【TechWeb】3 月 27 日消息,2026 年 3 月,一场由 OpenClaw 引发的 「算力风暴」 席卷国内 AI 圈。短短一个月内,腾讯、阿里、百度、智谱等主流厂商相继宣布 AI 模型 API 价格上调,最高涨幅超过 460%。
当 「养龙虾」(调教自己的 OpenClaw 智能体) 成为热潮,Token 消耗从 「涓涓细流」 变成 「洪水猛兽」,如何在这场算力通胀中找到最经济的饲养方案,成了每个 AI 玩家不得不面对的课题。
龙虾火爆,Token 消耗何以剧增?
OpenClaw 的火爆并非偶然。与传统的 AI 对话应用不同,这类智能体具备自主规划、拆解任务、调用工具的能力。简单来说,普通对话是 「一问一答」,而 「龙虾」 会像一名真正的数字员工,在后台持续运转、反复思考、多次调用外部工具。
这种模式的 Token 消耗是惊人的。有业内人士测算,OpenClaw 执行一个中等复杂度的编程任务,消耗的 Token 量是同长度对话的 10 到 100 倍。猎豹移动 CEO 傅盛的个人 AI 助理日均消耗高达 100-200 美元,足见 「养虾」 的成本之高。
这种指数级的用量增长,直接触发了国内云厂商的算力成本压力。硬件层面,GPU、HBM 等核心部件供应链持续紧张、价格一路攀升;市场层面,AI 应用全面爆发,算力需求远超供给。供需失衡之下,涨价成为必然。
从 3 月中旬开始,各大厂商相继调整了 AI 模型 API 价格:
腾讯云:混元系列模型最高涨幅超 460%,从 0.0008 元/千 tokens 飙升至 0.004505 元/千 tokens,同时结束了多款第三方模型的免费公测。
阿里云:算力卡、文件存储产品上涨 5%-34%。(自 2026 年 4 月 18 日 00:00 起执行)
百度智能云:AI 算力相关产品上调 5%-30%。(自 2026 年 4 月 18 日 00:00 起执行)
智谱 AI:新推出的 GLM-5-Turbo API 价格较前代累计上涨 83%。
腾讯高管在财报电话会上直言:「供应商优先保障大客户,我们别无选择,只能将成本上涨转嫁至售价。」 这番话,道出了整个行业涨价的底层逻辑。
各家 「龙虾套餐」 价格大比拼
要回答"怎么养最划算",首先要弄清楚各家目前的价格体系。
当前市场上的 AI Token 定价大致可分为两类:一类是传统的按量付费 API(适合开发者灵活调用),另一类是专为 OpenClaw 场景诞生的 Coding Plan 订阅套餐 (适合"养虾"用户按月固定支出)。
传统按量付费 API 方面 (单位:元/百万 Token),以各家主力旗舰模型为例:阿里云 Qwen3-Max 输入约 2.4 元、输出约 9.6 元;百度文心 X1(推理型) 输入约 2 元、输出约 8 元;火山引擎豆包 Pro 输入约 4 元、输出约 16 元,但其轻量版 Lite 极为便宜 (输入 0.8 元、输出 2 元);腾讯云混元 HY2.0 涨价后输入约 3.2 至 4 元、输出约 8 至 16 元;MiniMax M2.5(思考型) 输入约 2.1 元、输出约 8.4 元;智谱 GLM-5 约输入 3.5 元、输出 14 元;Kimi K2.5 输入约 4 元、输出约 21 元。值得注意的是,腾讯云 Hunyuan-Lite 依然完全免费,阿里云 Qwen-Turbo 输入仅 0.3 元/百万 Token,是极致低价之选。
