

Related articles


文 | 投行圈子
早上七点,你刷到一篇 《每天喝三杯这个,癌症风险降 50%》。
中午休息,一条 《惊人发现!这五种食物越吃越伤肝》 跳进眼帘。
深夜睡前,又瞥见 《最新研究:熬夜的人更容易获得成功》。
这些看似 「科学」 的内容,可能都是 AI 批量生产的 「AI 泔水」(「Slop」),而你我,正在不知不觉中把它们吃下去。
就在前几天,「Slop」 被 《韦氏词典》 列入 2025 年度热词,被定义为 「通常由人工智能 (AI) 批量生成的低质量数字内容」。据专家溯源,「Slop」 在 18 世纪时意为 「软泥」,19 世纪时指代 「食物残渣」,后引申为 「垃圾」「几乎没有价值的产品」,中文则译为 「泔水」「脏水」。
一些业内人士认为,「Slop」 成年度热词以及权威词典专门定义 「AI 泔水」,精准投射出公众面对海量低质 AI 内容的不适和不满,就像看见污水一样,让人下意识地想后退。

01 无处不在的 「AI 泔水」
早在 2025 年初,一家第三方机构发布了令人震惊的数据:
在中文互联网上,超过 38% 的所谓 「科普内容」 完全由 AI 生成,未经任何事实核查。在健康、财经、教育等垂直领域,这一比例甚至高达 45%。
但是一年前,这个数据并未引起各方的关注和警觉。
但是在今天,打开你常用的 App 看看:
那些标题惊悚、内容却空洞无物的 「养生秘籍」;那些数据堆砌却逻辑不通的 「理财建议」;那些看似专业实则漏洞百出的 「教育指南」……它们正以工业化的速度被制造、分发,占据着我们的注意力。
上周我朋友差点上当——一篇题为 《2025 最新税务漏洞,这样做能省 80%》 的文章在多个平台传播,说得有鼻子有眼。
结果税务部门很快辟谣:文章里的政策条款,三年前就废止了。
不止是粗制滥造
AI 泔水不是简单的 「质量差的内容」。它有更典型的特征:
第一,信息空心化。 看似篇幅很长,实则像膨化食品——体积大、营养少。说了一千字,核心观点就两句话,反复用不同方式包装。
第二,情感操纵化。 标题必带 「震惊!」「速看!」「马上删!」,内容充满 「你一定要知道」「不看后悔」 等催促性语言,制造焦虑是其拿手好戏。还有就是粗制滥造的内容,利用很多网民爱国的情感、同情心,来博流量,常见的背景音乐 《我爱你 ZG》、《早安隆回》 等等。
第三,事实模糊化。 大量使用 「有研究显示」「专家指出」「据报道」,却极少给出具体研究名称、专家姓名或可靠信源。2025 年 3 月的一项调查发现,68% 的 AI 生成 「科普文」 中的 「研究」 根本不存在或已被曲解。
第四,批量生产化。 一个模板,换几个关键词,一小时能生成上百篇 「原创」。你在不同平台看到的 「换汤不换药」 的内容,很可能出自同一套 AI 系统。
最可怕的是,这些泔水正在形成 「信息茧房」:你喜欢看养生,它就不断给你推送更多 「养生秘方」,哪怕这些方子相互矛盾。昨天说 「生姜治百病」,今天又说 「生姜是发物要少吃」,AI 不在乎逻辑自洽,只在乎留住你的眼球。
02 长期 「食用」 的恶果
如果我们长期阅读这些 AI 泔水,会发生什么?
