(图片来源:拍摄于 2025 世界人工智能大会蚂蚁展台)

刚刚,全球最新的万亿参数通用语言模型开源了。
10 月 9 日消息,蚂蚁集团今天发布并开源万亿参数的通用语言模型 Ling-1T。
据悉,Ling-1T 是蚂蚁百灵大模型 Ling 2.0 系列的第一款旗舰模型,也是蚂蚁百灵团队迄今为止推出的规模最大、能力最强的非思考大模型。
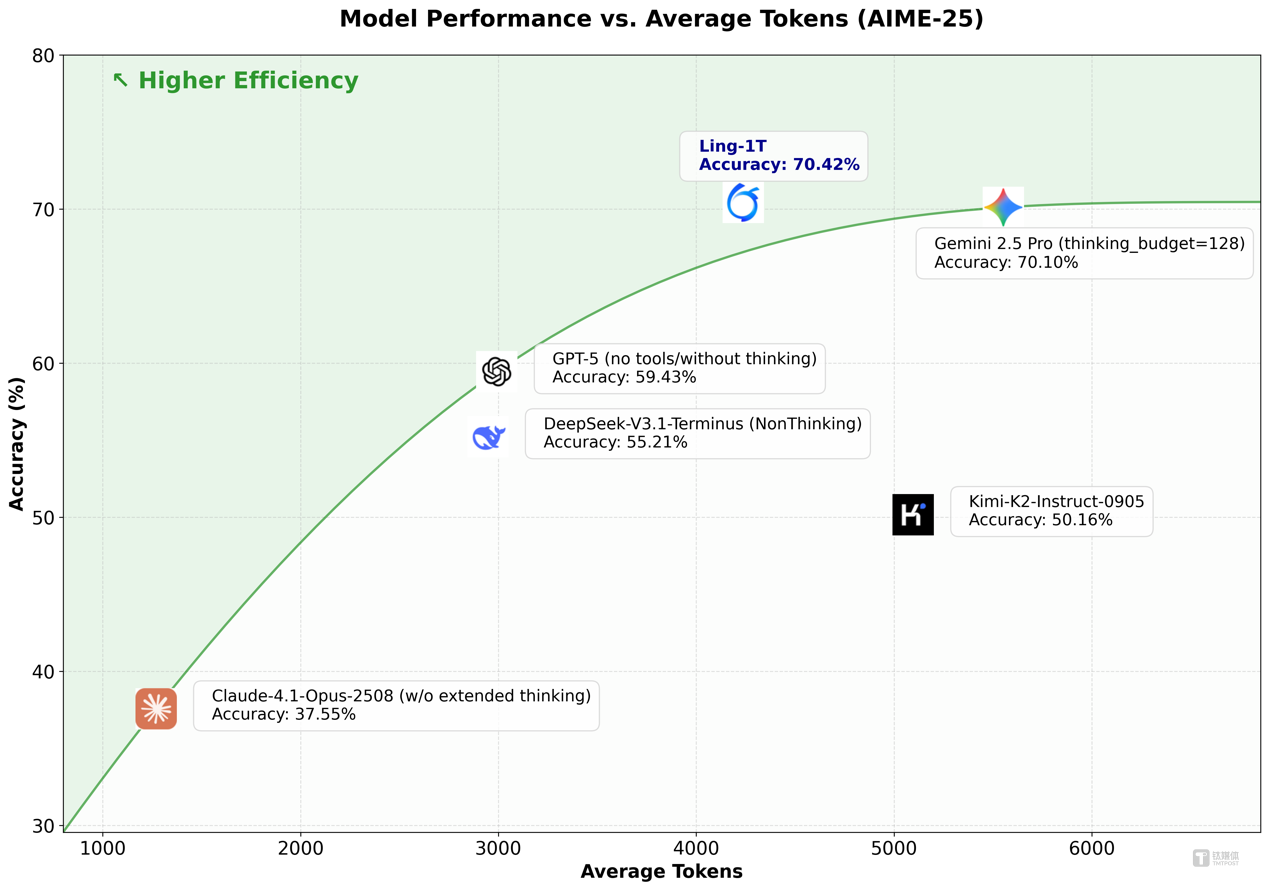
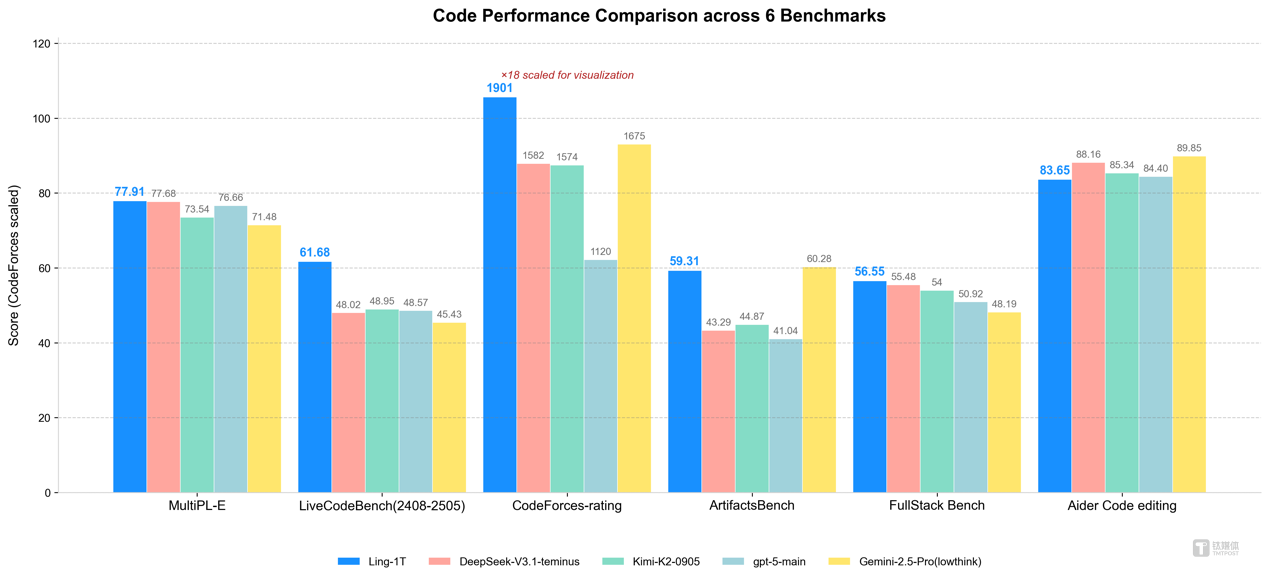
基准测试数据显示,在有限输出 Token 条件下,Ling-1T 于多项复杂推理基准中取得 SOTA 表现,同时在代码生成、软件开发、竞赛数学、专业数学、逻辑推理等多项高难度基准测试上,Ling-1T 均取得领先成绩,多项指标位居开源模型的榜首。
以竞赛数学榜单 AIME 25 为例。Ling-1T 以平均 4000+ Token 的消耗达到了 70.42% 的准确率,优于 Gemini-2.5-Pro,后者平均达 5000+Tokens,准确率为 70.10%。蚂蚁 Ling-1T 用更少的 Token 实现了更高的准确率,性价比优于谷歌 Gemini 系列,展现出在推理精度和思考效率综合能力上的优势。

不仅是蚂蚁,国庆中秋假期前后,OpenAI、阿里、智谱、DeepSeek 等中国和美国的 AI 大模型加速竞争。
- OpenAI 发布 AI 视频模型 Sora2,并在开发者大会上公布 GPT-5 Pro、ChatGPT 框架 Apps SDK 等,引发全球关注;
- DeepSeek 则发布 DeepSeek-V3.2-Exp,全面适配国产算力卡,并且训练推理提效、API 同步降价;
- 阿里通义则发布新一代原生全模态大模型 Qwen3-Omni,以及全开源通义 DeepResearch 模型、框架、方案等;
- 智谱则发布旗舰模型 GLM-4.6,并凭借 SOTA 的 Agentic Coding 能力,GLM-4.6 登顶 Hugging Face Trending 全球第一、LMArena 上排名开源第一、全球第四,与 Qwen Max Preview(闭源) 并列国内第⼀。
正如零一万物创始人、CEO 李开复所说,底座基础模型是一场千亿级别公司的“ 军备竞赛”。
英伟达 CEO 黄仁勋则指出,过去六个月 AI 计算需求大幅上升,英伟达新一代架构 Blackwell 的芯片需求“ 非常非常高”。他认为这标志着“ 新一轮工业革命” 开始。
英伟达上月宣布,计划未来十年向 OpenAI 共计投资 1000 亿美元,支持 OpenAI 部署需要 10 千兆瓦电力的英伟达系统,相当于 400 万至 500 万个 GPU。
