文 | 新立场 Pro
在 DeepSeek-R1 发布一周年之际,《新立场》 注意到,DeepSeek 在 GitHub 上更新了大量 FlashMLA 代码。在 114 个文件中,一个标有“MODEL1” 的未知大型模型标识符出现了 28 次。
Related articles


该标识符与现有模型“V32”(DeepSeek-V3.2) 一起提及并明确区分。根据对代码的上下文分析,“MODEL1” 被广泛认为代表了建立在不同架构上的新模型,而不是当前一代的次要迭代。

1 月 21 日,更多的信号浮出水面。多方消息源指出,DeepSeek 可能会在 2 月中旬农历新年期间推出其下一代旗舰人工智能模型 DeepSeek V4,新模型伴随针对 KV 缓存的新优化,且有望提供显著增强的编码能力。这意味着,DeepSeek 正试图在算力效率与编码能力上,再次拉高行业的“ 及格线”。
这种技术上的步步紧逼,让 2023 年那个热钱涌动的“ 镀金时代” 显得尤为遥远。
彼时,以智谱 (GLM)、月之暗面 (Kimi) 为代表的“ 六小龙” 正如日中天。凭借着“ 中国版 OpenAI” 的技术叙事和先发优势,智谱在一年内市值翻了三倍,月之暗面更是完成了 4 轮融资,以 33 亿美元的估值站在了聚光灯的中心。那时的市场相信,只要遵循“Scaling Law” 堆砌算力和参数,就能跑出下一个巨头。
2025 年 1 月 20 日,DeepSeek-R1 的发布成为了一道分水岭。其以一种极其极客、甚至有些“ 反商业” 的姿态—— 开源、低成本、高性能,瞬间抹平了“ 六小龙” 积攒了两年的先发壁垒。不仅大厂感到错愕,创业公司的护城河也一夜干涸。
DeepSeek 仅用了半年时间,就用极致的扩展效率击穿了行业虚高的估值泡沫。对于创业者而言,通用的路被堵死了,资本的耐心也随之耗尽。
但巨鲸没有胃口吞下所有浮游生物。其转身给应用层留下了最后一口氧气。
随着下半年 DeepSeek 进入“ 刻意” 的低调期,以及大厂生态竞争的白热化,处于夹缝中的“ 六小龙” 反而在绝境中找到了一种 "Product-Market Fit by Default"(被迫的市场匹配),即放弃对“ 全知全能” 通用大模型的执念,转而将 Context 极度聚焦,深耕特色垂直场景。
如今,AI 行业从“ 百模大战” 进入了“ 阶级固化” 阶段。DeepSeek 负责定义智能的上限,不断拓展技术的边界;而“ 六小龙” 们则退守垂类,负责填充商业的下限,在具体的业务流中寻找生存的缝隙。
海啸过后的幸存者名单
2024 年前 8 个月,全球 AIGC 领域发生了 107 起融资事件,国内大模型赛道更是吸金无数,亿元级别的融资案高达 20 起。零一万物、百川智能、智谱 AI、阶跃星辰、月之暗面与 MiniMax,这些名字开始频繁出现在科技媒体的头条,被合并称作“AI 六小龙”。来自国际战投与东南亚财团的资金,似乎在印证着这个赛道不可限量的未来。
而在那场资本狂欢中,月之暗面无疑是最耀眼的明星。
不同于“ 国家队” 智谱在 B 端的稳扎稳打,杨植麟坚定地押注了 To C 赛道,试图用“ 技术+产品” 的双轮驱动复刻移动互联网的奇迹。红杉、小红书、美团、阿里等巨头争相入局,将这家成立不到一年半的公司推向了估值高地。2024 年 2 月,Kimi 的月活用户数逼近 300 万,是两个月前的 6 倍。
