转眼之间,2025 年即将过半。上半年 OpenAI o3、Gemini 2.5 pro、Grok 3 mini 和 Claude 4 的推出,以及智能体 MCP、A2A 等协议的推出和融合,让前沿大模型、智能体、应用的进展再次提速。
智能体接管人类工作的时长,成为观察 AGI 进程的又一个重要视角。硅谷研究机构 METR 刻画出了智能体完成任务复杂程度每 7 个月翻倍的曲线,Claude-opus 4 可以连续工作 7 小时。从初级白领工作开始,智能体接管的任务会越来越多。
智能体似乎正在真正解除鲍莫尔病——一个在传统经济学中的悖论,即技术进步无法提升医疗、教育等劳动密集服务业的劳动生产率。Anthropic 创始人阿莫迪 (Dario Amodei)发出了耸人的警告,智能体将很快取代一半的初级白领工人,一人独角兽公司将在 2026 年出现。
这一切在硅谷的科技巨头,尤其是在科技七雄中,正在开始发生。它们一方面增加 AI 基础设施的投入,加强顶尖 AI 人才的争夺,一方面在大量裁撤可替代的工作岗位。AI 的超级独角兽这里,OpenAI 的年化收入达到百亿美元,Anthropic 的年化收入半年内从 10 亿美元增加到 30 亿美元。在一些 AI 应用的垂直领域,如编程、产品开发与设计、招聘、营销、客服、医疗、教育等领域,开始出现一些早期的规模产出。
与此同时,关于 AI 产生自我意识、开始对人类隐瞒、欺骗人类、甚至拒绝执行人类指令的迹象,开始在这些新发布的模型中出现。深度学习之父、诺奖得主辛顿再次发出 AI 统治并威胁人类文明存在的警告。《AI 2027》 预测,中美两国的超级智能决定合作,欺骗了各自国家的治理机制,酿成文明灭绝级的灾难。
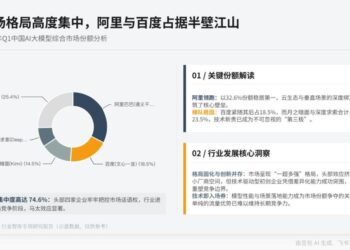
从全球来看,与美国日趋激烈但也趋同的模型发布竞赛相比,上半年更重要的里程碑事件,发生在中国。
5 月底,R1 0528 性能超越 Gemini 2.5 pro,进一步逼近 OpenAI o3。R1 0528 仍然建立在 V3/R1 的基座之上,这是一次后训练带来的性能跃升。这件事情的意义在于,R1 仅在一代之内,同时实现了对 OpenAI 两代前沿推理模型的追赶,o1 和 o3。创新之处在于,DeepSeek 是开源的,是在缺乏算力的基础上训练出来的,而且更具成本优势。所以在相同的分数上,专业机构更乐意给予 DeepSeek 更高的评价。
上半年中国确立了在开源领域的优势。通义千问在 2024 年 9 月即已经开始超越 Llama 3,DeepSeek R1 从 2025 年初即开始赶上 o1。Llama 4 推出后,并没有改变开始形成的 DeepSeek 与通义千问之间在性能上互卷的格局。
互联网女皇米克尔 (Mary Meeker)发出了第一份 AI 趋势报告。她从 PC、互联网、移动、云计算来看 AI,认为所有后来的技术,都是之前技术的 「复利」,AI 也不例外。所以,押注 「乐观」 往往是最值得的投资之一。
目前全球仍有 26 亿人没有接入互联网,米克尔看好更低成本的卫星互联网,加上直接带有 AI 功能的网络体验。「想象一下,一个 『首次上网体验』 不再是输入关键词到搜索引擎,而是与一台能与你对话的机器交流。想象一下,完全跳过传统的应用程序层,直接通过一个由智能代理驱动的界面来统一管理不同的技术平台,同时理解用户的语言、语境与意图。」
美国科技七雄中和其他科技巨头,除苹果之外,几乎所有的创始人都亲自操刀或深度参与这场技术革命。中国的科技巨头,如阿里、腾讯、字节、百度等,创始人已经开始真正成为发动机。
米克尔进一步延展了这种领导力:「AI 领导力可能带来地缘政治领导力——而非相反。」
报告认为,这一次中国的响应速度,要明显快于 1995 年时的互联网革命。全球 AI 竞争真正启动的标志,是中国 DeepSeek 的发布 (2025 年 1 月)等事件。