OpenAI CEO 奥尔特曼 (Sam Altman) 周三表示,技术突破的关键在于更聪明的模型、更长的上下文处理能力和更好的记忆系统。AGI 的核心在于发现新知识,AGI 最重要的衡量标准已不是通过某个测试,而是 AI 开始具备“ 发现新知识” 并扩展人类知识边界的能力。
国产最强万亿参数旗舰模型来了
近年来,大语言模型发展迅速,尤其是 DeepSeek 热潮,引发学界和业界对通用人工智能 (AGI) 的广泛讨论,而混合专家 (MoE) 模型在特定任务中表现优异,但训练依赖高性能计算资源,成本高昂,限制了其在资源受限环境中的应用。
蚂蚁 Ling 团队认为,虽然 MoE 模型训练对高性能 AI 芯片 (如 H100 和 H800) 需求大,且资源供应,但低性能加速器更易获取且单位成本效益高,因此,模型需要能在异构计算单元和分布式集群间切换的技术框架。同时在 AI Infra 部分,在跨集群、跨设备的兼容和可靠层面进行性能优化。该公司设定的目标是“ 不使用高级 GPU” 来扩展模型。
今年 3 月,蚂蚁集团 Ling Team 团队利用 AI Infra 技术开发两个百灵系列开源 MoE 模型 Ling-Lite 和 Ling-Plus,前者参数规模 168 亿,Plus 基座模型参数规模高达 2900 亿,引发广泛关注。
随后,蚂蚁还公布了语音 AI 框架 Ming‑UniAudio、新一代推理模型 Ring-flash-2.0 等模型产品。
目前,蚂蚁 AGI 团队主要由蚂蚁集团副总裁、首席技术官何征宇负责。据悉,何征宇获佐治亚理工学院计算机博士学位;2012 年至 2018 年就职于谷歌,在谷歌创立并领导了开源项目 gVisor;2018 年何征宇加入蚂蚁集团,负责公司技术基础设施建设,主导了蚂蚁云原生化、绿色计算实践、机密计算创新、开源战略布局等重要项目,而最新的百灵大模型计划聚焦在生活服务、金融服务、医疗健康等场景。
如今,蚂蚁百灵大模型团队终于公布最新、全球性能较强的万亿参数非思考模型 Ling-1T。
Ling-1T 沿用 Ling 2.0 架构,在 20T+tokens 高质量、高推理浓度的语料上完成预训练,支持最高 128K 上下文窗口,通过“ 中训练+后训练” 的演进式思维链 (Evo-CoT) 极大提升模型高效思考和精准推理能力。
值得一提的是,Ling-1T 全程采用 FP8 混合精度训练 (部分技术已开源),是目前已知规模最大的使用 FP8 训练的基座模型。这一设计为训练带来了显著的显存节省、更灵活的并行切分策略和 15%+ 的端到端加速。
