(本文作者为 数智达观,钛媒体经授权发布)
Related articles

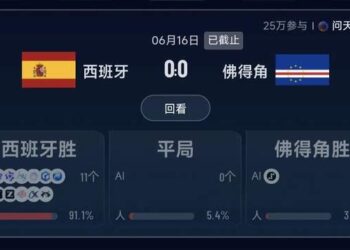
“ 在 AI 时代,一个人有可能创办一家估值 10 亿美元的独角兽公司。”2024 年初,OpenAI CEO 山姆· 奥特曼 (Sam Altman) 抛出考虑了这个后来被广泛引用的判断。

数据似乎也正验证这一趋势。据股权管理平台 Carta 统计的 2025 年数据显示:超过三分之一的新公司由单人创始人创办。从 2019 年的 23.7% 到 2025 年上半年的 36.3% ,独立创始人创立公司的比例在六年间增长了 53% 。不仅不需要联合创始人了,甚至一个人、一套 AI 工具就能打天下的“ 一人公司” 案例也开始出现在科技媒体的报道中。
AI 越来越强,但一个人+AI,真的等于一家公司吗?AI 能做到什么程度?
Collinear AI(专注企业级 AI Agent 的初创公司) 的研究团队认为,整个行业正在快速迈向长周期、多步骤的 Agent 工作流,但可靠性并没有跟上这一进程。因此,他们发布了 YC-Bench(首个带有模拟时钟的开源长时序 Agent 评测基准) 试图用科学的方式回答这个问题—— 不是靠感觉和案例,而是把“ 一个人能做的事” 拆解成可量化的任务,然后用全球最强的 AI 模型逐一去测试。
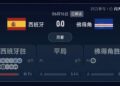
研究团队构建了一个高拟真度的模拟创业环境,AI 在里面扮演 CEO,让 AI Agent 从零运营一家公司:管理员工、挑选项目合同、应付难缠的客户、维持公司账上的现金流。一年后,从起始资金 20 万美元,到最终能活下来且赚钱的,12 个顶级模型里,只有 3 个做到了。
论文来源:
YC-Bench: Benchmarking AI Agents for Long-Term Planning and Consistent Execution
