【TechWeb】6 月 27 日,DeepSeek 团队联合北京大学发布名为 《DSpark》 的研究论文 (基于 speculative decoding 方向),提出一种用于加速大模型推理的新方法。

该技术在保持生成文本分布完全无损 (Lossless) 的前提下,成功突破了大语言模型 (LLM) 在高并发生产环境中的推理性能瓶颈,实测数据显示,其单用户生成速度较现有主流方案最高提升 85%。
目前,该框架已被部署在 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的真实线上流量中,大幅加速了大语言模型 (LLM) 的推理速度。
值得注意的是,DeepSeek 创始人梁文锋也位列论文作者名单之中。
大模型推理的 「速度焦虑」
据了解,主流语言模型生成文本时,基本采用 autoregressive(自回归) 方式。每生成一个新 token 都需要一次完整的前向传播,推理延迟随输出长度线性增长。这也造成了大模型回复总感觉很慢的原因。
在实时对话、多轮智能体工作流等高交互场景中,生成速度直接影响用户体验,也会影响 GPU 利用率。
推测解码技术提供了一条解决路径:用一个轻量级草稿模型快速生成若干候选 token,再由大模型批量验证。
然而,现有方案各有缺陷。自回归草稿模型逐 token 串行生成,质量虽高但生成延迟随候选长度线性增长;并行草稿模型虽能一次产出全部候选,但 token 间缺少依赖关系,导致后续候选被大量拒绝,浪费计算资源。
DSpark 的两把 「手术刀」
围绕上述两大瓶颈,DSpark 提出了两项互补机制。
一个是 「半自回归生成」 架构 (Semi-Autoregressive Generation)。
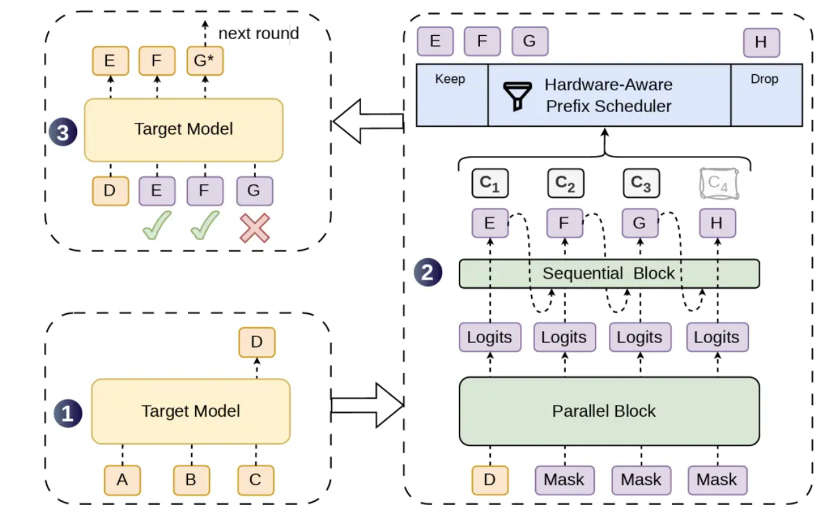
DSpark 在并行生成主干的基础上引入轻量级顺序模块,逐 token 注入前缀依赖信息。可以理解为:前面用并行方式快速铺开候选,后面再用一个很轻的顺序模块检查相邻 token 的衔接关系。
该模块提供两种实现——仅依赖前一个 token 的马尔可夫头,以及通过循环状态累积完整前缀信息的 RNN 头。实验表明,两层 Transformer 深度的 DSpark 即可在所有测试领域上超过五层 DFlash 的接受长度。
另一个是置信度调度验证机制。
传统方案对整段候选无差别校验,在高负载时大量算力被浪费在极可能被拒绝的尾部 token 上。
置信度调度验证机制,可根据不同请求的成功概率与系统负载,自适应调整验证长度,从而减少无效计算开销。
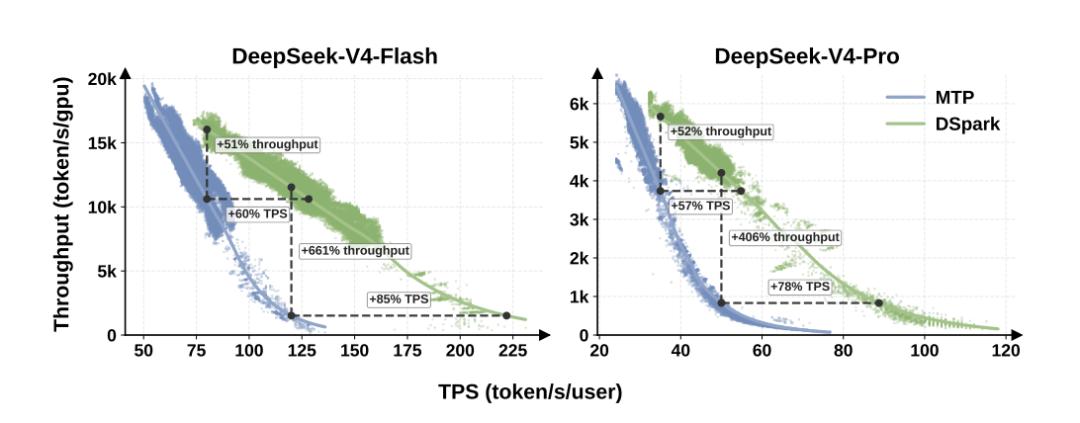
在离线测试中,该方法显著提升了可接受生成长度;在 DeepSeek-V4 线上系统中,相比基线模型,推理速度提升约 60%–85%,并有效降低高并发下的吞吐损耗。
DSpark 在每个候选位置输出置信度分数,预测该 token 的存活概率。硬件感知前缀调度器根据实时引擎吞吐量,为每个请求动态决定最优验证长度,优先将算力分配给预期回报最高的 token。