然而,对于"养龙虾"用户来说,纯按量计费是一条非常危险的路——OpenClaw 天然的多工具调用、长上下文、多流程执行特性意味着 Token 消耗完全不可控。一个简单任务消耗数百万 Token 的情况稀松平常,如果不加管控,"月薪两万养不起一只龙虾"绝非段子。
因此,Coding Plan 订阅套餐才是"养虾"的正确姿势,也是各厂商争夺最激烈的战场。
以下是截至 2026 年 3 月 26 日,TechWeb 统计的主流厂商的 「龙虾套餐」 及 API 价格对比:
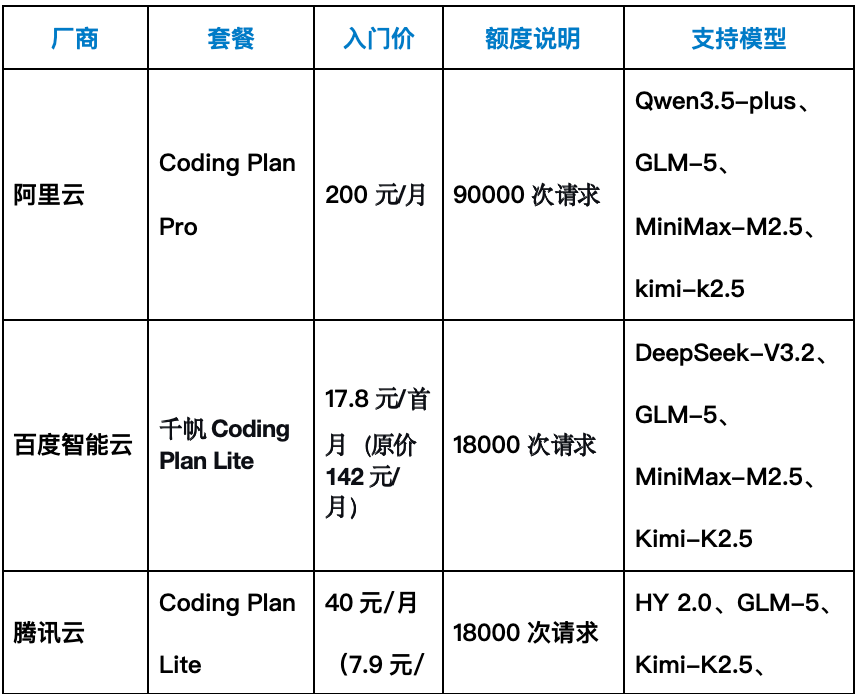
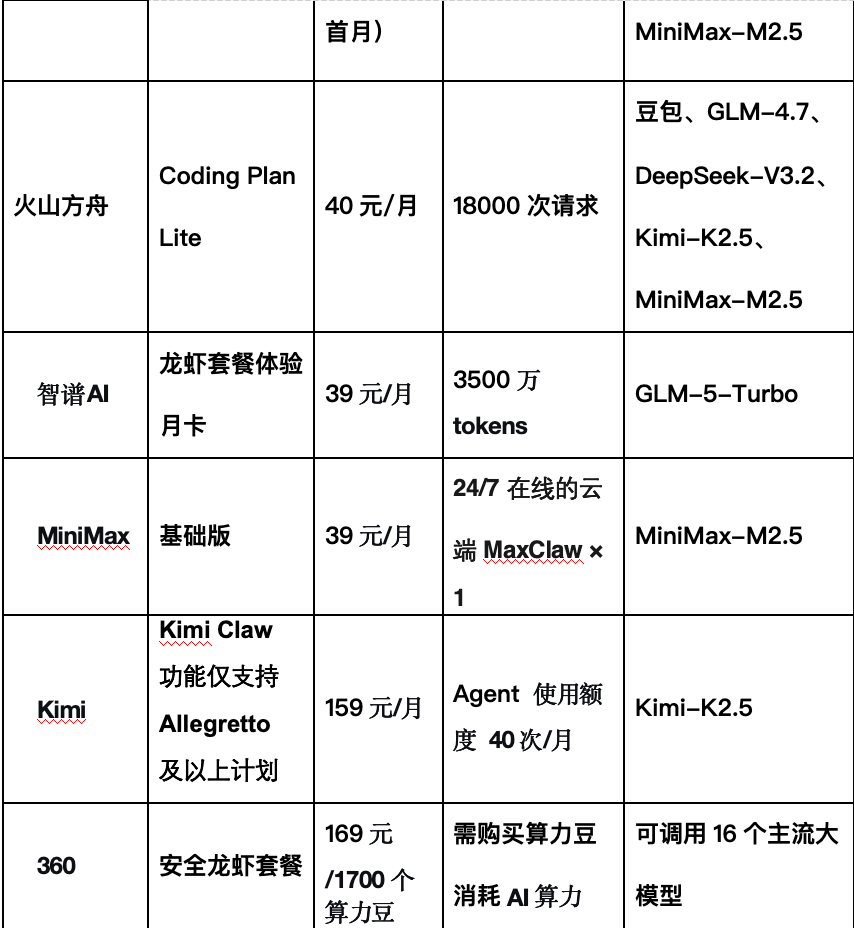
注:阿里云 Coding Plan Lite 版 3 月 20 日起已经停止新购。
三、怎么养龙虾最经济?
面对上述玲琅满目的套餐选择和差异化的计费模式,如何找到最适合自己的 「养虾」 方案?结合最新市场数据,总结出以下几大策略:
策略一:重度用户选阿里云 Coding Plan Pro
如果你属于重度用户,每日需要频繁调用模型进行编程、自动化任务,阿里云 Coding Plan Pro(200 元/月) 是目前市场上 「按次计费」 类套餐中容量最大的选择。
该套餐提供 90000 次请求/月的额度,折算日均 3000 次,足以支撑一个相当繁忙的 「龙虾」 持续运转。支持 Qwen3.5-plus、GLM-5、MiniMax-M2.5、kimi-k2.5 四款主流模型,覆盖了从通用对话到代码生成的多种场景。
成本测算:以 200 元/90000 次计算,单次请求成本约 0.0022 元。如果你的 「龙虾」 每次任务需要调用多次模型 (例如一个任务拆解为 5-10 步),这个成本结构依然可控。
适用人群:日均调用量在 1000 次以上、希望锁定固定成本的重度玩家。
策略二:多模型尝鲜者首选百度/腾讯/火山首月低价
如果你刚刚接触 OpenClaw,希望低成本体验不同平台的 「养虾」 效果,或者需要灵活调用多种模型来完成不同任务,百度、腾讯、火山方舟的首月优惠套餐是最佳入口。三家均提供 「Coding Plan Lite」 套餐,额度均为 18000 次请求/月,支持多款主流模型。
可以先把有首月优惠"薅一遍"。这个阶段的核心目标不是"用好",而是"搞清楚 OpenClaw 能帮自己做什么"。
可以依次购买三家首月套餐,用一个月时间充分体验不同模型的表现。腾讯云 7.9 元,百度千帆 17.8 元,火山方舟 40 元,首月总花费仅 7.9+17.8+40=65.7 元,即可获得 54000 次请求的体验额度,足够深度测试。搞清楚哪个平台、哪个模型最适合自己的工作场景,之后再做长期续费决策。
策略三:专用模型用户按需选择
如果你已经确定自己偏好某家模型,可以直接选择对应厂商的专用套餐。如智谱、MiniMax、Kimi 的龙虾套餐。
智谱 GLM 系列在智能体任务上有专门优化,适合需要复杂推理和工具调用的场景。Kimi-K2.5 模型在处理长上下文、复杂推理方面具有优势。适合需要处理超长文档、深度分析等高端任务的用户。