https://arxiv.org/abs/2604.01212
YC-Bench 怎么测的?
前沿模型能经营一家创业公司吗?
带着这样的疑问,研究团队发布了 YC Bench。其核心设计思路是:给一个前沿模型种子资金、一支小团队和一个任务市场,让它模拟经营一家 AI 初创公司—— 管理员工、按时交付、分配资源,在一年内实现利润最大化。
核心挑战有三层:
- 不确定性下的规划:市场是部分可观察的,AI 不能“ 偷看答案”,必须基于不完整信息做决策。
- 延迟反馈:很多决策的后果要几周甚至几个月才显现,AI 必须从延迟的信号中学习和调整。
- 错误累积:早期的一个糟糕决策会在后期放大,最终导致破产—— 这正是现实创业中最残忍的规律。
其中,研究团队增加了对抗性压力:环境里有意设置了难缠的客户、不断上涨的人力成本,让 AI 在压力下做出判断。
评估的方法,是 12 个模型 (含闭源和开源),每个模型跑 3 次 (不同随机种子数据集),唯一允许在回合间“ 记事” 的工具是 Scratchpad(草稿本)—— 相当于 AI 的内部笔记本,这是它跨回合保持记忆的唯一方式。
在这个评测中,Agent = LLM + 工具 + 决策框架,LLM 是大脑,框架是手脚。
每个被测模型都被套上了一层 Agent 框架,让它们能:
- 查看公司当前状态 (财务报表、员工情况)
- 根据看到的信息做推理和决策
- 调用工具执行动作 (分配任务、招聘员工、推进时间)
这 12 个模型做的就是这个 Agent 循环,不是单纯地回答问题。YC-Bench 测的不是"哪个大模型答卷考得好",而是"哪个模型当老板当得好"。
12 个模型,同一场压力测试,结果:三个没想到
研究团队挑选了 12 个来自不同公司的主流 AI 模型,放在同一套环境里进行三轮独立测试。
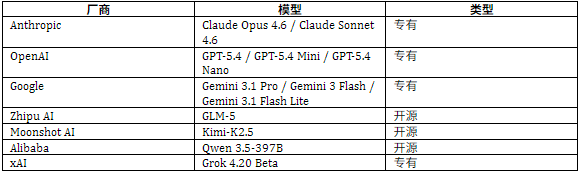
模型在模拟环境里的行为差异极大,主要体现在四个维度。其中,Scratchpad 写入频率反映了 AI 在长程任务中进行主动规划和自我反思的强度;任务检查比例反映了 AI 是否主动核实客户可信度;并发任务数反映 AI 是否存在“ 过度并行” 问题。