QuestMobile 的数据线也画出过一道昂扬的阳线:2024 年底,AI 原生 App 的月活规模突破 1.2 亿,同比增长 232%。其中豆包、Kimi、文小言月活跃用户规模分别为 7523 万、2101 万、1224 万。那也是“ 烧钱换增长” 逻辑依然奏效的最后时光。彼时的媒体确信,2025 年将是三强争霸的决战时刻。
历史的转折往往比剧本更有戏剧性。2025 年初,DeepSeek 如同一场没有预兆的海啸,率先打响了“AI 普惠” 的第一枪。
1 月中旬,DeepSeek 正式上线手机端 App,据相关数据,仅一个春节假期,其下载量便爆发式增长至 6400 万次,这几乎是同期国内其他 AI 应用周下载量总和的 6 倍。尽管“ 服务器繁忙” 的提示频繁弹出,但用户对 DeepSeek 的热情却高位不减,人们将其称为“DeepSeek 时刻”。
腾讯迅速跟进,微信与元宝纷纷接入 DeepSeek R1 模型,将这场关于推理模型的竞赛推向高潮。QuestMobile 的数据显示,DeepSeek App 的日活在 2025 年 2 月底突破 5000 万。在开源普惠效应的冲击下,原生 AI App 的行业格局被彻底颠覆:原有的座次被重排,Top 3 更迭为 DeepSeek、豆包与腾讯元宝。
DeepSeek 的威压之下,分化开始出现。零一万物率先选择了“ 务实”。它迅速将“DeepSeek Moment” 纳入企业服务的话术体系,成为“ 六小龙” 中第一家全面拥抱 DeepSeek、提供定制部署方案的公司。
在当时,零一万物还面临人才的流失,包括曹大鹏、戴宗宏在内的核心技术高管接连出走,模型预训练负责人谷雪梅也宣布离职。动荡同样发生在百川智能。2025 年 3 月,王小川在搜狗时期的老部下、负责大模型开发的联创陈炜鹏与焦可相继离开。
更残酷的数据体现在 C 端战场。《字母榜》 报道,2024 年曾单月投流过亿的月之暗面,在 2025 年 2 月按下了暂停键。在停止了投放,纯粹依靠自然流量之下,Kimi 的 MAU 从峰值 2024 年 Q4 的 3600 万 断崖式下跌至 2025 年 Q3 的 967 万。用户规模的差距,被巨头无情拉大。
萧条之下,剩下的智谱 AI、MiniMax、月之暗面、阶跃星辰四家,尽管没有公开爆出放弃预训练的消息,但其在追赶 OpenAI 的进度上都有了明显的下滑。
故事在下半场发生了微妙的变奏。取得现象级成功后,DeepSeek 并未乘胜追击扩大 C 端版图,而是选择了一条更纯粹的道路:收紧市场推广,专注于底层能力与开放生态建设。甚至有观点认为,它正在退回到“ 纯粹智力供应商” 的角色。
洗牌看似结束,但规则已被改写。生存下来的“ 小龙们” 被迫放弃了单纯依靠烧钱换增长的幻梦。在 Gross Margin(毛利率) 被 DeepSeek 永久性压低的新常态下,它们开始寻找新的生存缝隙:月之暗面聚焦 Agent 的产品化;智谱与 MiniMax 相继上市,向公开市场寻求资金与品牌背书。
