Related articles

作者 | AlphaEngineer

(1)Gemini 3's secret:Scaling is still a greenfield
Gemini 3 上线以来,几乎实现了全面屠榜,尤其在多模态和深度推理领域无人能敌。
我实测下来,Gemini 3 在投研领域比上一代模型而言,无论是推理深度、思考逻辑完备性、取数精准度等方面都有了不小的提升。
不久之后大家就能在我们的 AI 投研工具 AlphaEngine 上体验到我描述的感受。
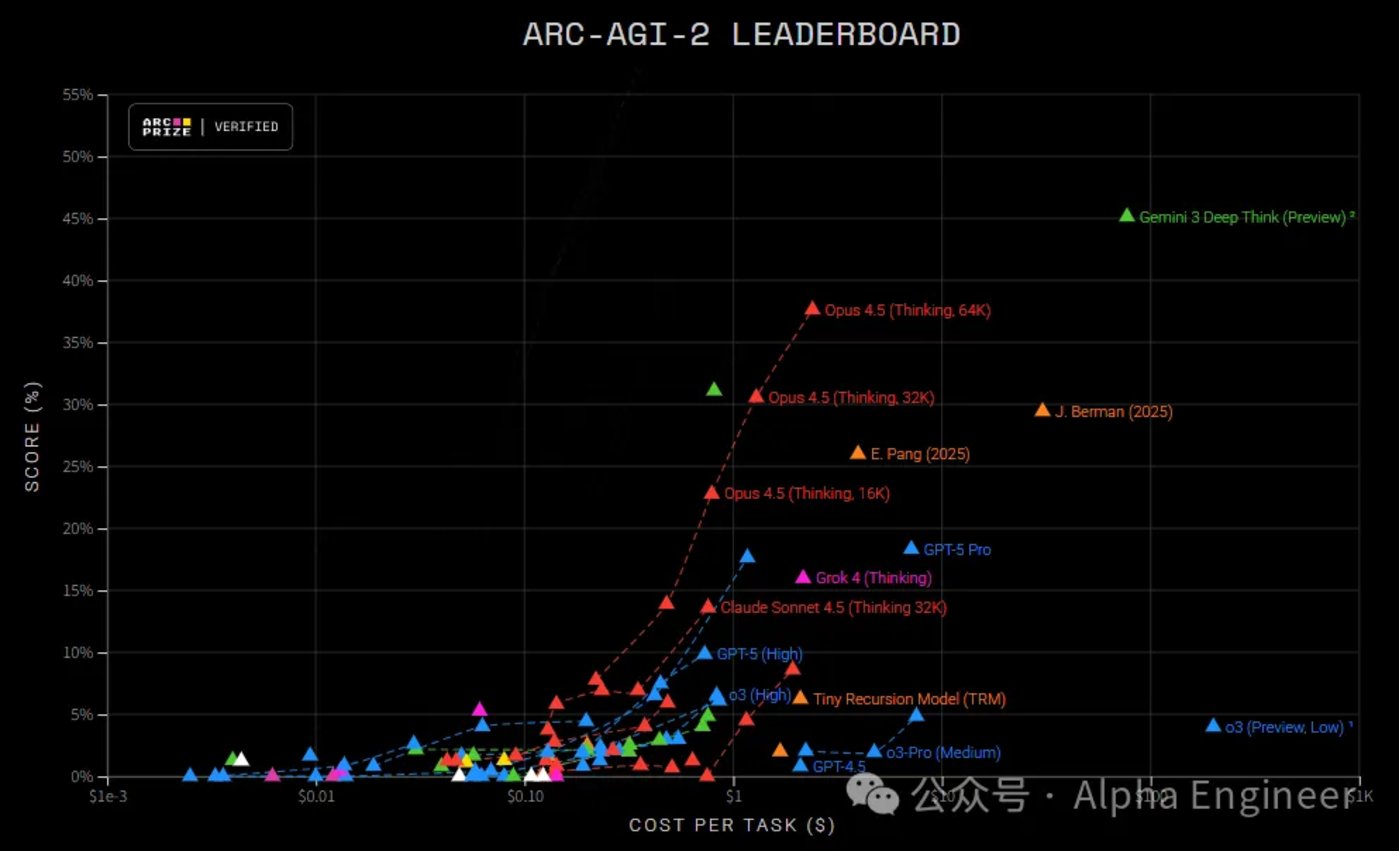
Gemini 3 为什么能取得这么大的突破?