适用人群:对模型能力要求极高、且用量可控的高端玩家或专业人士。
策略四:一站式多模型需求选择 360
如果你需要在一个平台下灵活调用多达 16 个主流大模型,且不希望绑定单一厂商,360 安全龙虾入门套餐 (169 元/1700 个算力豆) 提供了独特的选择。
算力豆是 360 平台的通用算力单位,可兑换调用不同模型的额度。这种模式的最大优势是灵活性,你可以根据任务需求,在 16 个模型之间自由切换,而无需购买多个套餐。
适用人群:需要频繁切换模型、希望一站式管理的开发者。
写在最后:算力通胀时代的生存法则
OpenClaw 的火爆,本质上是 AI 从 「对话玩具」 进化为 「生产力工具」 的缩影。当 AI 开始替我们干活、替我们思考,算力成本就成了无法回避的现实。
在这场算力通胀中,没有永恒的 「免费午餐」,只有不断优化的成本策略。对于开发者而言,最经济的 「养虾」 方式不是死磕最低单价,而是:
1. 量体裁衣:先统计自己的实际用量,再选择匹配的套餐。
2. 组合使用:将按量计费与包月套餐结合,高峰期用套餐,低谷期用按量。
3. 关注缓存:Kimi 等平台支持上下文缓存,命中后成本大幅降低。
4. 动态调整:AI 行业变化极快,每月复盘一次用量和成本,及时切换最优方案。
在这个日新月异的行业里,今天的 「最划算」 可能很快被明天的新套餐取代。保持关注,灵活应对,才能让你的 「龙虾」 既吃饱、又吃好。
另外,附赠一些省钱技巧:
根据"养虾烧 1 亿 Token"后总结的社区实战经验,以下几条省钱操作能将 Token 消耗从 100% 压到 30% 以内:
1、一个任务一个会话:做完就输入/compact(压缩上下文) 或/new(新开对话),绝不在一个长会话里跨任务混聊。长会话是 Token 黑洞。
2、一次说清需求:在 OpenClaw 里,每"补一句"都等于重新跑一轮完整请求。与其"先分析一下"「继续」「展开」"改个标题"来回拉扯,不如一次性说清目标、格式和边界。
3、关闭 Thinking 模式:深度思考模式的输出量是普通模式的数倍乃至数十倍,非必要别开。
4、精简静态文件:AGENTS.md、SOUL.md、MEMORY.md 等工作区文件会在每一轮被注入系统提示,写得越长消耗 Token 越多。社区有人测出"工作区文件注入浪费了 93.5% 的 Token"。
5、后台自动化用轻量模型:Heartbeat、Cron 等后台任务默认会跑完整上下文,务必开启 isolatedSession 和 lightContext,并切换到便宜模型。

【TechWeb】3 月 27 日消息,2026 年 3 月,一场由 OpenClaw 引发的 「算力风暴」 席卷国内 AI 圈。短短一个月内,腾讯、阿里、百度、智谱等主流厂商相继宣布 AI 模型 API 价格上调,最高涨幅超过 460%。
当 「养龙虾」(调教自己的 OpenClaw 智能体) 成为热潮,Token 消耗从 「涓涓细流」 变成 「洪水猛兽」,如何在这场算力通胀中找到最经济的饲养方案,成了每个 AI 玩家不得不面对的课题。
龙虾火爆,Token 消耗何以剧增?