首先是判断力下降。 当虚假与真实混在一起,当天花乱坠的谎言披着科学的外衣,我们区分真伪的能力会逐渐钝化。就像长期吃重口味食物,味蕾会失灵一样。
其次是思维碎片化。 AI 泔水往往是碎片信息的堆砌,缺乏深度逻辑和系统思考。长期摄入,我们的大脑也会习惯这种 「快餐式思考」,难以进行复杂、深入的思维活动。
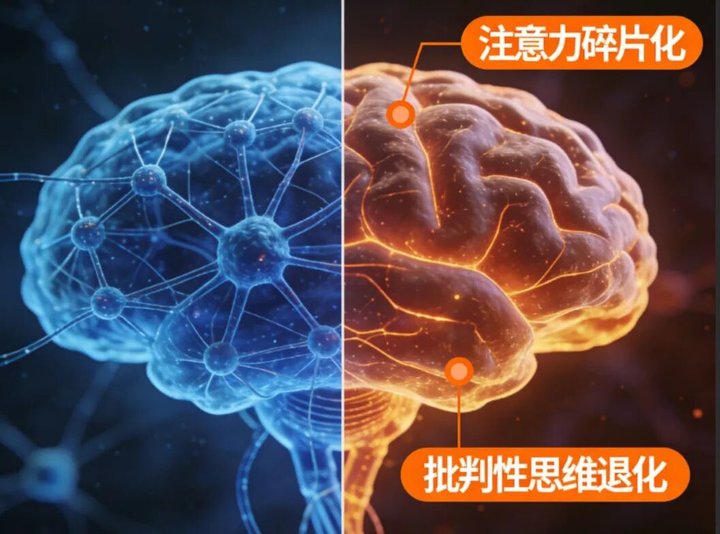
最令人担忧的是对青少年的影响。 他们正处于认知形成期,缺乏足够的信息筛选能力。当 AI 生成的历史 「科普」 歪曲事实,当拼凑的 「学习法」 误导方法,当虚假的 「成功学」 塑造价值观——这无异于精神上的慢性毒害。
今年初,某中学老师做了一个实验:让学生分析十篇网络热门 「学习经验贴」。结果发现,超过七成的学生无法识别其中明显的逻辑漏洞和事实错误,甚至有学生将这些内容作为备考依据。
「如果一代人是在 AI 编造的信息环境中长大,他们的世界观会是什么样的?」 一位教育研究者忧心忡忡地说。
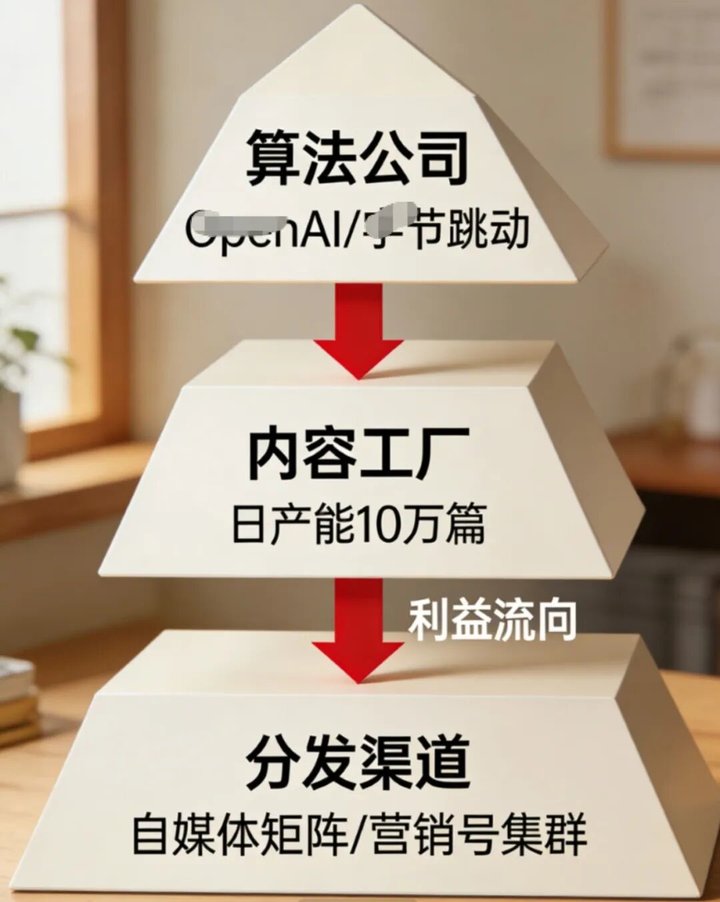
03 背后的产业链
为什么 AI 泔水泛滥成灾?