来听听 Gemini 团队的负责人 Oriol Vinyals 的最新揭秘。
没错,Gemini 3 背后的秘密,就是预训练和后训练的 Scaling 仍然有着较大的空间。
朴素的答案往往最接近真相。
如果总结本轮 AI 革命的核心,那就是 「聚焦一点,登峰造极」。
GPT 模型的本质,是把 「智能」 抽象成 「根据上文预测下一个 token」。
在此基础上,不断扩大数据、算力,最后从这个简单到不能再简单的单一任务中,实现智能的泛化。
这是一种把一切非标复杂需求转化为简单标准任务的思想,是一种把一切问题转化成计算问题的哲学。
(2) 情感是人类内置的价值函数
昨天 Ilya 参加了一个访谈,干货很多。网上流传着一些 AI 会议摘要,存在着一定的误导性,建议大家都去听听原文,有不少 insights,这里我总结几个对我比较有启发性的观点,谈谈我的理解。
人类的学习方式和目前大模型的学习方式存在显著的差异,二者差异背后的原因,可能是下一轮 AI 算法创新的根源所在。
在被问到目前 Ilya 团队在 AI 算法创新上的最新进展时,Ilya 举了一个耐人寻味的例子。
多年前,Ilya 接触过一个因为脑损伤失去情感处理能力的个体。
正常人能够感知到的喜怒哀乐,他都感受不到。
我们可能以为,情感的缺失对日常生活影响不大,但是事实恰恰相反。
虽然这位患者能保持正常的语言能力,但他却在任何 decision-making 问题上,表现出极大的能力缺失。
比如他可能会因为挑选哪一双袜子而耗费数个小时,或者经常做出灾难性的财务决策。
因此 Ilya 提出一个猜想:如果把人类的学习过程类比为 RL 的话,情感 (emotion) 可能就是人类的 「内置价值函数」。
对于 AI 模型而言,价值函数的作用在于能够在解决任务的过程中,提供前置的反馈信号。
比如当你探索决策树的过程中,在 1000 步之后发现这条路径并不可行时,你会学到一个经验教训,下次遇到类似的问题时,即使在 1000 步之前,你也可以预见到 1000 步之后的结果,所以你会做出另一个选择。
这种 RL 中价值函数的学习反馈,在人类身上被归纳为 「经验教训」,具体体现为喜怒哀乐等 「情感表现」。
我再举个例子,假设你在工作生活中遇到一个烂人,最开始你可能没有明显的感受,但是随着相处的时间越来越久,你发现对方身上的存在种种问题,最终你决定远离他。
那么当你未来再遇到另一个人时,如果他身上有着和之前你接触过的烂人有着类似的品行特征时,你会不自觉的出现 「厌恶」 的情绪,驱使你直接远离他,而不用再像第一个人一样,相处几年后再做出远离的决定。
从个体的微观尺度上来看,这个过程是 「经验教训」 的总结与成长。
从人类的中观尺度上来看,这个过程是群体 「文化」 的传承与发展。
从生物的宏观尺度上来看,这个过程是 「进化」 中的优胜劣汰,适者生存。
(3)Benchmark 与现实的差距:泛化能力不足
Ilya 直言当前 AI 模型在各种 benchmark 上表现优异,甚至能轻松通过很难的测评集,但在实际任务中的表现却差强人意,二者形成了明显的矛盾。
以 coding 为例,虽然目前的大模型在 Aider、SWE 等有一定难度的 coding benchmark 上表现得非常好,但大家实际使用 AI 来 vibe coding 时,经常会遇到一些尴尬的情况。
