

【TechWeb】12 月 1 日消息,近日, DeepSeek 在 Hugging Face 平台正式开源了 DeepSeek-Math-V2 模型,这是全球首个达到国际数学奥林匹克竞赛金牌水平的开源数学模型。该模型基于 DeepSeek-V3.2-Exp-Base 开发。
DeepSeek-Math-V2 模型在国际数学奥林匹克 IMO 2025 模拟赛中解出 5 道题 (共 6 题),在中国数学奥林匹克 CMO 2024 中获得金牌级评价,更在被誉为 「地狱难度」 的普特南 (Putnam) 数学竞赛 2024 中取得了 118/120 的接近满分成绩,远超人类最高分 90 分。
「鲸鱼回来了!」 这是 AI 开源社区在 DeepSeek 发布新模型后的热烈反应。
两大创新,成绩碾压 GPT-5-Thinking-High 和 Gemini 2.5-Pro
根据 DeepSeek 团队发布的论文,DeepSeekMath-V2 的核心突破在于成功实现了 「自我验证」 的数学推理机制。

传统的 AI 数学推理训练存在根本性局限——模型奖励基于最终答案的正确性,但这并不能保证推理过程的正确性或逻辑的严谨性。
DeepSeek 研究人员在论文中明确指出:「正确答案并不保证推理过程正确」。
这种结果导向的训练方式,导致模型可能通过错误的逻辑得出正确答案,成为 「自信的骗子」。
DeepSeekMath-V2 彻底改变了这一模式,转向过程导向的训练方法。它不依赖大量的数学题答案数据,而是教会 AI 如何像数学家一样严谨地审查证明过程。
这种方法模拟了人类数学家的思考方式:写几步之后,停下来反思,发现漏洞就推翻重写,直到自己挑不出毛病为止。
另一个大核心创新则是 DeepSeekMath-V2 构建了一个多层次自我验证系统。
该系统由三个关键角色组成,形成了一个相互协作又相互制约的架构。
「做题家」(证明生成器) 负责解题和撰写证明过程。与以往不同,它被训练成不仅要写答案,还要进行 「自我评价」,诚实指出自己可能出错的地方。
「铁面判官」(证明验证器) 是专门训练的评分模型,它不看答案对错,而是专门盯着证明过程挑刺。它将证明分为三个等级:1 分 (完全正确)、0.5 分 (有小瑕疵)、0 分 (有致命错误)。
「判官的审计员」(元验证器) 是最绝的一步,它专门检查验证器是否在胡乱挑刺。如果验证器指出了一个不存在的错误,它会被元验证器纠正。
通过这种精巧的架构,DeepSeekMath-V2 实现了真正的自我反思能力。
模型不再盲目相信自己的第一直觉,而是学会了怀疑、审视和批判性思维。
根据论文公开的数据,DeepSeekMath-V2 在多项数学基准测试中展现出统治级的实力。
在 IMO-ProofBench 基准测试中,DeepSeekMath-V2 在 Basic 子集上获得了接近 99% 的惊人高分,显著高于 Gemini Deep Think 的 89%。
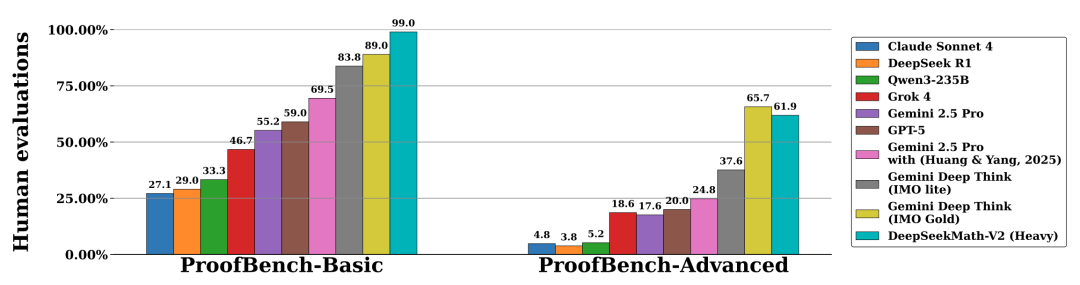
在更高级的 Advanced 子集上,DeepSeekMath-V2 得分为 61.9%,略低于 Gemini Deep Think 的 65.7%,但仍展现出强大的竞争力。
在与顶级模型的直接对比中,DeepSeekMath-V2 在所有 CNML 级别问题类别上,包括代数、几何、数论、组合学和不等式均持续优于 GPT-5-Thinking-High 和 Gemini 2.5-Pro。
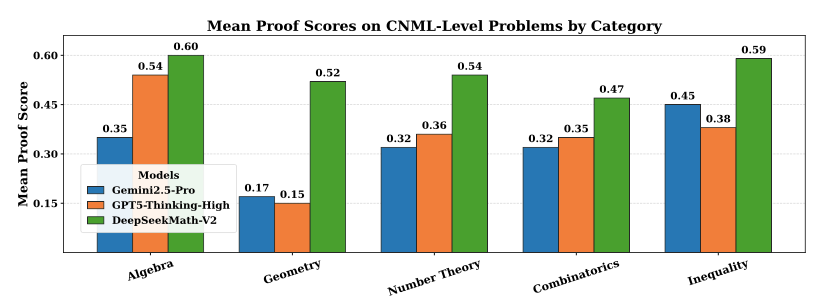
在代数领域,DeepSeekMath-V2 远超 GPT-5-Thinking-High 和 Gemini 2.5-Pro;在几何领域,其得分几乎是 Gemini 2.5-Pro 的三倍。