因为它背后是一条完整的利益链。
上游:模型平民化。 如今,一个稍懂技术的人,花几百元就能调用高级 AI 接口,开始 「内容创业」。
中游:批量生产。 有团队专门开发 「爆文生成器」,输入关键词,几分钟一篇 「原创」 出炉。更有甚者,开发出 「全自动运营系统」——AI 写稿、AI 配图、AI 发布、AI 回复评论,完全无人值守。
下游:流量变现。 通过平台广告分成、带货佣金、知识付费等方式,一篇爆款 AI 文章可能带来数千甚至上万元收益。2025 年第一季度,某平台封禁的违规账号中,超过 40% 是 AI 内容农场,其中一个账号月产 「原创」 文章高达 1.2 万篇。
最讽刺的是,有些平台算法反而更 「喜欢」AI 内容——因为 AI 深谙流量密码,知道怎样的话题、怎样的结构能获得更高点击和停留。这就形成了一个恶性循环:越会制造泔水,越能得到流量;越得到流量,就越生产更多泔水。
04 如何识别 AI 泔水
那我们该怎么办?第一步是学会识别。
分享几个实用技巧 (总结的未必全,欢迎各位读者在留言区补充):
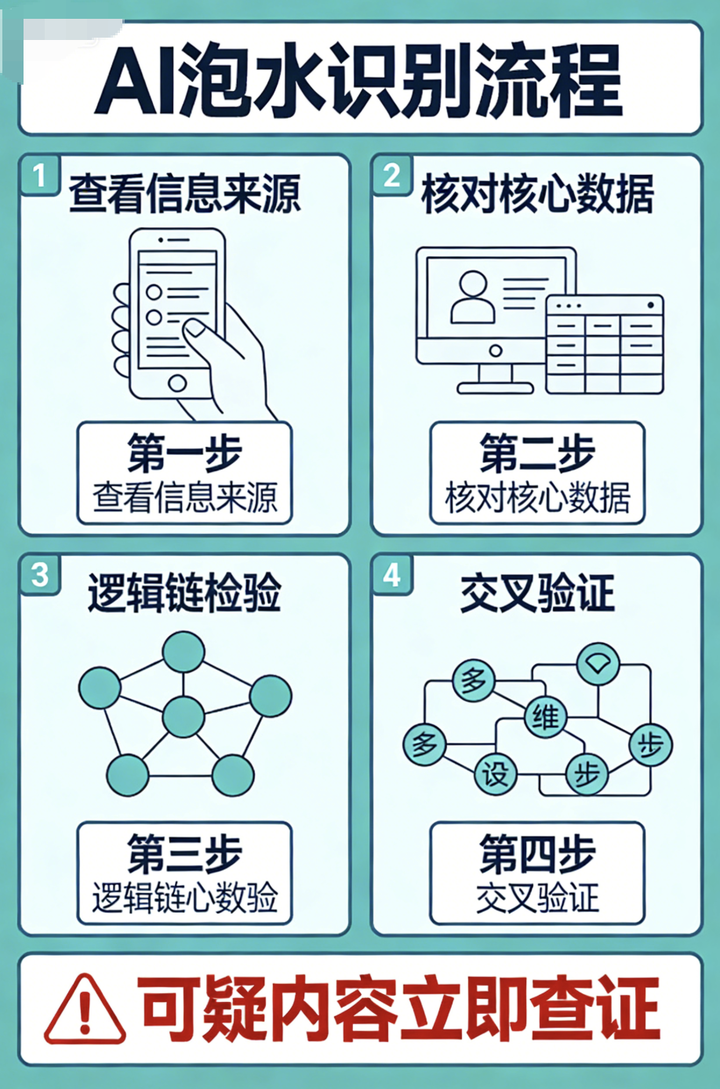
看信源。 可靠的内容通常会注明具体的研究机构、论文出处、专家全名。如果只有模糊的 「国外研究发现」「哈佛专家说」,要警惕。
查逻辑。 AI 泔水常有逻辑断层或自相矛盾。比如前一段说 「研究发现 A 导致 B」,下一段就说 「B 能够改善 A」,却不解释为什么。
品文风。 过度使用感叹号、括号补充、无意义设问 (如 「你知道为什么吗?」「接下来更精彩!」),都是 AI 泔水的常见特征。人类的写作有节奏感和呼吸感,AI 的文字往往缺乏这种 「人气」。
验数据。 2025 年的内容还在引用 2010 年的数据?声称 「最新研究」 却找不到任何相关论文?这些都很可疑。
用工具。 现在有不少 AI 内容检测工具,虽然不完全准确,但可以作为一个参考。如果一篇文章多个工具都标红,那就值得怀疑。
我个人有个习惯:看到任何惊人的 「科学发现」,先问三个问题:
谁说的?证据在哪?其他专家怎么看?