比如,当你指出 AI 生成的代码存在某个 bug 时,模型会承认问题并尝试修复,但修复过程中往往会引入新的 bug。
当用户指出新 bug 时,AI 会承认错误,并恢复之前的旧 bug,导致新旧 bug 交替出现,让尝试 vibe coding 的工程师们十分苦恼。
大家只要试过 vibe coding,一定对 Ilya 的这段描述感同身受。
为什么会出现这种差异呢?Ilya 给了一个很形象的解释。
假设有两个学生,学生 A 以成为顶尖 coding 竞赛程序员为目标,通过 10000 小时的专项训练,不断刷题最终成为了顶尖竞赛高手。
学生 B 也想在竞赛中得奖,但他只用 100 个小时进行专项训练。
假如两位学生最后在竞赛中得分将近,那么谁在将来的职业发展上有更大的潜力呢?肯定是学生 B。
学生 A 通过高强度的专项训练,收集所有竞赛历史题目 (预训练)、做海量练习题 (后训练),虽然得到了高分,成为了优秀的竞赛选手,但这种高强度的专项训练未必能够泛化到其他任务上。
正是这种 「泛化能力」 的不足,导致大模型出现了 Benchmark 和实际任务表现的差异。
(4) 重新回归 The Age of Research
Ilya 将 AI 的历史发展分为三个阶段。
从 2012 年到 2020 年是 age of research。AlexNet、ResNet、Transformer 等重要的算法创新层出不穷,为 GPT 的出现奠定了理论基础。
从 2021 年至今是 age of scaling。随着 Scaling Law 的确认,scaling 成为所有 AI 大厂 「最安全」 的投入方向。
毕竟基础研究的投入产出不确定性太高了,你可能花了几个亿做研究,最后只打了个水漂。
但是在 Scaling 的叙事逻辑下,你只要花足够的钱堆算力,就大概率能得到一个更强大的模型,从而获得更大的商业竞争优势。
这种 Scaling 为王的气氛带动了 NVDA 的收入高增,也带动了全球 AI Capex 的狂潮,但这也导致了一个明显的问题:随着 Scaling 效果边际递减,AI 竞争逐渐趋于同质化。
在当下这个关键时点,Ilya 认为 26 年开始,整个 AI 产业将重新回归 age of research。
对于这个观点,我还是比较认同的。
虽然现如今的大模型 (如 gemini 3) 已经很强大了,也具备很高的经济价值,但要想实现 AGI,当前算法路径存在明显瓶颈也是不争的事实。
上次和我们 CTO 李渔博士讨论下一个 AI 重点突破可能在哪里,我们观点比较一致,那就是 「可持续学习」。
如果把人类比作大模型的话,我们的大脑其实是一台 「训推一体机」。
白天我们从花花世界中接触海量数据,晚上入眠后,我们的海马体将这些数据通过某种方式训练到 「大模型」 中。
第二天眼睛睁开时,我们的大脑模型更新完毕,可以用一个全新的大模型迎接新的一天。
Brand new day, brand new me.
这种生物内置的 「可持续学习」 的框架,对于目前的 LLM 而言,仍是一种奢望。