OpenClaw 的火爆并非偶然。与传统的 AI 对话应用不同,这类智能体具备自主规划、拆解任务、调用工具的能力。简单来说,普通对话是 「一问一答」,而 「龙虾」 会像一名真正的数字员工,在后台持续运转、反复思考、多次调用外部工具。
这种模式的 Token 消耗是惊人的。有业内人士测算,OpenClaw 执行一个中等复杂度的编程任务,消耗的 Token 量是同长度对话的 10 到 100 倍。猎豹移动 CEO 傅盛的个人 AI 助理日均消耗高达 100-200 美元,足见 「养虾」 的成本之高。
这种指数级的用量增长,直接触发了国内云厂商的算力成本压力。硬件层面,GPU、HBM 等核心部件供应链持续紧张、价格一路攀升;市场层面,AI 应用全面爆发,算力需求远超供给。供需失衡之下,涨价成为必然。
从 3 月中旬开始,各大厂商相继调整了 AI 模型 API 价格:
腾讯云:混元系列模型最高涨幅超 460%,从 0.0008 元/千 tokens 飙升至 0.004505 元/千 tokens,同时结束了多款第三方模型的免费公测。
阿里云:算力卡、文件存储产品上涨 5%-34%。(自 2026 年 4 月 18 日 00:00 起执行)
百度智能云:AI 算力相关产品上调 5%-30%。(自 2026 年 4 月 18 日 00:00 起执行)
智谱 AI:新推出的 GLM-5-Turbo API 价格较前代累计上涨 83%。
腾讯高管在财报电话会上直言:「供应商优先保障大客户,我们别无选择,只能将成本上涨转嫁至售价。」 这番话,道出了整个行业涨价的底层逻辑。
各家 「龙虾套餐」 价格大比拼
要回答"怎么养最划算",首先要弄清楚各家目前的价格体系。
当前市场上的 AI Token 定价大致可分为两类:一类是传统的按量付费 API(适合开发者灵活调用),另一类是专为 OpenClaw 场景诞生的 Coding Plan 订阅套餐 (适合"养虾"用户按月固定支出)。
传统按量付费 API 方面 (单位:元/百万 Token),以各家主力旗舰模型为例:阿里云 Qwen3-Max 输入约 2.4 元、输出约 9.6 元;百度文心 X1(推理型) 输入约 2 元、输出约 8 元;火山引擎豆包 Pro 输入约 4 元、输出约 16 元,但其轻量版 Lite 极为便宜 (输入 0.8 元、输出 2 元);腾讯云混元 HY2.0 涨价后输入约 3.2 至 4 元、输出约 8 至 16 元;MiniMax M2.5(思考型) 输入约 2.1 元、输出约 8.4 元;智谱 GLM-5 约输入 3.5 元、输出 14 元;Kimi K2.5 输入约 4 元、输出约 21 元。值得注意的是,腾讯云 Hunyuan-Lite 依然完全免费,阿里云 Qwen-Turbo 输入仅 0.3 元/百万 Token,是极致低价之选。
然而,对于"养龙虾"用户来说,纯按量计费是一条非常危险的路——OpenClaw 天然的多工具调用、长上下文、多流程执行特性意味着 Token 消耗完全不可控。一个简单任务消耗数百万 Token 的情况稀松平常,如果不加管控,"月薪两万养不起一只龙虾"绝非段子。
因此,Coding Plan 订阅套餐才是"养虾"的正确姿势,也是各厂商争夺最激烈的战场。
以下是截至 2026 年 3 月 26 日,TechWeb 统计的主流厂商的 「龙虾套餐」 及 API 价格对比:
注:阿里云 Coding Plan Lite 版 3 月 20 日起已经停止新购。
三、怎么养龙虾最经济?
面对上述玲琅满目的套餐选择和差异化的计费模式,如何找到最适合自己的 「养虾」 方案?结合最新市场数据,总结出以下几大策略:
策略一:重度用户选阿里云 Coding Plan Pro
如果你属于重度用户,每日需要频繁调用模型进行编程、自动化任务,阿里云 Coding Plan Pro(200 元/月) 是目前市场上 「按次计费」 类套餐中容量最大的选择。
该套餐提供 90000 次请求/月的额度,折算日均 3000 次,足以支撑一个相当繁忙的 「龙虾」 持续运转。支持 Qwen3.5-plus、GLM-5、MiniMax-M2.5、kimi-k2.5 四款主流模型,覆盖了从通用对话到代码生成的多种场景。
成本测算:以 200 元/90000 次计算,单次请求成本约 0.0022 元。如果你的 「龙虾」 每次任务需要调用多次模型 (例如一个任务拆解为 5-10 步),这个成本结构依然可控。
适用人群:日均调用量在 1000 次以上、希望锁定固定成本的重度玩家。
策略二:多模型尝鲜者首选百度/腾讯/火山首月低价
如果你刚刚接触 OpenClaw,希望低成本体验不同平台的 「养虾」 效果,或者需要灵活调用多种模型来完成不同任务,百度、腾讯、火山方舟的首月优惠套餐是最佳入口。三家均提供 「Coding Plan Lite」 套餐,额度均为 18000 次请求/月,支持多款主流模型。
可以先把有首月优惠"薅一遍"。这个阶段的核心目标不是"用好",而是"搞清楚 OpenClaw 能帮自己做什么"。
可以依次购买三家首月套餐,用一个月时间充分体验不同模型的表现。腾讯云 7.9 元,百度千帆 17.8 元,火山方舟 40 元,首月总花费仅 7.9+17.8+40=65.7 元,即可获得 54000 次请求的体验额度,足够深度测试。搞清楚哪个平台、哪个模型最适合自己的工作场景,之后再做长期续费决策。
策略三:专用模型用户按需选择
如果你已经确定自己偏好某家模型,可以直接选择对应厂商的专用套餐。如智谱、MiniMax、Kimi 的龙虾套餐。
智谱 GLM 系列在智能体任务上有专门优化,适合需要复杂推理和工具调用的场景。Kimi-K2.5 模型在处理长上下文、复杂推理方面具有优势。适合需要处理超长文档、深度分析等高端任务的用户。
适用人群:对模型能力要求极高、且用量可控的高端玩家或专业人士。
策略四:一站式多模型需求选择 360
如果你需要在一个平台下灵活调用多达 16 个主流大模型,且不希望绑定单一厂商,360 安全龙虾入门套餐 (169 元/1700 个算力豆) 提供了独特的选择。
算力豆是 360 平台的通用算力单位,可兑换调用不同模型的额度。这种模式的最大优势是灵活性,你可以根据任务需求,在 16 个模型之间自由切换,而无需购买多个套餐。
