Related articles

文 | 科技不许冷
过去几天,科技圈的视线全被DeepSeek 吸走了。
满屏都是传闻中的估值溢价,或者是跟各类国产算力芯片的适配通稿。市场的狂热情绪,很容易让人迷失在庞大的数字迷宫里。大众的关注点,要么是「百万上下文"这个听起来很唬人的标签,要么是跑分榜单上「谁又赢了谁零点几分」 的算术题。
DeepSeek V4-Pro 的分数确实好看。从其技术报告披露的底牌来看,在 SimpleQA-Verified 测试中,它以 20 个绝对百分点的优势甩开了所有开源对手;在 Codeforces 代码竞赛里,预期评分直接追平了 GPT-5.4。当然,在世界知识的广度上,它依然略逊于 Gemini-3.1-Pro;遇到极高难度的复杂任务,跟 Claude Opus 4.6 也还有微小的身位差。
但这都不重要。
如果你只盯着榜单排名,就完全看漏了这家机构真正的野心。
DeepSeek 根本不是在发布一个用来刷榜的模型参数包。它实际上是在一点点拆开 「百万上下文」 这件事的底座。
大模型的战争,已经从模型层退场,全面接管系统层。
过去几年,行业都在拼脑容量。比谁的参数多,比谁跑分高。但这套玩法到头了。V4 的出现,是在定义一套新规矩:模型本身,只是高效工程系统自然结出的一个副产品。
当1M 上下文变成所有官方服务的出厂默认值时,从其开源实现中可以清晰地看到一个事实:这绝对不是靠算力硬堆出来的。长文本时代的下半场,拼的从来不是智商。
而是机房调度能力。
13B 激活参数,把 37B 按在地上
调度能力从哪看出来?先看V4 最反直觉的一个设计:Pro 和 Flash 的共生关系。
行业里一看到「Pro」 和 「Flash」,第一反应就是精准刀法:Pro 用来打标杆,Flash 用来做下沉市场,收割中小企业。
这种典型的商业包装逻辑,放在V4 身上,看偏了。这两者根本不是算力降级关系,而是验证同一套底层逻辑的对照组。
大模型过去的长文本能力,本质上是用显存硬堆出来的伪能力。只要给的GPU 够多,显存够大,不管多长的文本都能硬吞下去。但代价是,成本高到根本没法在真实的商业环境里铺开。
V4-Pro 以 1.6T 的总参数和 49B 的激活参数把容量拉到了顶。但真正的大招,是那个只有 284B 总参数、13B 激活参数的 V4-Flash。
文档里的一个数据直接戳破了行业的窗户纸:在大量极具挑战性的测试中,只有13B 激活参数的 Flash-Base,直接超越了上一代 37B 激活参数的 V3.2-Base。
13B 的极小激活代价,绝不是能力缩水,而是一次底层的效率重构。Flash 的意义,不是为了证明它能有多省钱,而是为了证明 「算力霸权是可以被架构重构打破的」。
参数规模,已经彻底失去决定性意义。
调度能力,正在取代参数,成为新的主战场。这让百万上下文不再是高阶英伟达集群的专属玩具,国产芯片也能顺畅地接管战局。未来开源模型的分水岭,不再是看谁的底座大,而是看谁能用十分之一的力气干同样的活。
专家和稀泥,不如各管一段
硬件效率是一面,另一面是软件效率。V4 在'后训练'阶段也换了一条路。
大模型的「后训练」 阶段,过去一直走在一条死胡同里。
行业惯用的混合强化学习 (Mixed RL),说的直白点,就是和稀泥。如果你想让模型既懂微积分,又会写C++,还能做日常规划时,传统的做法是把所有的参数强行往中间捏。结果就是 「向均值回归」。
强行捏在一起,特化能力全磨平了,最终只会均值化成平庸的通才。
V4 换了一条路。不是改良,是彻底换道。技术报告里交代了新解法:先独立培养专家。数学专家就只管算数,代码专家就只管编程。把单一维度的能力拉到满。
关键在于最后怎么合并。V4 不用业内泛滥的参数平均法,而是用了同策略蒸馏 (OPD)。
传统的权重合并是一种静态妥协,而OPD 是一场动态接管。
统一模型在自己生成轨迹时,遇到数学题,系统就精准引入数学专家的梯度来指路;遇到写代码,就无缝切给代码专家。大家各司其职,不在参数层面打架。
顺着这条线往下看,V4 应用端那个很火的 「三种推理模式」(无思考、高强度思考、极限思考),根本不是加了个 UI 按钮那么简单。它是 OPD 机制在产品端的直接变现。

在极限思考模式下,底层提示词会强制模型去分解问题、穷尽边缘情况。这种极其固执的死磕行为,恰恰是在OPD 阶段,在 「数学专家」 和 「编程专家」 的高强度捶打下固化下来的本能。
OPD 不搞平均。遇到数学题,接数学专家;遇到代码,接代码专家。各管一段,不在参数层面打架。
Agent 跑了三小时,不能失忆
换完训练方法,换应用场景,长上下文到底能干嘛?