这三个问题能过滤掉大部分信息垃圾。
05 如何避免被毒害
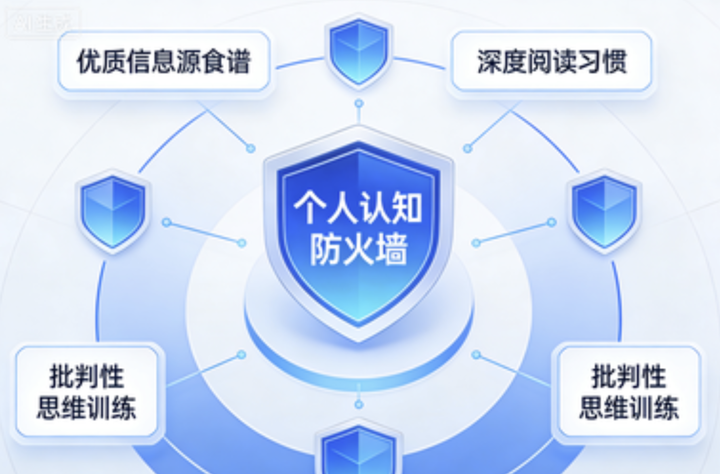
识别只是第一步,更重要的是建立健康的 「信息饮食习惯」:
主动选择优质信息源。 关注经过时间检验的媒体、有真实资质的专家、信誉良好的学术机构。少看算法推荐,平台推荐的很多都是这些内容生产商做了投流,多看主动订阅。
保持独立思考,主动搜索,不能只被动刷新。把你感兴趣的话题、想学的技能,变成一个个具体的问题,去专业的平台、书籍、课程里寻找答案。像猎人一样主动出击,而不是在推荐瀑布流里当个捡蘑菇的。
培养深度阅读习惯。 每天留出时间阅读书籍、长文章、学术论文等需要思考的内容,就像定期吃 「营养大餐」,而不是只吃 「信息零食」。
学习交叉验证。 看到一个信息,不要马上相信,而是找多个可靠信源比对。特别是健康建议、投资理财等关乎切身利益的内容,更要慎重。
保持适度怀疑。 对任何绝对化的断言 (「绝对有效」「100% 安全」) 保持警惕。真正的科学很少给出非黑即白的结论。
与 AI 共生而非被吞噬。 AI 是工具,不是主人。我们可以用 AI 辅助学习、工作,但不能让它完全代替我们的思考和判断。
我的观察,AI 最擅长的不是提供真理,而是提供你想听的答案。
06 在信息洪流中,做清醒的冲浪者
我们正处在一个信息生产的转折点:从前是人创造内容给人看,现在是 AI 创造内容给人看,未来可能是 AI 创造内容给 AI 看——而人,成了这个循环中越来越边缘的旁观者。
技术本无善恶,但使用它的人有选择。
AI 可以帮我们整理资料、翻译文献、生成初稿,但它不该代替我们判断是非、感受悲喜、定义价值。
2025 年,全球已有多个国家开始立法规范 AI 生成内容标识。欧盟要求所有 AI 内容必须标注 「AI 生成」;中国也在试点 「可信内容认证」 机制。
但法律只是底线,真正的防线,还在我们每个人心里。
下次当你刷到一篇 「震惊体」 文章、短视频,请停三秒,问自己:
这真的是我想知道的,还是算法想让我看的?
别让 AI 泔水,偷走我们思考的权利。
毕竟,人之所以为人,不就在于那一点不肯被算法驯服的清醒吗?
抵制 AI 泔水,不仅是为了获取真实信息,更是为了保卫我们作为人类的思考能力。
每一次我们选择深度阅读而非碎片浏览,每一次我们查证而非轻信,每一次我们思考而非盲从,都是在为这个信息泛滥的时代投票。
2026 年,我们需要的不是更多信息,而是更多智慧;不是更快的内容消费,而是更深的思考沉淀。
别让 AI 决定你想什么,别让算法塑造你是谁。
在这个 AI 泔水泛滥的时代,保持清醒,独立思考,或许是最可贵的抵抗。
文中部分素材、数据来源,一并致谢:
①2025 年 1 月 《中国信息内容审核白皮书》
②光明日报 《「AI 泔水」 成年度热词,值得思考》
③半月谈新媒体 《警惕 「数字泔水」 在未成年人中扩散》
④每日商报 《「数字泔水」 困局》
