适用人群:需要频繁切换模型、希望一站式管理的开发者。
写在最后:算力通胀时代的生存法则
OpenClaw 的火爆,本质上是 AI 从 「对话玩具」 进化为 「生产力工具」 的缩影。当 AI 开始替我们干活、替我们思考,算力成本就成了无法回避的现实。
在这场算力通胀中,没有永恒的 「免费午餐」,只有不断优化的成本策略。对于开发者而言,最经济的 「养虾」 方式不是死磕最低单价,而是:
1. 量体裁衣:先统计自己的实际用量,再选择匹配的套餐。
2. 组合使用:将按量计费与包月套餐结合,高峰期用套餐,低谷期用按量。
3. 关注缓存:Kimi 等平台支持上下文缓存,命中后成本大幅降低。
4. 动态调整:AI 行业变化极快,每月复盘一次用量和成本,及时切换最优方案。
在这个日新月异的行业里,今天的 「最划算」 可能很快被明天的新套餐取代。保持关注,灵活应对,才能让你的 「龙虾」 既吃饱、又吃好。
另外,附赠一些省钱技巧:
根据"养虾烧 1 亿 Token"后总结的社区实战经验,以下几条省钱操作能将 Token 消耗从 100% 压到 30% 以内:
1、一个任务一个会话:做完就输入/compact(压缩上下文) 或/new(新开对话),绝不在一个长会话里跨任务混聊。长会话是 Token 黑洞。
2、一次说清需求:在 OpenClaw 里,每"补一句"都等于重新跑一轮完整请求。与其"先分析一下"「继续」「展开」"改个标题"来回拉扯,不如一次性说清目标、格式和边界。
3、关闭 Thinking 模式:深度思考模式的输出量是普通模式的数倍乃至数十倍,非必要别开。
4、精简静态文件:AGENTS.md、SOUL.md、MEMORY.md 等工作区文件会在每一轮被注入系统提示,写得越长消耗 Token 越多。社区有人测出"工作区文件注入浪费了 93.5% 的 Token"。
5、后台自动化用轻量模型:Heartbeat、Cron 等后台任务默认会跑完整上下文,务必开启 isolatedSession 和 lightContext,并切换到便宜模型。
Related articles

【TechWeb】3 月 27 日消息,2026 年 3 月,一场由 OpenClaw 引发的 「算力风暴」 席卷国内 AI 圈。短短一个月内,腾讯、阿里、百度、智谱等主流厂商相继宣布 AI 模型 API 价格上调,最高涨幅超过 460%。
当 「养龙虾」(调教自己的 OpenClaw 智能体) 成为热潮,Token 消耗从 「涓涓细流」 变成 「洪水猛兽」,如何在这场算力通胀中找到最经济的饲养方案,成了每个 AI 玩家不得不面对的课题。
龙虾火爆,Token 消耗何以剧增?
OpenClaw 的火爆并非偶然。与传统的 AI 对话应用不同,这类智能体具备自主规划、拆解任务、调用工具的能力。简单来说,普通对话是 「一问一答」,而 「龙虾」 会像一名真正的数字员工,在后台持续运转、反复思考、多次调用外部工具。
这种模式的 Token 消耗是惊人的。有业内人士测算,OpenClaw 执行一个中等复杂度的编程任务,消耗的 Token 量是同长度对话的 10 到 100 倍。猎豹移动 CEO 傅盛的个人 AI 助理日均消耗高达 100-200 美元,足见 「养虾」 的成本之高。
这种指数级的用量增长,直接触发了国内云厂商的算力成本压力。硬件层面,GPU、HBM 等核心部件供应链持续紧张、价格一路攀升;市场层面,AI 应用全面爆发,算力需求远超供给。供需失衡之下,涨价成为必然。
从 3 月中旬开始,各大厂商相继调整了 AI 模型 API 价格:
腾讯云:混元系列模型最高涨幅超 460%,从 0.0008 元/千 tokens 飙升至 0.004505 元/千 tokens,同时结束了多款第三方模型的免费公测。
阿里云:算力卡、文件存储产品上涨 5%-34%。(自 2026 年 4 月 18 日 00:00 起执行)
百度智能云:AI 算力相关产品上调 5%-30%。(自 2026 年 4 月 18 日 00:00 起执行)
智谱 AI:新推出的 GLM-5-Turbo API 价格较前代累计上涨 83%。
腾讯高管在财报电话会上直言:「供应商优先保障大客户,我们别无选择,只能将成本上涨转嫁至售价。」 这番话,道出了整个行业涨价的底层逻辑。
各家 「龙虾套餐」 价格大比拼
要回答"怎么养最划算",首先要弄清楚各家目前的价格体系。
当前市场上的 AI Token 定价大致可分为两类:一类是传统的按量付费 API(适合开发者灵活调用),另一类是专为 OpenClaw 场景诞生的 Coding Plan 订阅套餐 (适合"养虾"用户按月固定支出)。
传统按量付费 API 方面 (单位:元/百万 Token),以各家主力旗舰模型为例:阿里云 Qwen3-Max 输入约 2.4 元、输出约 9.6 元;百度文心 X1(推理型) 输入约 2 元、输出约 8 元;火山引擎豆包 Pro 输入约 4 元、输出约 16 元,但其轻量版 Lite 极为便宜 (输入 0.8 元、输出 2 元);腾讯云混元 HY2.0 涨价后输入约 3.2 至 4 元、输出约 8 至 16 元;MiniMax M2.5(思考型) 输入约 2.1 元、输出约 8.4 元;智谱 GLM-5 约输入 3.5 元、输出 14 元;Kimi K2.5 输入约 4 元、输出约 21 元。值得注意的是,腾讯云 Hunyuan-Lite 依然完全免费,阿里云 Qwen-Turbo 输入仅 0.3 元/百万 Token,是极致低价之选。
然而,对于"养龙虾"用户来说,纯按量计费是一条非常危险的路——OpenClaw 天然的多工具调用、长上下文、多流程执行特性意味着 Token 消耗完全不可控。一个简单任务消耗数百万 Token 的情况稀松平常,如果不加管控,"月薪两万养不起一只龙虾"绝非段子。
因此,Coding Plan 订阅套餐才是"养虾"的正确姿势,也是各厂商争夺最激烈的战场。
以下是截至 2026 年 3 月 26 日,TechWeb 统计的主流厂商的 「龙虾套餐」 及 API 价格对比:
注:阿里云 Coding Plan Lite 版 3 月 20 日起已经停止新购。
三、怎么养龙虾最经济?