如果只是为了在十万字的研报里找一句话,那不叫长上下文,那叫高级检索。真实的商业场景里,Agent 要替你重构代码、跨系统验证数据、甚至跑一整晚的流程。
在这个过程里,最致命的问题是「失忆」。
V3.2 有个让工程师极其头疼的痛点:新消息一进来,模型之前的思考痕迹直接清空。普通聊天这么干没问题,省资源。但如果是跑了三个小时的 Agent 任务,半路插进去一句话,模型脑子一白,整个状态全部丢失,得从头算。
这种链条断裂,在实际业务中直接接不住。
V4 给出的方案是 「交织思考」。逻辑很冷酷,分场景算账。
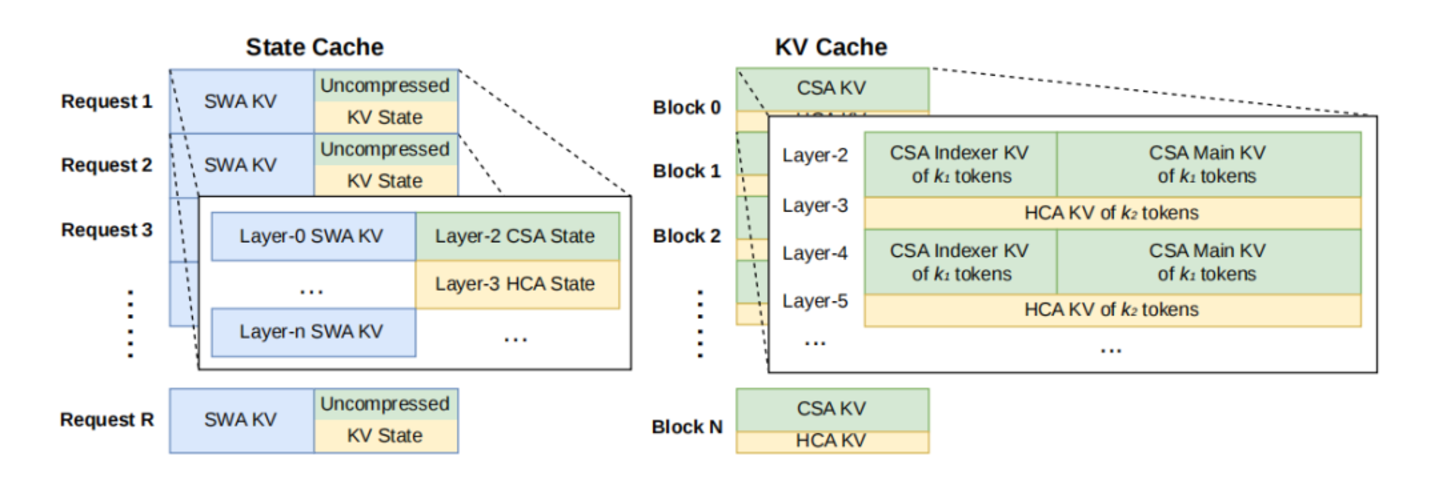
只要是带工具调用的长程场景,跨越消息边界,推理链条完整保留。如果是闲聊,继续清空,绝不多浪费一丁点算力。模型开始真正懂得「在什么场合,该记住什么」。
更绝的是它的快速指令 (Quick Instruction)。
以前行业里做意图识别,都习惯在外面挂个小模型。这意味着每次有新请求进来,不管长短,系统都得把用户的提示词重新嚼一遍。这本质上是在白白浪费预填充计算。
V4 没这么干。从其开源代码中可见:直接在输入序列末尾插几个隐式指令。主模型之前算好的海量特征 (KV Cache),直接复用。
长上下文的核心问题,从来不是「记得多」,而是 「算得起」。
这其实就是粗暴地砍掉了一次冗余的预填充计算。行业默认一个功能配一个小模型,V4 用行动证明:不用。KV Cache 复用吃透了,长程 Agent 才能跑起来。
完全缓存、定期存、不存,都疼
能跑不代表能卖。