更令人印象深刻的是,当允许模型进行 「自我验证」,即生成答案后,自己挑毛病,然后带着问题重新生成,证明的质量分数从初始的 0.15(迭代 1 次) 飙升到了 0.27(迭代 8 次)。
开源社区沸腾
DeepSeekMath-V2 的开源发布,在 AI 社区引发了强烈反响。
海外社区有评论称 「鲸鱼终于回来了」,并指出 DeepSeek 以约 10 个百分点优势超越谷歌同类模型,超出预期。
在技术社区,用户用更通俗的语言解读这一突破:「DeepSeek 换了个教法,死磕过程。结果对了,也必须看解题步骤,过程中只要有一步没整明白,也不给糖吃。这就逼着 AI 必须要真懂,不能当混子。」
还有用户指出这一发布的时间点堪称完美:「就在昨天,AI 教父 Ilya 在访谈中提到,现在的 AI 就是个只会死记硬背的做题机器。仅仅不到 24 小时,DeepSeek 就把新模型开源了。」
这一巧合被形容为 「一次穿越时空的击掌」,是 DeepSeek 对 AI 发展路径的实质性回应。
不过,也有用户提出了理性的担忧:「自我纠错这套路,说得轻松其实难度不小啊,验证器要是本身就有问题呢?左手批右手的感觉。」
无论如何,大家都认为 DeepSeekMath-V2 的开源具有重要的行业意义。
DeepSeekMath-V2 采用 Apache 2.0 许可证,允许修改、重新用途和本地部署,为学术研究和商业应用提供了极大便利。
这一开源降低了全球研究者的门槛,特别是在当前谷歌和 OpenAI 都将他们的高分数学模型严格限制在付费或实验性访问。
DeepSeekMath-V2 的开源发布标志着 AI 数学推理能力不再是大公司的专属领域,而是成为全球研究者可以共同探索和推进的开放领域。
Hugging Face 联合创始人兼 Clement Delangue 表示:这一发布是迈向 AI 真正民主化的一步。
用户现在可以免费使用 「世界上最好的数学家之一的大脑」,而不必担心公司或政府将其收回。

【TechWeb】12 月 1 日消息,近日, DeepSeek 在 Hugging Face 平台正式开源了 DeepSeek-Math-V2 模型,这是全球首个达到国际数学奥林匹克竞赛金牌水平的开源数学模型。该模型基于 DeepSeek-V3.2-Exp-Base 开发。
DeepSeek-Math-V2 模型在国际数学奥林匹克 IMO 2025 模拟赛中解出 5 道题 (共 6 题),在中国数学奥林匹克 CMO 2024 中获得金牌级评价,更在被誉为 「地狱难度」 的普特南 (Putnam) 数学竞赛 2024 中取得了 118/120 的接近满分成绩,远超人类最高分 90 分。
「鲸鱼回来了!」 这是 AI 开源社区在 DeepSeek 发布新模型后的热烈反应。
两大创新,成绩碾压 GPT-5-Thinking-High 和 Gemini 2.5-Pro
根据 DeepSeek 团队发布的论文,DeepSeekMath-V2 的核心突破在于成功实现了 「自我验证」 的数学推理机制。
传统的 AI 数学推理训练存在根本性局限——模型奖励基于最终答案的正确性,但这并不能保证推理过程的正确性或逻辑的严谨性。
DeepSeek 研究人员在论文中明确指出:「正确答案并不保证推理过程正确」。
这种结果导向的训练方式,导致模型可能通过错误的逻辑得出正确答案,成为 「自信的骗子」。
DeepSeekMath-V2 彻底改变了这一模式,转向过程导向的训练方法。它不依赖大量的数学题答案数据,而是教会 AI 如何像数学家一样严谨地审查证明过程。
这种方法模拟了人类数学家的思考方式:写几步之后,停下来反思,发现漏洞就推翻重写,直到自己挑不出毛病为止。