面对上述玲琅满目的套餐选择和差异化的计费模式,如何找到最适合自己的 「养虾」 方案?结合最新市场数据,总结出以下几大策略:
策略一:重度用户选阿里云 Coding Plan Pro
如果你属于重度用户,每日需要频繁调用模型进行编程、自动化任务,阿里云 Coding Plan Pro(200 元/月) 是目前市场上 「按次计费」 类套餐中容量最大的选择。
该套餐提供 90000 次请求/月的额度,折算日均 3000 次,足以支撑一个相当繁忙的 「龙虾」 持续运转。支持 Qwen3.5-plus、GLM-5、MiniMax-M2.5、kimi-k2.5 四款主流模型,覆盖了从通用对话到代码生成的多种场景。
成本测算:以 200 元/90000 次计算,单次请求成本约 0.0022 元。如果你的 「龙虾」 每次任务需要调用多次模型 (例如一个任务拆解为 5-10 步),这个成本结构依然可控。
适用人群:日均调用量在 1000 次以上、希望锁定固定成本的重度玩家。
策略二:多模型尝鲜者首选百度/腾讯/火山首月低价
如果你刚刚接触 OpenClaw,希望低成本体验不同平台的 「养虾」 效果,或者需要灵活调用多种模型来完成不同任务,百度、腾讯、火山方舟的首月优惠套餐是最佳入口。三家均提供 「Coding Plan Lite」 套餐,额度均为 18000 次请求/月,支持多款主流模型。
可以先把有首月优惠"薅一遍"。这个阶段的核心目标不是"用好",而是"搞清楚 OpenClaw 能帮自己做什么"。
可以依次购买三家首月套餐,用一个月时间充分体验不同模型的表现。腾讯云 7.9 元,百度千帆 17.8 元,火山方舟 40 元,首月总花费仅 7.9+17.8+40=65.7 元,即可获得 54000 次请求的体验额度,足够深度测试。搞清楚哪个平台、哪个模型最适合自己的工作场景,之后再做长期续费决策。
策略三:专用模型用户按需选择
如果你已经确定自己偏好某家模型,可以直接选择对应厂商的专用套餐。如智谱、MiniMax、Kimi 的龙虾套餐。
智谱 GLM 系列在智能体任务上有专门优化,适合需要复杂推理和工具调用的场景。Kimi-K2.5 模型在处理长上下文、复杂推理方面具有优势。适合需要处理超长文档、深度分析等高端任务的用户。
适用人群:对模型能力要求极高、且用量可控的高端玩家或专业人士。
策略四:一站式多模型需求选择 360
如果你需要在一个平台下灵活调用多达 16 个主流大模型,且不希望绑定单一厂商,360 安全龙虾入门套餐 (169 元/1700 个算力豆) 提供了独特的选择。
算力豆是 360 平台的通用算力单位,可兑换调用不同模型的额度。这种模式的最大优势是灵活性,你可以根据任务需求,在 16 个模型之间自由切换,而无需购买多个套餐。
适用人群:需要频繁切换模型、希望一站式管理的开发者。
写在最后:算力通胀时代的生存法则
OpenClaw 的火爆,本质上是 AI 从 「对话玩具」 进化为 「生产力工具」 的缩影。当 AI 开始替我们干活、替我们思考,算力成本就成了无法回避的现实。
在这场算力通胀中,没有永恒的 「免费午餐」,只有不断优化的成本策略。对于开发者而言,最经济的 「养虾」 方式不是死磕最低单价,而是:
1. 量体裁衣:先统计自己的实际用量,再选择匹配的套餐。
2. 组合使用:将按量计费与包月套餐结合,高峰期用套餐,低谷期用按量。
3. 关注缓存:Kimi 等平台支持上下文缓存,命中后成本大幅降低。
4. 动态调整:AI 行业变化极快,每月复盘一次用量和成本,及时切换最优方案。
在这个日新月异的行业里,今天的 「最划算」 可能很快被明天的新套餐取代。保持关注,灵活应对,才能让你的 「龙虾」 既吃饱、又吃好。
另外,附赠一些省钱技巧:
根据"养虾烧 1 亿 Token"后总结的社区实战经验,以下几条省钱操作能将 Token 消耗从 100% 压到 30% 以内:
1、一个任务一个会话:做完就输入/compact(压缩上下文) 或/new(新开对话),绝不在一个长会话里跨任务混聊。长会话是 Token 黑洞。
2、一次说清需求:在 OpenClaw 里,每"补一句"都等于重新跑一轮完整请求。与其"先分析一下"「继续」「展开」"改个标题"来回拉扯,不如一次性说清目标、格式和边界。
3、关闭 Thinking 模式:深度思考模式的输出量是普通模式的数倍乃至数十倍,非必要别开。