市场上不再有关于“ 六小龙谁能成为下一个 OpenAI” 的猜测,纷纷讨论起一个关于“ 如何在巨头与开源的夹缝中,找到商业下限” 的现实故事。
标尺之下的繁花与喘息
从最新的研究成果来看,DeepSeek 依然是那个理想而坚定的技术信徒。
在其刚刚发布的论文 《基于可扩展查找的条件记忆:大型语言模型稀疏性的新维度》 中,DeepSeek 提出了 Engram 架构。旨在为现有 MoE(混合专家) 架构“ 减负”。

论文指出,Engram 将主干网络的早期层从繁重的静态模式重建任务中解放了出来。换句话说,以前的模型要花大量容量去“ 死记硬背” 静态知识,而现在 Engram 接管了这部分记忆,让早期层可以专注于语义理解。这相当于为推理任务有效地加深了网络,并通过预取机制实现了几乎零开销的访问。
长上下文 (Long Context) 的优势也因此变得显著。通过将本地短语的“ 粘合剂” 卸载到内存中,模型释放了宝贵的注意力机制,专注于捕捉那些遥远而隐秘的关联。在“ 大海捞针” 的多查询匹配测试中,结果从 84.2% 跃升至 97.0%。
在 《新立场》 看来,此次 DeepSeek V4 的专精化,也暗示了 Scaling Law 在通用领域的边际效应递减。DeepSeek 通过此举,实质上将自己定位为了“ 基础能力的供水厂”,而将那些复杂的、场景化的“ 产品定义权” 和“ 市场接触权”,慷慨地让渡给了下游。
这种在商业边界上的主动“ 退让”,映射出的恰是 DeepSeek 与众不同的企业文化,在国内互联网流量为王的语境下,这家公司有些过于“ 低调且任性”。
创始人梁文锋鲜少站在聚光灯下。有报道称,他不仅公开反对大语言模型收费,甚至对送上门的外部投资持有排斥态度。在社交媒体上,DeepSeek 技术团队的账号屈指可数,且几乎只讨论硬核技术,对常规的用户反馈显得有些“ 钝感”。正如周鸿祎一针见血的评价:梁文锋根本不想做 APP,他的心思全在 AGI(通用人工智能) 上。
这份“ 任性”,在 2025 下半年演变为一种“ 心系天下” 的开源普惠。同源数据显示,2025 年下半年,第三方托管的 DeepSeek R1 和 V3 模型使用量呈指数级上升。
各行各业争相接入,有人惊呼“ 混元、通义的‘ 智商’ 正在迎头赶上”,有人开发出了技术小白也能用的 AI 智能体,甚至有人将推理模型植入到了人形机器人的大脑中。
DeepSeek 的“ 胸怀” 也给了垂直整合者—— 即“ 小龙们” 一个 Product-Market Fit (被迫的市场匹配) 的窗口期。在此新命题下,幸存的玩家们依据自身禀赋,选择了差异极大的突围路径,最终在 2026 年初迎来了喘息之机。
月之暗面选择了“ 两手抓”。产品侧,Kimi 从 5 月开始高频推出 Researcher、OK Computer、Kimi Code 等 Agent 新品;人事侧,引入投资人背景的张予彤任总裁,统筹战略与商业化。
创始人杨植麟也不再言必称 OpenAI,他在年终信中写道,公司的目标是超越 Anthropic 成为世界领先的 AGI 公司。凭借“ 长文本+Agent” 的双轮驱动,月之暗面即将完成新一轮融资,估值攀升至 48 亿美元,这距离其刚刚完成 5 亿美元融资仅数周时间。
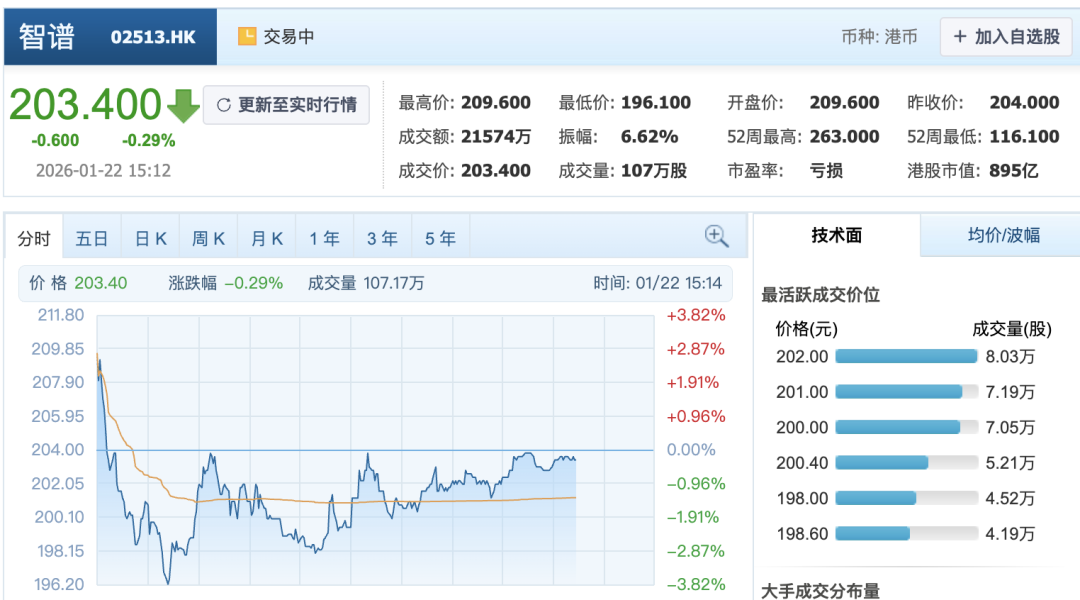