另一个大核心创新则是 DeepSeekMath-V2 构建了一个多层次自我验证系统。
该系统由三个关键角色组成,形成了一个相互协作又相互制约的架构。
「做题家」(证明生成器) 负责解题和撰写证明过程。与以往不同,它被训练成不仅要写答案,还要进行 「自我评价」,诚实指出自己可能出错的地方。
「铁面判官」(证明验证器) 是专门训练的评分模型,它不看答案对错,而是专门盯着证明过程挑刺。它将证明分为三个等级:1 分 (完全正确)、0.5 分 (有小瑕疵)、0 分 (有致命错误)。
「判官的审计员」(元验证器) 是最绝的一步,它专门检查验证器是否在胡乱挑刺。如果验证器指出了一个不存在的错误,它会被元验证器纠正。
通过这种精巧的架构,DeepSeekMath-V2 实现了真正的自我反思能力。
模型不再盲目相信自己的第一直觉,而是学会了怀疑、审视和批判性思维。
根据论文公开的数据,DeepSeekMath-V2 在多项数学基准测试中展现出统治级的实力。
在 IMO-ProofBench 基准测试中,DeepSeekMath-V2 在 Basic 子集上获得了接近 99% 的惊人高分,显著高于 Gemini Deep Think 的 89%。
在更高级的 Advanced 子集上,DeepSeekMath-V2 得分为 61.9%,略低于 Gemini Deep Think 的 65.7%,但仍展现出强大的竞争力。
在与顶级模型的直接对比中,DeepSeekMath-V2 在所有 CNML 级别问题类别上,包括代数、几何、数论、组合学和不等式均持续优于 GPT-5-Thinking-High 和 Gemini 2.5-Pro。
在代数领域,DeepSeekMath-V2 远超 GPT-5-Thinking-High 和 Gemini 2.5-Pro;在几何领域,其得分几乎是 Gemini 2.5-Pro 的三倍。
更令人印象深刻的是,当允许模型进行 「自我验证」,即生成答案后,自己挑毛病,然后带着问题重新生成,证明的质量分数从初始的 0.15(迭代 1 次) 飙升到了 0.27(迭代 8 次)。
开源社区沸腾
DeepSeekMath-V2 的开源发布,在 AI 社区引发了强烈反响。
海外社区有评论称 「鲸鱼终于回来了」,并指出 DeepSeek 以约 10 个百分点优势超越谷歌同类模型,超出预期。
在技术社区,用户用更通俗的语言解读这一突破:「DeepSeek 换了个教法,死磕过程。结果对了,也必须看解题步骤,过程中只要有一步没整明白,也不给糖吃。这就逼着 AI 必须要真懂,不能当混子。」
还有用户指出这一发布的时间点堪称完美:「就在昨天,AI 教父 Ilya 在访谈中提到,现在的 AI 就是个只会死记硬背的做题机器。仅仅不到 24 小时,DeepSeek 就把新模型开源了。」
这一巧合被形容为 「一次穿越时空的击掌」,是 DeepSeek 对 AI 发展路径的实质性回应。
不过,也有用户提出了理性的担忧:「自我纠错这套路,说得轻松其实难度不小啊,验证器要是本身就有问题呢?左手批右手的感觉。」
无论如何,大家都认为 DeepSeekMath-V2 的开源具有重要的行业意义。
DeepSeekMath-V2 采用 Apache 2.0 许可证,允许修改、重新用途和本地部署,为学术研究和商业应用提供了极大便利。
这一开源降低了全球研究者的门槛,特别是在当前谷歌和 OpenAI 都将他们的高分数学模型严格限制在付费或实验性访问。
DeepSeekMath-V2 的开源发布标志着 AI 数学推理能力不再是大公司的专属领域,而是成为全球研究者可以共同探索和推进的开放领域。
Hugging Face 联合创始人兼 Clement Delangue 表示:这一发布是迈向 AI 真正民主化的一步。