据了解,论文还同时开源了模型检查点与训练框架 DeepSpec,以推动社区进一步研究。DeepSpec 是一个面向 speculative decoding 训练的代码库,包含 Eagle3、DFlash 和 DSpark。

【TechWeb】6 月 27 日,DeepSeek 团队联合北京大学发布名为 《DSpark》 的研究论文 (基于 speculative decoding 方向),提出一种用于加速大模型推理的新方法。
该技术在保持生成文本分布完全无损 (Lossless) 的前提下,成功突破了大语言模型 (LLM) 在高并发生产环境中的推理性能瓶颈,实测数据显示,其单用户生成速度较现有主流方案最高提升 85%。
目前,该框架已被部署在 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的真实线上流量中,大幅加速了大语言模型 (LLM) 的推理速度。
值得注意的是,DeepSeek 创始人梁文锋也位列论文作者名单之中。
大模型推理的 「速度焦虑」
据了解,主流语言模型生成文本时,基本采用 autoregressive(自回归) 方式。每生成一个新 token 都需要一次完整的前向传播,推理延迟随输出长度线性增长。这也造成了大模型回复总感觉很慢的原因。
在实时对话、多轮智能体工作流等高交互场景中,生成速度直接影响用户体验,也会影响 GPU 利用率。
推测解码技术提供了一条解决路径:用一个轻量级草稿模型快速生成若干候选 token,再由大模型批量验证。
然而,现有方案各有缺陷。自回归草稿模型逐 token 串行生成,质量虽高但生成延迟随候选长度线性增长;并行草稿模型虽能一次产出全部候选,但 token 间缺少依赖关系,导致后续候选被大量拒绝,浪费计算资源。
DSpark 的两把 「手术刀」
围绕上述两大瓶颈,DSpark 提出了两项互补机制。
一个是 「半自回归生成」 架构 (Semi-Autoregressive Generation)。
DSpark 在并行生成主干的基础上引入轻量级顺序模块,逐 token 注入前缀依赖信息。可以理解为:前面用并行方式快速铺开候选,后面再用一个很轻的顺序模块检查相邻 token 的衔接关系。
该模块提供两种实现——仅依赖前一个 token 的马尔可夫头,以及通过循环状态累积完整前缀信息的 RNN 头。实验表明,两层 Transformer 深度的 DSpark 即可在所有测试领域上超过五层 DFlash 的接受长度。
另一个是置信度调度验证机制。
传统方案对整段候选无差别校验,在高负载时大量算力被浪费在极可能被拒绝的尾部 token 上。
置信度调度验证机制,可根据不同请求的成功概率与系统负载,自适应调整验证长度,从而减少无效计算开销。
在离线测试中,该方法显著提升了可接受生成长度;在 DeepSeek-V4 线上系统中,相比基线模型,推理速度提升约 60%–85%,并有效降低高并发下的吞吐损耗。
DSpark 在每个候选位置输出置信度分数,预测该 token 的存活概率。硬件感知前缀调度器根据实时引擎吞吐量,为每个请求动态决定最优验证长度,优先将算力分配给预期回报最高的 token。