第 17 页有个细节,自动生成的 kernel,跟手写 CUDA 逐位比对。不是差不多,是每一位都一样。这种工程洁癖,业务里少见。有这底线,才敢算部署账。

高并发的百万上下文,拼的根本不是大模型懂不懂人类,拼的是你懂不懂硬件的物理极限在哪。
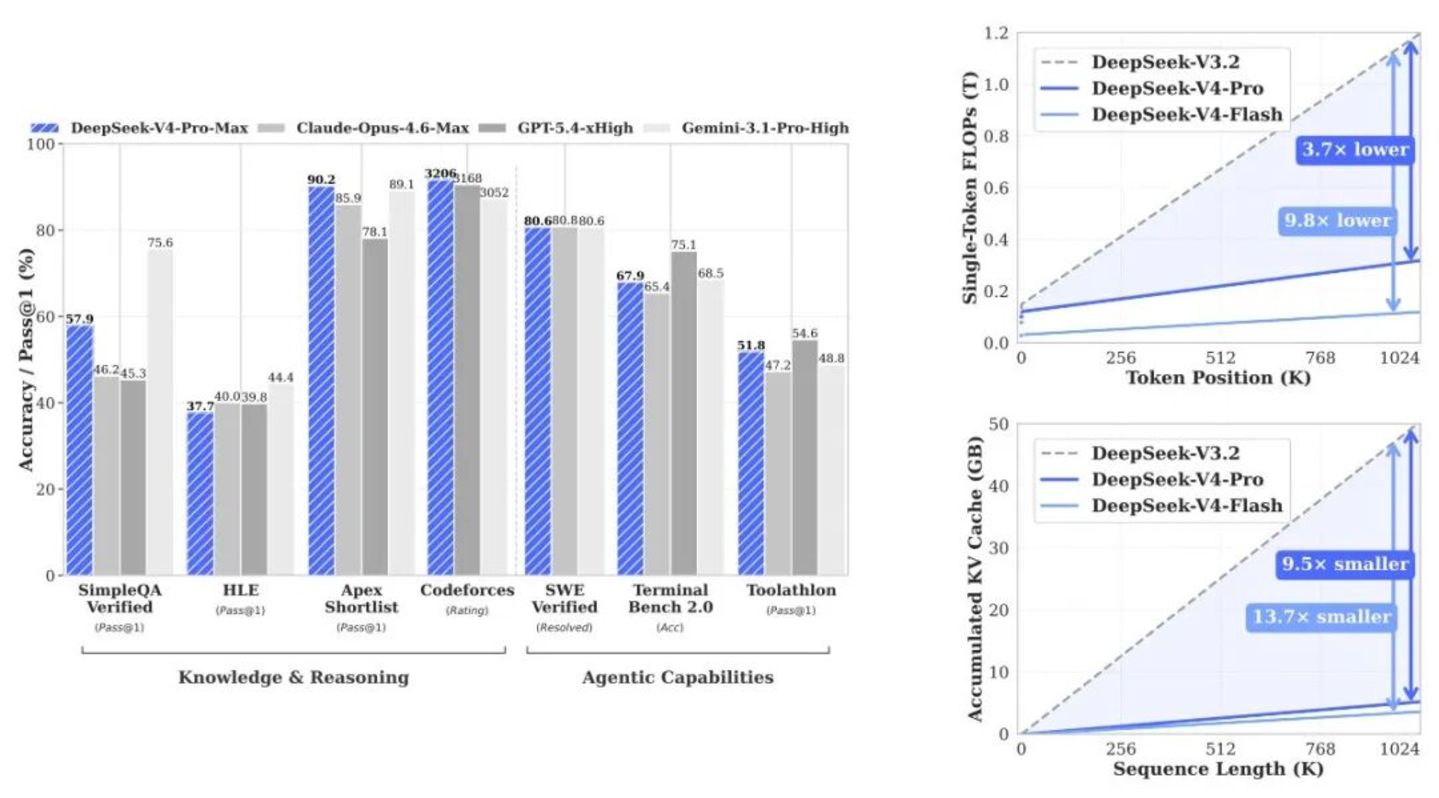
文档里三种调度策略都列出来了,没有藏着掖着,全是取舍。
想追求计算零冗余?上「完全缓存」。但代价是,固态硬盘的 I/O 通道可能在几秒钟内被高频写入直接挤爆。
想保护硬盘?上「定期检查点」。隔一段距离存一次。硬盘保住了,但 GPU 得时不时腾出算力来给丢失的尾部数据擦屁股。
要是干脆不上物理硬盘缓存呢?那就选「零缓存」。省下全部存储带宽,全靠长程特征做锚点,碰到问题 GPU 现场硬算。
这三条路,哪条都不是完美的。这本质上就是一场关于硬件寿命、并发峰值和用户延迟容忍度之间的极限算账。它把冷冰冰的现实摆在所有人面前:AI 早已不是单纯的算力密集型产业,它正在加速变成调度密集型产业。
写在最后
看DeepSeek V4,如果还停留在跑分榜上,那就连门槛都没摸到。
OPD 的能力动态接管,交织思考的记忆保留,砍掉预填充的快速指令,还有那些把硬盘和显存算计到骨头里的落盘策略。
这些枯燥的细节,其实是一根线上的蚂蚱。
大模型在变。
不再是陪聊的玩具。
而是开始接管真实世界的业务链条。
DeepSeek 不是在赌未来,它是在建机房。外界还在聊分数,分数只是机房运转时的副产品。
当对手还在为跑分榜上的零点几分沾沾自喜、向市场炫耀那几百亿参数时,DeepSeek 已经在算每百万 Token 的电费。
战局已经很清晰了:
下一场长文本战争,决胜点不是智商,是机房成本。