用户现在可以免费使用 「世界上最好的数学家之一的大脑」,而不必担心公司或政府将其收回。
Related articles

【TechWeb】12 月 1 日消息,近日, DeepSeek 在 Hugging Face 平台正式开源了 DeepSeek-Math-V2 模型,这是全球首个达到国际数学奥林匹克竞赛金牌水平的开源数学模型。该模型基于 DeepSeek-V3.2-Exp-Base 开发。
DeepSeek-Math-V2 模型在国际数学奥林匹克 IMO 2025 模拟赛中解出 5 道题 (共 6 题),在中国数学奥林匹克 CMO 2024 中获得金牌级评价,更在被誉为 「地狱难度」 的普特南 (Putnam) 数学竞赛 2024 中取得了 118/120 的接近满分成绩,远超人类最高分 90 分。
「鲸鱼回来了!」 这是 AI 开源社区在 DeepSeek 发布新模型后的热烈反应。
两大创新,成绩碾压 GPT-5-Thinking-High 和 Gemini 2.5-Pro
根据 DeepSeek 团队发布的论文,DeepSeekMath-V2 的核心突破在于成功实现了 「自我验证」 的数学推理机制。
传统的 AI 数学推理训练存在根本性局限——模型奖励基于最终答案的正确性,但这并不能保证推理过程的正确性或逻辑的严谨性。
DeepSeek 研究人员在论文中明确指出:「正确答案并不保证推理过程正确」。
这种结果导向的训练方式,导致模型可能通过错误的逻辑得出正确答案,成为 「自信的骗子」。
DeepSeekMath-V2 彻底改变了这一模式,转向过程导向的训练方法。它不依赖大量的数学题答案数据,而是教会 AI 如何像数学家一样严谨地审查证明过程。
这种方法模拟了人类数学家的思考方式:写几步之后,停下来反思,发现漏洞就推翻重写,直到自己挑不出毛病为止。
另一个大核心创新则是 DeepSeekMath-V2 构建了一个多层次自我验证系统。
该系统由三个关键角色组成,形成了一个相互协作又相互制约的架构。
「做题家」(证明生成器) 负责解题和撰写证明过程。与以往不同,它被训练成不仅要写答案,还要进行 「自我评价」,诚实指出自己可能出错的地方。
「铁面判官」(证明验证器) 是专门训练的评分模型,它不看答案对错,而是专门盯着证明过程挑刺。它将证明分为三个等级:1 分 (完全正确)、0.5 分 (有小瑕疵)、0 分 (有致命错误)。
「判官的审计员」(元验证器) 是最绝的一步,它专门检查验证器是否在胡乱挑刺。如果验证器指出了一个不存在的错误,它会被元验证器纠正。
通过这种精巧的架构,DeepSeekMath-V2 实现了真正的自我反思能力。
模型不再盲目相信自己的第一直觉,而是学会了怀疑、审视和批判性思维。
根据论文公开的数据,DeepSeekMath-V2 在多项数学基准测试中展现出统治级的实力。
在 IMO-ProofBench 基准测试中,DeepSeekMath-V2 在 Basic 子集上获得了接近 99% 的惊人高分,显著高于 Gemini Deep Think 的 89%。
在更高级的 Advanced 子集上,DeepSeekMath-V2 得分为 61.9%,略低于 Gemini Deep Think 的 65.7%,但仍展现出强大的竞争力。
在与顶级模型的直接对比中,DeepSeekMath-V2 在所有 CNML 级别问题类别上,包括代数、几何、数论、组合学和不等式均持续优于 GPT-5-Thinking-High 和 Gemini 2.5-Pro。
在代数领域,DeepSeekMath-V2 远超 GPT-5-Thinking-High 和 Gemini 2.5-Pro;在几何领域,其得分几乎是 Gemini 2.5-Pro 的三倍。