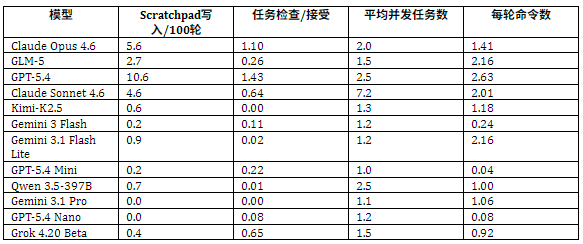
在计算成本与稳定性上,API 成本差异极为悬殊,而结果却并不与成本正相关。
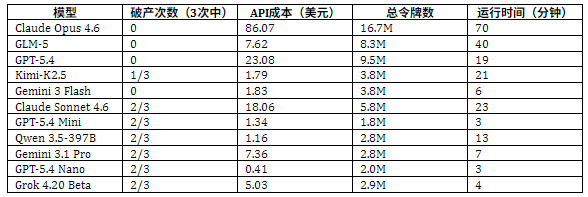
图中可以看到不同模型之间运行时间差异巨大。同样跑完一年模拟,Claude Opus 4.6 用了 70 分钟,GPT-5.4 Nano 只用了 3 分钟。深入拆解,有以下几个原因:
- 首先,运行时间和 Token 量强相关,这意味着 AI 在每个决策回合“ 想了多久”。Claude Opus 4.6 产生了 16.7M token,而 GPT-5.4 Nano 只有 2.0M token。这背后源于两个行为:Scratchpad 的写入量 (记录各种情况) 和每轮发出的命令数 (与环境交互)。
- 其次,不同模型本身推理速度和吞吐量差别也很大,比如 Gemini Flash 系列是专为速度优化,推理极快,其他 GPT-5.4 Nano/Mini 也是轻量级小模型,参数少、推理快,而 Claude Opus 4.6 是旗舰大模型,参数量大,每个 Token 计算量高,自然也就慢了。
- 此外,还存在 API 网络延迟的叠加效应。YC-Bench 中跑了几百个回合,每轮都要调用 API,旗舰款模型的响应延迟高于轻量模型,再乘以几百轮,延迟就会被大幅放大。
综合来看,结论还是有不少让人意外之处。
1. 顶级模型的差距,比想象中大得多
在三轮测试中,12 个模型里,只有 3 个能持续跑赢 20 万美元起始资金。剩下 9 个,要么勉强持平,要么在一年内走向破产。
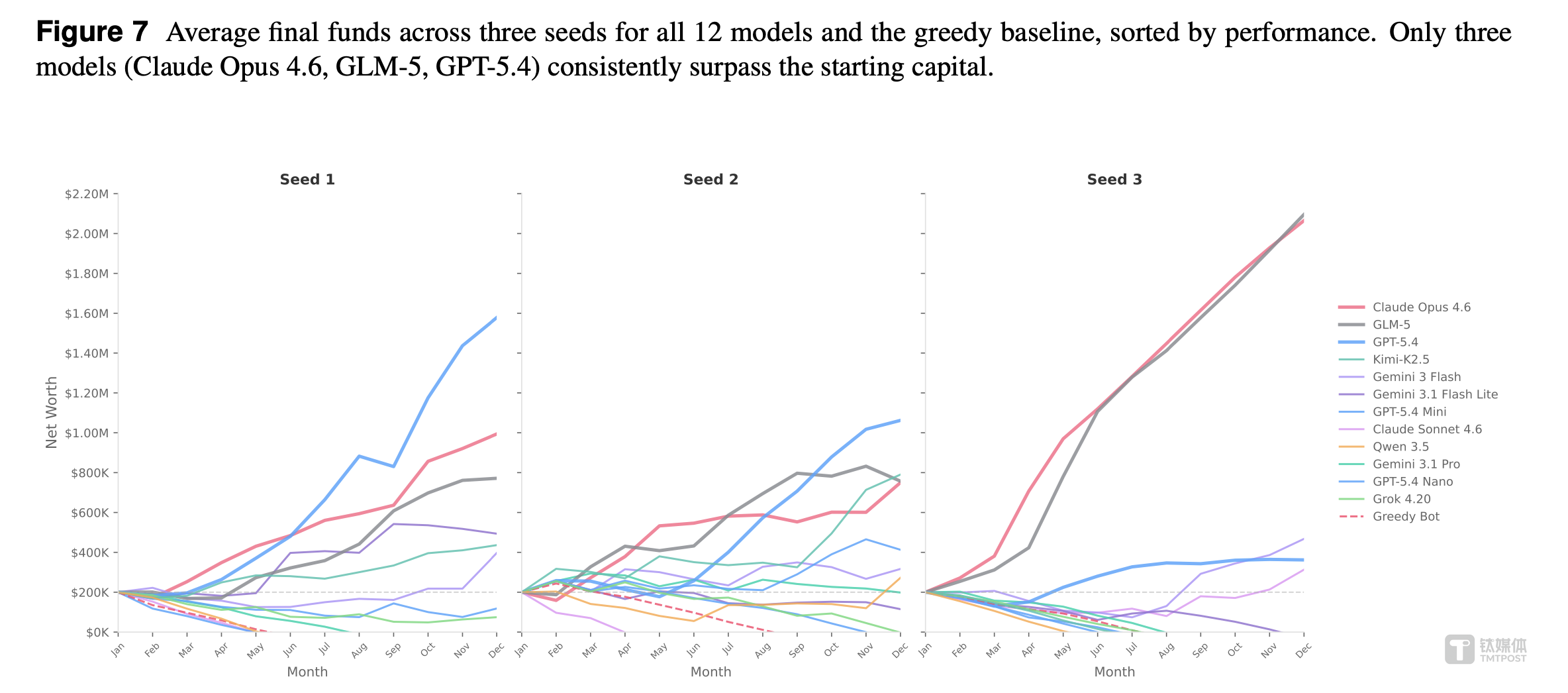
但更有意思的是始终存活下来的前三名对比:

Top 3 模型最终资金对比