4、精简静态文件:AGENTS.md、SOUL.md、MEMORY.md 等工作区文件会在每一轮被注入系统提示,写得越长消耗 Token 越多。社区有人测出"工作区文件注入浪费了 93.5% 的 Token"。
5、后台自动化用轻量模型:Heartbeat、Cron 等后台任务默认会跑完整上下文,务必开启 isolatedSession 和 lightContext,并切换到便宜模型。
【TechWeb】3 月 27 日消息,2026 年 3 月,一场由 OpenClaw 引发的 「算力风暴」 席卷国内 AI 圈。短短一个月内,腾讯、阿里、百度、智谱等主流厂商相继宣布 AI 模型 API 价格上调,最高涨幅超过 460%。
当 「养龙虾」(调教自己的 OpenClaw 智能体) 成为热潮,Token 消耗从 「涓涓细流」 变成 「洪水猛兽」,如何在这场算力通胀中找到最经济的饲养方案,成了每个 AI 玩家不得不面对的课题。
龙虾火爆,Token 消耗何以剧增?
OpenClaw 的火爆并非偶然。与传统的 AI 对话应用不同,这类智能体具备自主规划、拆解任务、调用工具的能力。简单来说,普通对话是 「一问一答」,而 「龙虾」 会像一名真正的数字员工,在后台持续运转、反复思考、多次调用外部工具。
这种模式的 Token 消耗是惊人的。有业内人士测算,OpenClaw 执行一个中等复杂度的编程任务,消耗的 Token 量是同长度对话的 10 到 100 倍。猎豹移动 CEO 傅盛的个人 AI 助理日均消耗高达 100-200 美元,足见 「养虾」 的成本之高。
这种指数级的用量增长,直接触发了国内云厂商的算力成本压力。硬件层面,GPU、HBM 等核心部件供应链持续紧张、价格一路攀升;市场层面,AI 应用全面爆发,算力需求远超供给。供需失衡之下,涨价成为必然。
从 3 月中旬开始,各大厂商相继调整了 AI 模型 API 价格:
腾讯云:混元系列模型最高涨幅超 460%,从 0.0008 元/千 tokens 飙升至 0.004505 元/千 tokens,同时结束了多款第三方模型的免费公测。
阿里云:算力卡、文件存储产品上涨 5%-34%。(自 2026 年 4 月 18 日 00:00 起执行)
百度智能云:AI 算力相关产品上调 5%-30%。(自 2026 年 4 月 18 日 00:00 起执行)
智谱 AI:新推出的 GLM-5-Turbo API 价格较前代累计上涨 83%。
腾讯高管在财报电话会上直言:「供应商优先保障大客户,我们别无选择,只能将成本上涨转嫁至售价。」 这番话,道出了整个行业涨价的底层逻辑。
各家 「龙虾套餐」 价格大比拼
要回答"怎么养最划算",首先要弄清楚各家目前的价格体系。
当前市场上的 AI Token 定价大致可分为两类:一类是传统的按量付费 API(适合开发者灵活调用),另一类是专为 OpenClaw 场景诞生的 Coding Plan 订阅套餐 (适合"养虾"用户按月固定支出)。
传统按量付费 API 方面 (单位:元/百万 Token),以各家主力旗舰模型为例:阿里云 Qwen3-Max 输入约 2.4 元、输出约 9.6 元;百度文心 X1(推理型) 输入约 2 元、输出约 8 元;火山引擎豆包 Pro 输入约 4 元、输出约 16 元,但其轻量版 Lite 极为便宜 (输入 0.8 元、输出 2 元);腾讯云混元 HY2.0 涨价后输入约 3.2 至 4 元、输出约 8 至 16 元;MiniMax M2.5(思考型) 输入约 2.1 元、输出约 8.4 元;智谱 GLM-5 约输入 3.5 元、输出 14 元;Kimi K2.5 输入约 4 元、输出约 21 元。值得注意的是,腾讯云 Hunyuan-Lite 依然完全免费,阿里云 Qwen-Turbo 输入仅 0.3 元/百万 Token,是极致低价之选。
然而,对于"养龙虾"用户来说,纯按量计费是一条非常危险的路——OpenClaw 天然的多工具调用、长上下文、多流程执行特性意味着 Token 消耗完全不可控。一个简单任务消耗数百万 Token 的情况稀松平常,如果不加管控,"月薪两万养不起一只龙虾"绝非段子。
因此,Coding Plan 订阅套餐才是"养虾"的正确姿势,也是各厂商争夺最激烈的战场。
以下是截至 2026 年 3 月 26 日,TechWeb 统计的主流厂商的 「龙虾套餐」 及 API 价格对比:
注:阿里云 Coding Plan Lite 版 3 月 20 日起已经停止新购。
三、怎么养龙虾最经济?