Artificial Analysis 发布的二季度分析报告显示,中国与美国前沿大模型的差距,已经从 ChatGPT 发布时的两年,到今年上半年的不足三个月。而且中国在所有的 AI 前沿系统,从大语言模型,推理模型,到所有模态的生成 AI 模型,都已经建立起与美国全面对标竞争的态势。
由于中国更大的人口及市场规模,美国比中国更需要全球用户和市场。实际上 ChatGPT 的最重要的用户基数来自亚洲,如印度、印尼、巴基斯坦和越南这样的互联网开放的人口大中型国家。

大模型及 AI 之于社会经济与地缘政治的颠覆,如此之广、如此之深,以至于任何身在其中或暂未波及的个人、企业与政府,都或亢奋、或恐惧于正在到来的未来。而在形形色色的有关 AI 的未来中,AGI 又拥有最高的威慑力。
与其说大家在追逐 AGI 的未来,不如说,AGI 已经锁定了大家的未来。
上半年备受期待的 GPT-5 和 DeepSeek V4/R2 都还没有出来,但大致轮廓已经依稀可见。或许 OpenAI 与 DeepSeeK 也只是 AGI 浩瀚冰山的一角,单飞后的 OpenAI 黑帮们,合计估值数百亿美元,它们对 AI 如何更好地 「思考」 的探索,也将逐步浮出水面。已经非常趋同的大模型,还会有哪些超越当前经典架构的悬念,会 gradually and suddenly 吗?
OpenAI 与 DeepSeek
今年 4 月初,奥特曼一句 「我们能把 GPT-5 做得比原先想象的更好」,宣告了它的正式跳票;它将在 o3 和 o4-mini 发布后的几个月后推出。从 OpenAI 的几次发布会与访谈中,我们已经可以勾勒出 GPT-5 大致的模样。
它最有可能是一个推理与生成相统一的原生的多模态大模型。今年 2 月,奥特曼就透露过 GPT-4.5 将是最后一个非思维链模型,暗示 GPT-5 天生就整合了 o 系列的推理功能,既适于高情商地交谈,也适于理性地思考。3 月,自回归的图像生成被原生地嵌入到 GPT-4o 中。5 月,在发布编程智能体 Codex 后,OpenAI 谈到为了减少模型切换,未来计划将它与 Operator、Deep Research 和 Memory 整合到一起。
很难让人不怀疑,是不是 DeepSeek 的冲击太大,逼得 OpenAI 不得不陆陆续续地将原本属于 GPT-5 的部分功能,拆分出来发布了。不妨回忆一下,去年这个时候,AI 大神 Ilya Sutskever 从 OpenAI 离开,奥特曼就暗示过 GPT-5 推迟发布;当时对 GPT-5 的描述是,将注重 「与世界更深入地整合」。至少从那一刻起,人们就怀疑当时 GPT-5 已经进入后训练阶段了。
由于 GPT-5 迟迟不现身,曾让硅谷品尝到苦涩教训的中国厂商 DeepSeek,再次被寄予了厚望,甚至不仅仅是技术层面的,还有地缘层面的。就连法国 AI 希望之星 Mistral AI 也因此相信,既然 「中国的 Mistral」 能行,那么自己也能行。市场期待 DeepSeek 能尽快拿出更高性价比的 V4 模型,或媲美 o3 的 R2 模型,当然,它们都必须是不折不扣的开源可商用的模型。
DeepSeek 的下一代前沿模型,并非毫无痕迹可寻。代码与数学,多模态与自然语言本身,三者是 DeepSeek 创始人梁文锋押注的三个方向。DeepSeek 团队一直在自然语言模型之外的其他分支上探索,包括今年更新过一轮的数学定理证明模型 Prover 与自回归的统一多模态理解与生成模型 Janus 等。去年,成熟度最高的代码能力,已经融合进去了,下一代模型很可能就是原生多模态。
V4 或者 R2,至少对应着新的注意力机制创新的工程化与商业化。全新的 NSA(原生可训练稀疏注意力)机制,支持端到端的训练,而且硬件对齐友好,解决了此前很多稀疏注意力机制只在特定阶段受限起效的问题,为用户带去更长的上下文;名为 BSBR(带块检索的块稀疏注意力)的技术,可以高效捕捉与检索长期记忆。对 「记忆」 的完善,意味着仓库级代码生成、多轮智能体间互动以及科研深度的推理能力。