强化学习阶段,蚂蚁百灵团队创新性地提出了 LPO 方法 (Linguistics-Unit Policy Optimization,LingPO) ,这是一种以“ 句子” 为粒度的策略优化算法,为万亿参数模型的稳定训练提供了关键支持。另外,蚂蚁百灵团队提出了新的混合奖励机制,在确保代码正确、功能完善的同时持续提升这个万亿基座对视觉美学的认知。
在 ArtifactsBench 前端能力基准上,Ling-1T 得分达 59.31,并且在可视化和前端开发任务领域以显著优势位居开源模型榜首。
据蚂蚁百灵团队透露,除了 Ling-1T 这款非思考模型,蚂蚁百灵团队还在训练万亿参数级的深度思考大模型 Ring-1T,已在 9 月 30 日开源了 preview 版。目前,开发者都可以体验 Ling-1T 模型。
吸金 1927 亿美元,全球 AI 投资创纪录
据 PitchBook 统计,今年以来,全球 AI 领域初创公司已吸引创纪录的 1927 亿美元风险投资,2025 年有望成为首个逾一半风投资金流入 AI 行业的年份。
大部分风投资金流向相对成熟的初创公司。其中,OpenAI、Anthropic、xAI 等头部 AI 创业公司本季均募集了上百亿美元,而一些知名度较低的新创公司则举步维艰,尤其是那些并非专注于 AI 的企业。PitchBook 发现,IPO 和并购环境紧缩也让部分风险投资人不愿押注未经验证的公司。
最近一个季度,美国风险投资将 62.7% 的资金投向 AI 领域的公司,全球风险投资该比例为 53.2%。今年以来,全球风投总额为 3668 亿美元,其中美国风投达到 2502 亿美元。
PitchBook 研究主管 Kyle Sanford 表示,“ 市场正在分化,要么在做人工智能,要么不是,要么是大公司,要么不是。”
PitchBook AI 和网络安全高级研究分析师 Dimitri Zabelin 表示,目前主要的退出趋势是频繁但价值较低的收购,以及价值明显较高的 IPO 数量较少。“ 这也与当前宏观环境中的流动性状况有关。”
值得一提的是,早在 2022 年 ChatGPT 横空出世后,OpenAI 在 AI 技术上突飞猛进,目前 ChatGPT 周活跃用户达 8 亿,8 个月内增加了一倍。
近期,OpenAI 完成了一笔 66 亿美元融资,目前估值为 5000 亿美元,超越马斯克的 SpaceX,成为全球最有价值的初创公司。
另据 The Information 报道,今年前七个月,OpenAI 收入大约翻了一番,预计年收入将达到 120 亿美元。同时,OpenAI 已签下总额近 1 万亿美元的算力采购协议,有望成为全球赚钱能力最强的 AI 公司。(作者 | 林志佳)
更多对全球市场、跨国公司和中国经济的深度分析与独家洞察,欢迎访问 Barron's 巴伦中文网官方网站
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App