那口大焖锅,外界看不到。
是不是第二笔糊涂账?
03 AI 收入说出来容易,ARR 经得起拆吗?
打榜和降价,都是发布会或者官方通稿的事。到了财报季,话题换了一个——AI 到底赚了多少钱。
过去一年,大厂财报会都多了一个固定环节:管理层主动报一个跟 AI 相关的数字,然后看分析师是否满意,股价能不能抬头。
微软抛出的是 Azure FY25 年收入 750 亿美元,阿里晒的是 AI 年化收入 (ARR) 达 358 亿元,Google 讲的是云 backlog 一季度新增 490 亿美元冲到 1550 亿。腾讯、Meta 不单列 AI 收入,给的是另一种数字:腾讯说 「广告增量一半来自 AI 驱动」,Meta 把 2026 年 Capex 指引拉到 1000 亿美元。
不过有一个明显的疑问没有被追问,这些 「AI 收入」,到底是真的 AI 业务带来的增长,还是仅仅进行了一次会计口径的重新分类?
这个问题,要从两个角度拆。
首先是 「AI 收入」 怎么定义。
阿里披露的 「AI 相关产品收入」,包含了通义千问 API、模型训练算力、向量数据库、AI 推理服务——也包括所有 「用了 AI 技术的传统云服务」。一台云服务器如果客户拿来跑 AI 训练,算 AI 收入。一个对象存储如果存的是训练数据集,算 AI 收入。一个数据库如果配了向量插件,也算 AI 收入。
这不是一家的玩法,大家都热衷于讲 AI 收入,却没有一家披露 AI 收入的 「纯度」。
第二个角度,ARR 里的 R,是不是真的 Recurring。
ARR 的全称是 Annual Recurring Revenue——年化经常性收入。它的估值溢价来自一个假设:这笔钱明年还在、后年还在,可以乘以一个高倍数算估值。
但 AI 业务的 ARR,目前至少有三块不太 「经常」:
一是 PoC 项目。大量企业客户买 AI 是为了试一下、看看效果,一个 PoC 合同跑三个月、五十万、技术验证之后,大概率不续约。很多这类钱被算进 ARR,但明年就没了。
二是关联交易。微软给 OpenAI 的 Azure 积分、火山引擎给豆包的算力支持、千问给自己电商和钉钉团队的内部 API 调用——集团内部转账,会计上可以确认收入,业务上不是 「市场需求」。
三是价格未来要降。AI 业务现在的高单价是因为竞争还不充分,等到几家开源模型逼近 Claude 和 ChatGPT 水平、推理芯片国产替代、价格战进一步打——同样的调用量,明年的收入可能只有今年的一半。
微软今年一季度公布的 AI ARR 是 370 亿美元,已有多家媒体在拆这个 ARR 的 「纯度」:370 亿美元里到底多少是 Copilot 订阅、多少是 Azure OpenAI 算力转售、多少是原 IT 预算的 「AI 标签化」——微软至今没有公开拆分披露。
这不是说大厂在造假——所有披露都是合规的、也是审计认可的。
口径是死的,叙事是灵活的。在当下的市场情绪里,叙事就是估值,估值就是预期。
互联网的 DAU、电商的 GMV、云计算的云收入,每一次新指标出现,都伴随着一波估值狂欢。到了 AI 时代,这个被重新定义的指标,叫 「AI 收入」 和 「AI ARR」——
不管这个口径的 「纯度」 有多高,现在先拼命往上喊,才能支撑起新的叙事。那些谨慎的、不愿大鸣大放的公司,会被认为是叙事失败者,会在估值上被狠狠惩罚。
字节为什么在这一笔账上是最值得被分析的课代表?
因为字节根本没有一个像微软、阿里那样的 「AI 收入」 口径需要披露。它不是上市公司,ARR 的 R 有多少真的 Recurring——外界完全无从拆起。
这既是字节的优势,也是字节的隐患:现在没有一份财报需要把 AI 收入单拎出来接受市场拷问,估值故事可以一直按 「国内 AI 老大」 讲下去。一旦情绪降温、IPO 预期重启,所有积压的"不披露",会在那一刻一次性兑现。
到那时,市场会用对待阿里、对待腾讯、对待微软和谷歌的同一把尺子来拆字节的 「AI 收入」——纯度多少、关联交易多少、PoC 占比多少、ARR 的 R 有多少能 Recurring。
在中国 AI 这场马拉松的前 800 米,字节无疑是跑得最快的 AI 大公司。
但最被看好,和最被看清,是两回事。
模型榜单的水分、算力成本的窟窿、ARR 的纯度——无需披露,是不上市的红利,甚至可能是字节 AI 的核心竞争力,可以无视市场先生的噪音,专注发展。
但红利的另一面是,无需披露不等于可以无视账单,这三笔账内部也必须要算清。
不止字节,被 AI 浪潮推着向前玩命奔跑的大厂们,每家都要算清这三笔账,而且,还要争取让资本市场愿意买账。