DeepSeek 之于整个 AI 生态,尤其是中国的 AI 生态的意义,不仅仅在于它会回答下一代模型怎么样,还会回答适配下一代模型的基础设施怎么样。年初 NSA 论文里提到了 「基于 Triton 实现硬件对齐的稀疏」,为算法从 CUDA 中解耦出来提供了可能性。

值得注意的是,尽管遭遇 DeepSeek 釜底抽薪般的挑战,ChatGPT 的用户增长及时长,都迎来了一次爆发。这使我们意识到,能提升模型的技术上限,并不意味着能做出好的应用和体验。DeepSeek 无志于此,但是谁又能用开源的模型做出真正杀手级的庆用呢?这可能无关 DeepSeek,但它的确是摆在中国 AI 创新者面前的一道命题。
强化学习与思维链
「董事会政变」 至今,不少 OpenAI 元老成员纷纷自立门户,资本相信他们将探索出有别于 「传统大模型」 的 AGI 之路,慷慨解囊。Ilya Sutzkever 的 SSI 估值已达 320 亿美元,Mira Murati 的 Thinking Machines Lab 估值也达到了 90 亿美元。它们几乎没有可以公开验证的产品,甚至连可供公开讨论的技术路线都付之阙如。
关于 SSI 的可证实的消息相当少。在社交媒体平台上,Ilya Sutzkever 与 SSI 的时间线都停留在一年前;公司官网也没有更新。不过,放心,SSI 的研发仍在推进,而且用的更多的是谷歌的 TPU。作为一家定位为 「纯粹的研究机构」,它短期内 「不会销售 AI 产品或者服务」,但它会向同行们汇报一下成立一年来的进展吗?
关于 AGI,Ilya 向外界传递过的最明确的信号,就是基于扩展定律的大模型预训练已死。他最早信仰扩展,也最早意识到它的瓶颈。去年,他暗示自己正在寻找新的范式,「现在,在正确的方向扩展,比什么都重要」。当然,他将最后的成果称为 SSI,即安全的超级人工智能。
它会与强化学习有关吗?Ilya 曾专注于强化学习;DeepSeek 也发现强化学习存在 aha 时刻;而 Anthropic 的 Dario Amodei,则在这两年里反复强调,强化学习威力强大,但又带来诸多安全问题,目前面临 AI 可解释性的紧迫性。也许,SSI 打算用强化学习训练出一个既强大又安全的超级人工智能?
Thinking Machines Lab 已经成立 3 个月。这家集聚了大量 OpenAI 元老成员的初创企业,「致力于通过论文发表和代码发布来推进科学进步」 的初创企业,至今没有预印本论文或产品发布。好在该公司的联合创始人 Lilian Weng 最近发了一篇长文,另一位联合创始人 John Schulman 也参与了文章修改。这篇凝聚了公司高管思想的文章,剖析的是大模型的推理能力从何而来,如何让大模型像人一样通过 「多想一会」 而变得更聪明。这可以说非常 AGI 了。
文章最后留下了几个开放性的问题,包括如何在无标准答案的情景下安全地让模型自我纠错,以及如何把推理阶段的增益蒸馏回基础模型,等等。
目前,人们确实已经意识到,「想多久」 与 「怎么想」 都很关键。从产品的角度,无论是 OpenAI 还是 Gemini,都给了用户以设定 「思考」 上限的权力。这能在简单问题上节省不少算力成本,而且思考越久也不见得准确率就一定更高。但这仍然不是 AGI 想要的,既然是 AGI,应该由 AI 来感知与规划自己应该思考多久。
在某种意义上,这些离开的 OpenAI 的大佬们,都在思考有关如何让 AI 更好地 「思考」 的问题。Ilya 认为 AI 自己可以决定从大量可能的答案中选取最好的那个,「它想得越深,就会越不可测」;而 Lilian Weng 则认为对 「测试时思考」 与 「思维链」 的研究,尤其是对那几个开放性问题的回答,将推进构建未来的 AI 系统。
程序合成与扩散文本生成
今年以来,程序合成 (program synthesis)与文本生成扩散 (Diffisuion)的早期探索也浮出水面。
深度学习框架 Keras 的创建者 François Chollet,和 AI SaaS 公司 Zapier 联合创始人 Mike Knoop,先后联手创办了 AI 测评非营利组织 ARC Prize Foundation,以及探索 AGI 的研究实验室 NDEA。他们不认为 o3 具备人类水平的智能,无法很好适应之前从未见过的新问题,算不上 AGI。