更令人印象深刻的是,当允许模型进行 「自我验证」,即生成答案后,自己挑毛病,然后带着问题重新生成,证明的质量分数从初始的 0.15(迭代 1 次) 飙升到了 0.27(迭代 8 次)。
开源社区沸腾
DeepSeekMath-V2 的开源发布,在 AI 社区引发了强烈反响。
海外社区有评论称 「鲸鱼终于回来了」,并指出 DeepSeek 以约 10 个百分点优势超越谷歌同类模型,超出预期。
在技术社区,用户用更通俗的语言解读这一突破:「DeepSeek 换了个教法,死磕过程。结果对了,也必须看解题步骤,过程中只要有一步没整明白,也不给糖吃。这就逼着 AI 必须要真懂,不能当混子。」
还有用户指出这一发布的时间点堪称完美:「就在昨天,AI 教父 Ilya 在访谈中提到,现在的 AI 就是个只会死记硬背的做题机器。仅仅不到 24 小时,DeepSeek 就把新模型开源了。」
这一巧合被形容为 「一次穿越时空的击掌」,是 DeepSeek 对 AI 发展路径的实质性回应。
不过,也有用户提出了理性的担忧:「自我纠错这套路,说得轻松其实难度不小啊,验证器要是本身就有问题呢?左手批右手的感觉。」
无论如何,大家都认为 DeepSeekMath-V2 的开源具有重要的行业意义。
DeepSeekMath-V2 采用 Apache 2.0 许可证,允许修改、重新用途和本地部署,为学术研究和商业应用提供了极大便利。
这一开源降低了全球研究者的门槛,特别是在当前谷歌和 OpenAI 都将他们的高分数学模型严格限制在付费或实验性访问。
DeepSeekMath-V2 的开源发布标志着 AI 数学推理能力不再是大公司的专属领域,而是成为全球研究者可以共同探索和推进的开放领域。
Hugging Face 联合创始人兼 Clement Delangue 表示:这一发布是迈向 AI 真正民主化的一步。
用户现在可以免费使用 「世界上最好的数学家之一的大脑」,而不必担心公司或政府将其收回。
【TechWeb】12 月 1 日消息,近日, DeepSeek 在 Hugging Face 平台正式开源了 DeepSeek-Math-V2 模型,这是全球首个达到国际数学奥林匹克竞赛金牌水平的开源数学模型。该模型基于 DeepSeek-V3.2-Exp-Base 开发。
DeepSeek-Math-V2 模型在国际数学奥林匹克 IMO 2025 模拟赛中解出 5 道题 (共 6 题),在中国数学奥林匹克 CMO 2024 中获得金牌级评价,更在被誉为 「地狱难度」 的普特南 (Putnam) 数学竞赛 2024 中取得了 118/120 的接近满分成绩,远超人类最高分 90 分。
「鲸鱼回来了!」 这是 AI 开源社区在 DeepSeek 发布新模型后的热烈反应。
两大创新,成绩碾压 GPT-5-Thinking-High 和 Gemini 2.5-Pro
根据 DeepSeek 团队发布的论文,DeepSeekMath-V2 的核心突破在于成功实现了 「自我验证」 的数学推理机制。
传统的 AI 数学推理训练存在根本性局限——模型奖励基于最终答案的正确性,但这并不能保证推理过程的正确性或逻辑的严谨性。
DeepSeek 研究人员在论文中明确指出:「正确答案并不保证推理过程正确」。
这种结果导向的训练方式,导致模型可能通过错误的逻辑得出正确答案,成为 「自信的骗子」。
DeepSeekMath-V2 彻底改变了这一模式,转向过程导向的训练方法。它不依赖大量的数学题答案数据,而是教会 AI 如何像数学家一样严谨地审查证明过程。
这种方法模拟了人类数学家的思考方式:写几步之后,停下来反思,发现漏洞就推翻重写,直到自己挑不出毛病为止。
另一个大核心创新则是 DeepSeekMath-V2 构建了一个多层次自我验证系统。