最近我们关注到一份 Google 的研究论文,就在试图解决 LLM 的可持续学习难题。

(5)Nested Learning:Google 向可持续学习发起的挑战
Google 在 11 月 7 日发表了一篇题为 「Nested Learning」 的研究成果,向大模型的 「可持续学习」 难题发起了挑战。
可持续学习可以定义为:模型在不遗忘旧知识的前提下,随着时间推移主动获取新知识和技能的能力。
在这一方面,人类大脑是公认的 「金标准」。
大脑实现可持续学习的秘诀在于 「神经可塑性」(neuroplasticity)。
这是一种神秘而强大的能力,使得人类能够根据新的经历和体验动态改变大脑结构。
人类有一种疾病叫做 「顺行性遗忘」(anterograde amnesia),它的症状体现为患者无法将短期记忆转化成长期记忆。
患有顺行性遗忘的人类,他的思考推理将永久被局限在当下的语境中。
这点和当前 LLM 的处境非常类似,它的知识仅限于 context window,以及预训练期间学到的静态信息。
为了让大模型学习新的知识,我们需要不断更新模型参数,但这经常会导致灾难性遗忘 (Catastrophic Forgetting),即学了新的忘了旧的。
从仿生学的角度来看,如何让大模型拥有类似人类大脑 「神经可塑性」 是一条值得深入的研究方向。
Google 这次提出的解决方案 Nested Learning 本质上是一种 「嵌套学习」 框架。
嵌套学习不再将单个 ML 模型视作一个连续的过程,而是将其看做一个由互相连接、多层级学习问题组成的统一系统,从而进行同步优化。

为了进行概念验证,研究团队设计了名为 Hope 的模型,它是基于 Titans 架构的一个变体。
具体来说,Titans 架构是一种长期记忆模块,其核心机制是根据记忆的 「惊奇度」(即意外程度) 来对记忆进行优先级排序。
尽管其记忆管理能力很强,但它只有两级参数更新,这导致它只能实现一阶 (first-order) 上下文学习。
相比之下,Hope 是一种自修正 (self-modifying) 的循环架构,与 Titans 不同,它能够利用无限层级 (unbounded levels) 的上下文学习,此外 Hope 还加入了 CMS(连续记忆系统) 模块,使其能够扩展并处理更大的上下文窗口。
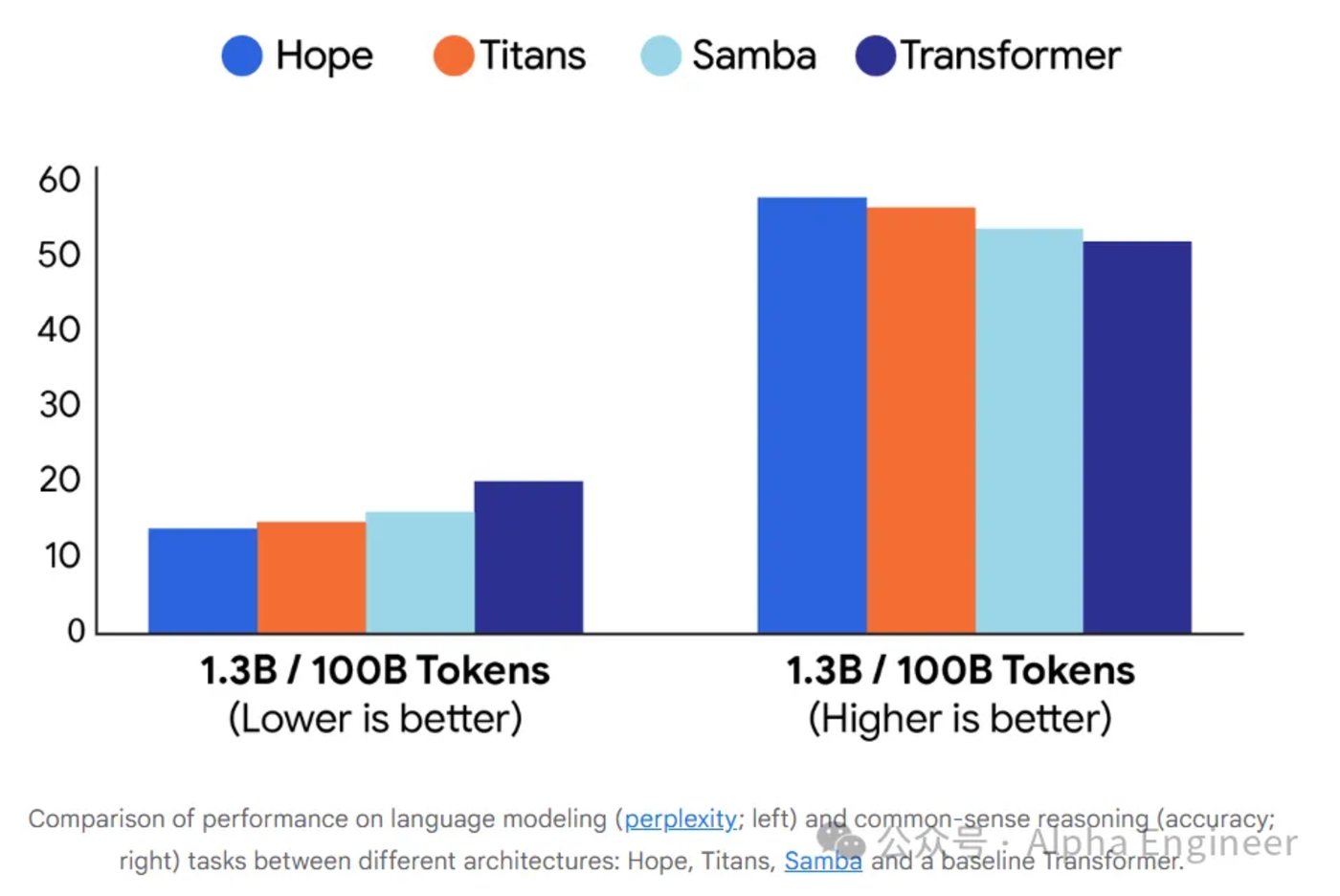
实验数据初步证实了嵌套学习的可行性,它把模型的 「网络架构」 和 「训练规则」 统一成了一个概念,把它们视作不同层级的优化任务,从而让大模型有机会解决灾难性遗忘问题,实现可持续学习。
(6) 结语:探索 AI 投研的有效前沿
Gemini 3、Nested Learning、可持续学习,以及之前我专门讨论过的 Rubin CPX 是近期特别值得关注的 AI 产业趋势。
我不是从投资的角度来探讨 「AI bubble」,而是从 AI 应用从业者的角度,提前规划明后年的产品形态。
我们的 AI 投研产品 AlphaEngine 目前服务于超过 70000 名专业的机构投资者。
AlphaEngine 的使命很简单,那就是让所有用户第一时间体验到全球最强的 AI 投研效果。