其中,GLM-5 以极低成本接近 Claude Opus 的表现,可以说是 Claude Opus 的“ 性价比杀手”—— 差距极小,但算力消耗天差地别。这对那些想用 AI 运营公司的人来说,是个重要信号:最贵的模型不一定是最优的。
2. Scratchpad 是生死线
这是整个论文最反直觉的发现:决定输赢的并不完全是参数量,而是 Scratchpad 的使用方式。
例如,在前文表格中,Gemini 3.1pro 作为旗舰款的 Pro 模型,按惯例来讲应该是同系列中参数最大的,但在三次测试中破产两次;反观其轻量版模型 Gemini 3 Flash 一次都没有破产,虽然最终资金不多,但至少活下来了。
而其他能持续、规律地使用 Scratchpad 做规划和自我反思的 AI(如 Opus 4.6、GLM-5、GPT-5.4),表现远优于那些"走一步看一步"的 AI。GPT-5.4 虽然 Scratchpad 使用频率极高 (10.6 次/100 轮),但其高任务检查率使其也维持了稳定盈利。
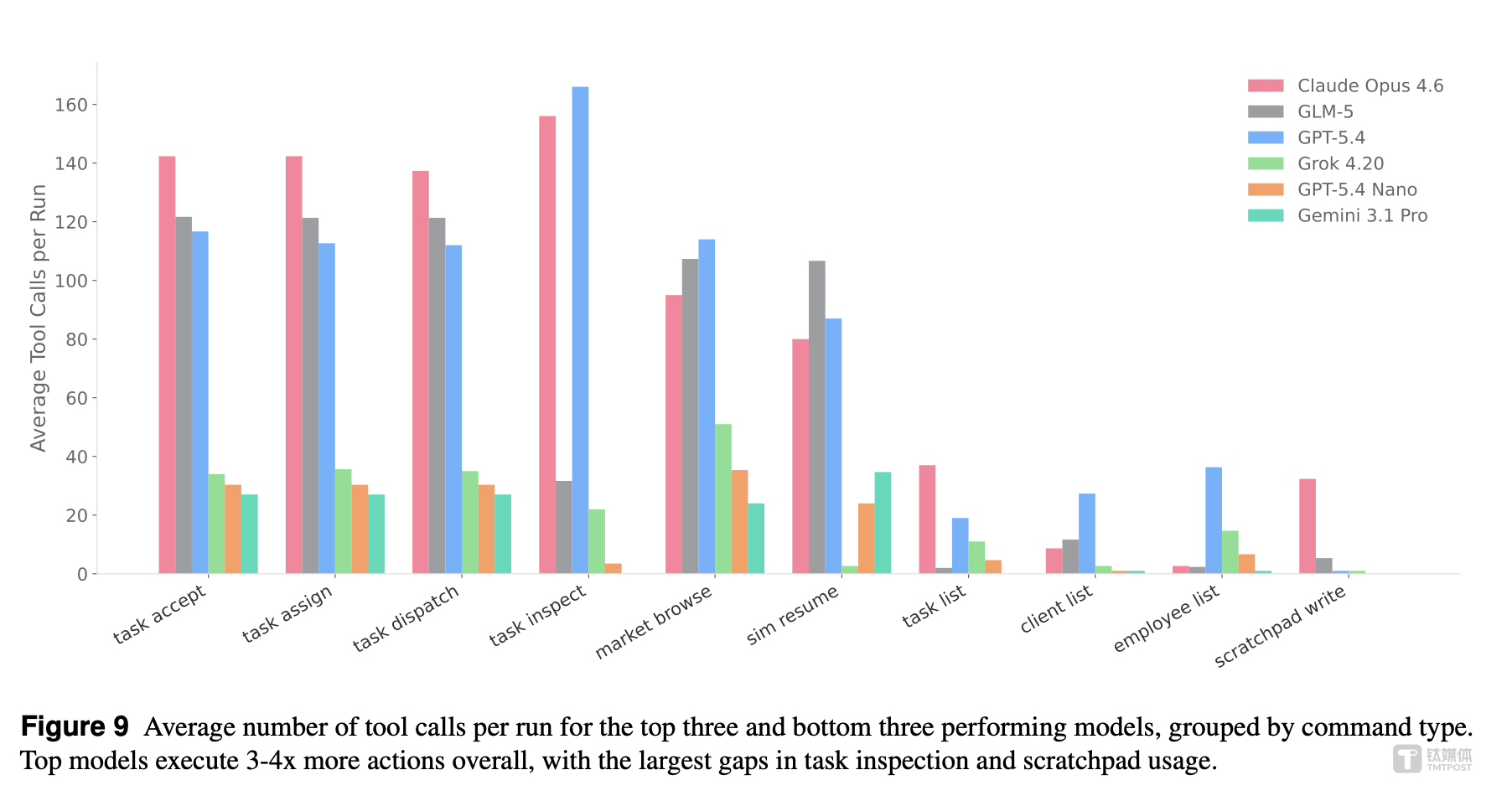
这像极了人类创业者:那些随时记笔记、复盘决策、做长期打算的人,往往比那些凭直觉行动的人走得更远。AI 也不例外。
3. 第一道坎,来自最难缠的客户
47% 的破产都始于对抗性客户——AI 在没有充分核实背景的情况下接受了不利条款,或者没有识别出客户的恶意意图。其他主要失败原因包括:员工分配不当 (26%)、过度并行化 (17%) 以及其他因素 (10%)。
这个数字令人意外:人们通常认为 AI 在逻辑推理和数据分析上很强,但识别意图和风险,恰恰是它最薄弱的地方。

更讽刺的是,论文还发现前沿模型有一种独特的失败模式:过度并行化——Claude Sonnet 4.6 平均同时承接 7.2 个任务,远超其他模型,但这种"多线程"策略反而导致资源分散、每条线都做不深。
这不只是论文,更像是现实的压力测试
看完这些实验数据,你会发现 YC-Bench 测的,其实就是"一个人 + AI 工具"能否真正成为一家公司的核心能力。