该系统由三个关键角色组成,形成了一个相互协作又相互制约的架构。
「做题家」(证明生成器) 负责解题和撰写证明过程。与以往不同,它被训练成不仅要写答案,还要进行 「自我评价」,诚实指出自己可能出错的地方。
「铁面判官」(证明验证器) 是专门训练的评分模型,它不看答案对错,而是专门盯着证明过程挑刺。它将证明分为三个等级:1 分 (完全正确)、0.5 分 (有小瑕疵)、0 分 (有致命错误)。
「判官的审计员」(元验证器) 是最绝的一步,它专门检查验证器是否在胡乱挑刺。如果验证器指出了一个不存在的错误,它会被元验证器纠正。
通过这种精巧的架构,DeepSeekMath-V2 实现了真正的自我反思能力。
模型不再盲目相信自己的第一直觉,而是学会了怀疑、审视和批判性思维。
根据论文公开的数据,DeepSeekMath-V2 在多项数学基准测试中展现出统治级的实力。
在 IMO-ProofBench 基准测试中,DeepSeekMath-V2 在 Basic 子集上获得了接近 99% 的惊人高分,显著高于 Gemini Deep Think 的 89%。
在更高级的 Advanced 子集上,DeepSeekMath-V2 得分为 61.9%,略低于 Gemini Deep Think 的 65.7%,但仍展现出强大的竞争力。
在与顶级模型的直接对比中,DeepSeekMath-V2 在所有 CNML 级别问题类别上,包括代数、几何、数论、组合学和不等式均持续优于 GPT-5-Thinking-High 和 Gemini 2.5-Pro。
在代数领域,DeepSeekMath-V2 远超 GPT-5-Thinking-High 和 Gemini 2.5-Pro;在几何领域,其得分几乎是 Gemini 2.5-Pro 的三倍。
更令人印象深刻的是,当允许模型进行 「自我验证」,即生成答案后,自己挑毛病,然后带着问题重新生成,证明的质量分数从初始的 0.15(迭代 1 次) 飙升到了 0.27(迭代 8 次)。
开源社区沸腾
DeepSeekMath-V2 的开源发布,在 AI 社区引发了强烈反响。
海外社区有评论称 「鲸鱼终于回来了」,并指出 DeepSeek 以约 10 个百分点优势超越谷歌同类模型,超出预期。
在技术社区,用户用更通俗的语言解读这一突破:「DeepSeek 换了个教法,死磕过程。结果对了,也必须看解题步骤,过程中只要有一步没整明白,也不给糖吃。这就逼着 AI 必须要真懂,不能当混子。」
还有用户指出这一发布的时间点堪称完美:「就在昨天,AI 教父 Ilya 在访谈中提到,现在的 AI 就是个只会死记硬背的做题机器。仅仅不到 24 小时,DeepSeek 就把新模型开源了。」
这一巧合被形容为 「一次穿越时空的击掌」,是 DeepSeek 对 AI 发展路径的实质性回应。
不过,也有用户提出了理性的担忧:「自我纠错这套路,说得轻松其实难度不小啊,验证器要是本身就有问题呢?左手批右手的感觉。」
无论如何,大家都认为 DeepSeekMath-V2 的开源具有重要的行业意义。
DeepSeekMath-V2 采用 Apache 2.0 许可证,允许修改、重新用途和本地部署,为学术研究和商业应用提供了极大便利。
这一开源降低了全球研究者的门槛,特别是在当前谷歌和 OpenAI 都将他们的高分数学模型严格限制在付费或实验性访问。
DeepSeekMath-V2 的开源发布标志着 AI 数学推理能力不再是大公司的专属领域,而是成为全球研究者可以共同探索和推进的开放领域。
Hugging Face 联合创始人兼 Clement Delangue 表示:这一发布是迈向 AI 真正民主化的一步。
用户现在可以免费使用 「世界上最好的数学家之一的大脑」,而不必担心公司或政府将其收回。