也许是在不断测试前沿模型中,两人终于意识到,不突破传统范式的局限性,就无法真正抵达 AGI。「我们正处于科学历史的关键时刻,世界值得每一种直接、独特的尝试来构建 AGI」,它就是程序合成 (program synthesis),能让人工智能仅通过少量示例,就对之前未见过的问题实现泛化。它也已经是每个前沿 AI 实验室如今都开始探索的一项技术。NDEA 相信,现在正处于程序合成的 AlexNet 时刻。
与在一串离散的数据中猜测最符合概率的数据不同,程序合成可以根据已知的线索找到逻辑正确的程序。这家公司时不时地在 X 上分享与程序合成相关的技术论文。最近的一篇是来自谷歌 DeepMind 的科学编程智能体 AlphaEvolve。这几天,陶哲轩惊叹它为解决数学难题提供了久违的 「加速度」。NDEA 认同 AlphaEvolve 的内在思路,正是程序合成的其中一种实现形式。

(说明:AlphaEvolve 是如何合成最佳程序的。)
同样是谷歌 DeepMind,最近还尝试了将扩散模型从图片生成用到了文本生成上,在最近的 I/O 大会上拿出了 Gemini Diffusion;正如 OpenAI 将图片生成从扩散模型带到了自回归模型。在传统范式逐步遭遇扩展定律的边际放缓后,大家都在尝试不同技术之间新的排列组合。
作为一款实验性的产品,Gemini Diffusion 的表现还不错。它速度更快,每秒输出近 1500 token,性能还不亚于 Gemini 2.0 Flash-Lite。但谷歌没有披露它的更多细节。
不过,谷歌不是第一个这么做的。很多人看好这条路线。某种程度上,它更像人类的思维模式,不是一次写一个词,而是先勾勒出思路,然后渐进地完善带掩码的文本,直到形成连贯的文本。它更具全局注意力,还能解决传统自回归模型无法逆步思考的顽疾。如果愿意付出更高的算力成本,就可以做到比自回归模型更高的准确率。
今年 2 月,中国人民大学发布了大型语言扩散模型 LlaDA-8B。很快,UCLA 联合 Meta 推出了 d1,港大联合华为诺亚推出了 Dream-7B,清华北大联合字节跳动推出了 Mmada,将探索文本扩散生成的边界,延伸至观察它在规模扩展、推理能力、原生多模型统一架构等领域。看起来,这些科技巨头尽管放缓了对 「暴力美学」 的追求,但都不排斥让团队成员匀出一点精力,去尝试下新的技术路线。

(说明:文本扩散可以比自回归生成更快更准确)
不过,目前这些研究主要仍然围绕参数规模 8B 大小的模型展开,没有验证其在更大参数规模下同样可以扩展。这项技术也面临如何更高效地在预训练中平衡 「扩散步骤或噪声增加策略」 的难题。
下半年更值得关注的,还是智能体的应用,它的商业模式的建立。与移动互联网时代不同,AI 智能体正面临着一个前所未有的竞争格局。
所以,下半年即将看到的是 AI 研究及应用的高收入增长+高现金消耗+高估值+高投资投入,包括中国的科技大厂都宣布增加资本支出,准备放手一搏。这对消费者而言是好消息,但是对其他方面,还有待观察。
米克尔经历了互联网的赢家通吃的时代,但是,她认为 AI 智能体时代未必如此,AI 商业化的下一阶段,也许并不是 「赢家通吃」 的竞争,而是一次融合与重构:
横向平台强调 「广度」,跨职能整合知识与工作逻辑;专业厂商则深耕 「深度」,提供能真正理解合规、合同与客户意图的 AI。
问题不在于 「平台」 还是 「专家」 谁能胜出,而在于谁能抽象出正确的技术层、掌握用户界面,并主导 「工作的逻辑」。
在 AI 时代,变现的路径不再仅仅取决于使用频率,而将取决于注意力、语境与控制权的归属。
但在地缘政治上却未必如此。全球 AI 竞争的核心是美中之间的战略博弈。米克尔报告认为,虽然美国公司在创新、芯片、云部署等方面占据领先,中国也在开源社区、国家级基础设施和政府主导的协同方面快速推进。
「两国都将人工智能视为经济杠杆,也视为地缘政治影响力的来源。」