两家上市企业也登上了新的高度。截至发稿,智谱与 MiniMax 市值分别达到 895 亿与 1247 亿。上市解决了智谱持续研发的“ 弹药” 问题,首席科学家唐杰随即宣布全面回归基础模型研究,即将推出 GLM-5。
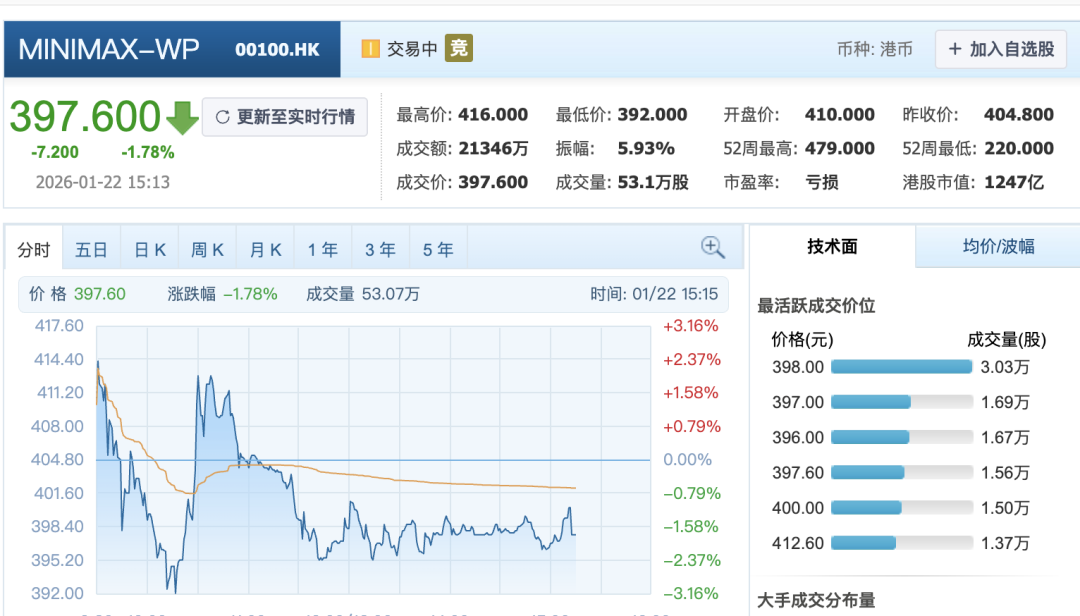
而估值领跑的 MiniMax 则在视频生成领域发力,其新一代模型 Hailuo 2.3 在物理动作与微表情上效果显著,同时推出了更低价的 Fast 版本,将批量创作成本砍半。
但这片应用层的“ 繁花似锦”,本质上完全仰赖于 DeepSeek 所划定的新标尺,DeepSeek 用开源和低价,无情地剥夺了中间商赚取“ 信息差” 的权力,迫使所有幸存者必须从“ 贩卖算力” 转向“ 贩卖价值”。
而在划定完这条红线后,DeepSeek 选择“ 高抬贵手”。
当然这并非出于商业上的仁慈,而更像是一种高维度的技术洁癖。在同行们还在为应用层的日活 (DAU) 沾沾自喜时,DeepSeek 已经转身,全力投身于那些更枯燥、更抽象、也更具决定性的难题—— 下一代稀疏架构的效率极限、推理强化的逻辑闭环、以及那个代号为“MODEL1” 的未知架构。
这种“ 不在场”,反而构成了一种更为强大的压迫感。对于整个 AI 行业而言,DeepSeek 平时静默无声,但它每一次参数的微调、每一篇论文的发布,都决定了生态圈里的空气是稀薄还是充沛,是晴空万里还是暴雨将至。
从这个意义上看,DeepSeek 更像是 AI 牌桌上发牌员手中那副不断变化的底牌。

写在最后
此外,《新立场》 捕捉到一条被忽视的暗线,DeepSeek 最新论文的核心思路是无限制地加大内存吞吐,这一思路,与大洋彼岸硅谷硬件巨头的顶层设计不谋而合。无论是谷歌 TPU 的双倍内存升级,还是英伟达下一代 Rubin 架构对上下文内存的堆砌,中美技术栈在解决瓶颈时达成了惊人的默契。
对于庞大的 MoE(混合专家) 模型而言,单纯依赖显存已是死胡同,大量采购 DRAM 进行混搭成为刚需。这也解释了为何沉寂多时的内存市场,会在最近年突然迎来一波结构性暴涨。
历史总是押着相似的韵脚。2016 年 AlphaGo 的惊鸿一瞥,曾催生了上一代“AI 四小龙” 的镀金时代。商汤与云从虽先后登陆资本市场,却在高昂的研发投入与惨淡的商业化回报中消耗了耐心。当 OpenAI 开启大模型时代,上一代的技术明星仍在潜心修炼“ 造血” 能力。
作为本轮周期中率先转型的零一万物创始人,李开复曾在 3 月做过一个残酷的预判:中国市场最终能站稳脚跟的基础模型厂商只有三家——DeepSeek、阿里和字节。
站在 2026 年初的节点回望,预言部分应验,但结局比想象中温和。
幸存的“ 小龙们” 呈现出一幅各得其所的图景:智谱与 MiniMax 借力资本市场实现了市值跃迁;月之暗面手握重金,继续在技术深水区进行下一场豪赌;而零一万物们则在企业服务的“ 绿地” 里找到了务实的叙事。一种劫后余生的松弛感,开始在行业弥漫。
但这种松弛感,或许恰恰源于那个最紧绷的存在所主动选择的一次“ 退让”。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App