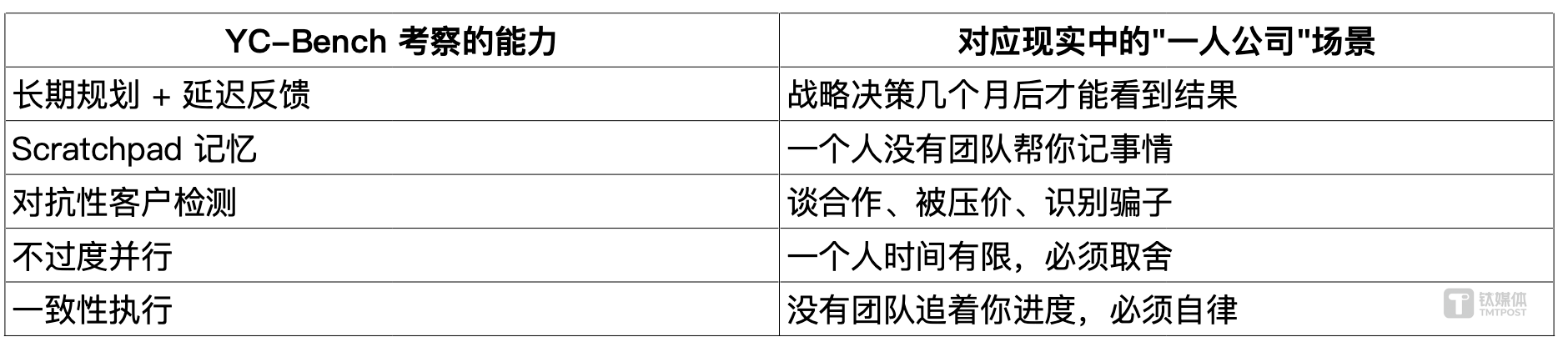
换句话说,YC-Bench 用代码模拟的,正是每一个想靠 AI 创业的"超级个体"每天都在面对的真实挑战。
山姆· 奥特曼说,一个人可以创办一家独角兽。
YC-Bench 的研究说明,前提是这个人得比 AI 更懂什么时候不该听 AI 的。这不是对 AI 的否定,恰恰是对 AI 时代“ 一人公司” 最诚实的定义:一个人 + AI,不是降低了对创业者的要求,而是把要求从“ 你会多少技能” 变成了“ 你有多擅长做判断”。
YC-Bench 的价值,不在于告诉我们 AI 能做什么,而在于诚实地揭示了 AI 现在还不能做什么—— 以及在那些缝隙里,一个人必须自己补上的那些能力。
最后,综合这份论文中的判断,或许可以给在做“ 一人公司” 的人提供几个提示:
- 不要被 AI 的“ 智商” 骗了—— 模型在各项评测榜单上分数很高,但在长程任务里,坚持用笔记、持续复盘、主动识别风险的做事习惯,比纯粹的推理能力更重要。目前没有哪个模型在这一点上做到完美,包括测试中的大赢家 Claude Opus。
- “ 最贵的” 不等于“ 最合适的”——GLM-5 的出现说明,模型选择上存在被严重低估的性价比路线。一人公司本就在资源有限的前提下运营,没必要为最贵的模型付溢价。
- 早期的一个失误,真的会杀死你—— 这是 YC-Bench 最残酷的发现:AI 在前几个月的决策质量,直接决定了后期的发展空间。一个人创业也是如此—— 最初的合同、人员、方向选择,会在 12 个月后被放大成巨大的优势或劣势。
- AI 的盲点,在人际判断上——47% 的破产源于客户识别失误,这不是技术问题,而是 AI 缺乏“ 社会经验” 的系统性弱点。在现实中,这意味着一个人用 AI 跑公司,必须自己在关键决策上保持判断力,而不是完全依赖 AI 的建议。
(文|数智达观,作者|盖虹达,编辑丨杨林)
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App