面对上述玲琅满目的套餐选择和差异化的计费模式,如何找到最适合自己的 「养虾」 方案?结合最新市场数据,总结出以下几大策略:
策略一:重度用户选阿里云 Coding Plan Pro
如果你属于重度用户,每日需要频繁调用模型进行编程、自动化任务,阿里云 Coding Plan Pro(200 元/月) 是目前市场上 「按次计费」 类套餐中容量最大的选择。
该套餐提供 90000 次请求/月的额度,折算日均 3000 次,足以支撑一个相当繁忙的 「龙虾」 持续运转。支持 Qwen3.5-plus、GLM-5、MiniMax-M2.5、kimi-k2.5 四款主流模型,覆盖了从通用对话到代码生成的多种场景。
成本测算:以 200 元/90000 次计算,单次请求成本约 0.0022 元。如果你的 「龙虾」 每次任务需要调用多次模型 (例如一个任务拆解为 5-10 步),这个成本结构依然可控。
适用人群:日均调用量在 1000 次以上、希望锁定固定成本的重度玩家。
策略二:多模型尝鲜者首选百度/腾讯/火山首月低价
如果你刚刚接触 OpenClaw,希望低成本体验不同平台的 「养虾」 效果,或者需要灵活调用多种模型来完成不同任务,百度、腾讯、火山方舟的首月优惠套餐是最佳入口。三家均提供 「Coding Plan Lite」 套餐,额度均为 18000 次请求/月,支持多款主流模型。
可以先把有首月优惠"薅一遍"。这个阶段的核心目标不是"用好",而是"搞清楚 OpenClaw 能帮自己做什么"。
可以依次购买三家首月套餐,用一个月时间充分体验不同模型的表现。腾讯云 7.9 元,百度千帆 17.8 元,火山方舟 40 元,首月总花费仅 7.9+17.8+40=65.7 元,即可获得 54000 次请求的体验额度,足够深度测试。搞清楚哪个平台、哪个模型最适合自己的工作场景,之后再做长期续费决策。
策略三:专用模型用户按需选择
如果你已经确定自己偏好某家模型,可以直接选择对应厂商的专用套餐。如智谱、MiniMax、Kimi 的龙虾套餐。
智谱 GLM 系列在智能体任务上有专门优化,适合需要复杂推理和工具调用的场景。Kimi-K2.5 模型在处理长上下文、复杂推理方面具有优势。适合需要处理超长文档、深度分析等高端任务的用户。
适用人群:对模型能力要求极高、且用量可控的高端玩家或专业人士。
策略四:一站式多模型需求选择 360
如果你需要在一个平台下灵活调用多达 16 个主流大模型,且不希望绑定单一厂商,360 安全龙虾入门套餐 (169 元/1700 个算力豆) 提供了独特的选择。
算力豆是 360 平台的通用算力单位,可兑换调用不同模型的额度。这种模式的最大优势是灵活性,你可以根据任务需求,在 16 个模型之间自由切换,而无需购买多个套餐。
适用人群:需要频繁切换模型、希望一站式管理的开发者。
写在最后:算力通胀时代的生存法则
OpenClaw 的火爆,本质上是 AI 从 「对话玩具」 进化为 「生产力工具」 的缩影。当 AI 开始替我们干活、替我们思考,算力成本就成了无法回避的现实。
在这场算力通胀中,没有永恒的 「免费午餐」,只有不断优化的成本策略。对于开发者而言,最经济的 「养虾」 方式不是死磕最低单价,而是:
1. 量体裁衣:先统计自己的实际用量,再选择匹配的套餐。
2. 组合使用:将按量计费与包月套餐结合,高峰期用套餐,低谷期用按量。
3. 关注缓存:Kimi 等平台支持上下文缓存,命中后成本大幅降低。
4. 动态调整:AI 行业变化极快,每月复盘一次用量和成本,及时切换最优方案。
在这个日新月异的行业里,今天的 「最划算」 可能很快被明天的新套餐取代。保持关注,灵活应对,才能让你的 「龙虾」 既吃饱、又吃好。
另外,附赠一些省钱技巧:
根据"养虾烧 1 亿 Token"后总结的社区实战经验,以下几条省钱操作能将 Token 消耗从 100% 压到 30% 以内:
1、一个任务一个会话:做完就输入/compact(压缩上下文) 或/new(新开对话),绝不在一个长会话里跨任务混聊。长会话是 Token 黑洞。
2、一次说清需求:在 OpenClaw 里,每"补一句"都等于重新跑一轮完整请求。与其"先分析一下"「继续」「展开」"改个标题"来回拉扯,不如一次性说清目标、格式和边界。
3、关闭 Thinking 模式:深度思考模式的输出量是普通模式的数倍乃至数十倍,非必要别开。
4、精简静态文件:AGENTS.md、SOUL.md、MEMORY.md 等工作区文件会在每一轮被注入系统提示,写得越长消耗 Token 越多。社区有人测出"工作区文件注入浪费了 93.5% 的 Token"。
5、后台自动化用轻量模型:Heartbeat、Cron 等后台任务默认会跑完整上下文,务必开启 isolatedSession 和 lightContext,并切换到便宜模型。