据了解,论文还同时开源了模型检查点与训练框架 DeepSpec,以推动社区进一步研究。DeepSpec 是一个面向 speculative decoding 训练的代码库,包含 Eagle3、DFlash 和 DSpark。
【TechWeb】6 月 27 日,DeepSeek 团队联合北京大学发布名为 《DSpark》 的研究论文 (基于 speculative decoding 方向),提出一种用于加速大模型推理的新方法。
该技术在保持生成文本分布完全无损 (Lossless) 的前提下,成功突破了大语言模型 (LLM) 在高并发生产环境中的推理性能瓶颈,实测数据显示,其单用户生成速度较现有主流方案最高提升 85%。
目前,该框架已被部署在 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的真实线上流量中,大幅加速了大语言模型 (LLM) 的推理速度。
值得注意的是,DeepSeek 创始人梁文锋也位列论文作者名单之中。
大模型推理的 「速度焦虑」
据了解,主流语言模型生成文本时,基本采用 autoregressive(自回归) 方式。每生成一个新 token 都需要一次完整的前向传播,推理延迟随输出长度线性增长。这也造成了大模型回复总感觉很慢的原因。
在实时对话、多轮智能体工作流等高交互场景中,生成速度直接影响用户体验,也会影响 GPU 利用率。
推测解码技术提供了一条解决路径:用一个轻量级草稿模型快速生成若干候选 token,再由大模型批量验证。
然而,现有方案各有缺陷。自回归草稿模型逐 token 串行生成,质量虽高但生成延迟随候选长度线性增长;并行草稿模型虽能一次产出全部候选,但 token 间缺少依赖关系,导致后续候选被大量拒绝,浪费计算资源。
DSpark 的两把 「手术刀」
围绕上述两大瓶颈,DSpark 提出了两项互补机制。
一个是 「半自回归生成」 架构 (Semi-Autoregressive Generation)。
DSpark 在并行生成主干的基础上引入轻量级顺序模块,逐 token 注入前缀依赖信息。可以理解为:前面用并行方式快速铺开候选,后面再用一个很轻的顺序模块检查相邻 token 的衔接关系。
该模块提供两种实现——仅依赖前一个 token 的马尔可夫头,以及通过循环状态累积完整前缀信息的 RNN 头。实验表明,两层 Transformer 深度的 DSpark 即可在所有测试领域上超过五层 DFlash 的接受长度。
另一个是置信度调度验证机制。
传统方案对整段候选无差别校验,在高负载时大量算力被浪费在极可能被拒绝的尾部 token 上。
置信度调度验证机制,可根据不同请求的成功概率与系统负载,自适应调整验证长度,从而减少无效计算开销。
在离线测试中,该方法显著提升了可接受生成长度;在 DeepSeek-V4 线上系统中,相比基线模型,推理速度提升约 60%–85%,并有效降低高并发下的吞吐损耗。
DSpark 在每个候选位置输出置信度分数,预测该 token 的存活概率。硬件感知前缀调度器根据实时引擎吞吐量,为每个请求动态决定最优验证长度,优先将算力分配给预期回报最高的 token。
据了解,论文还同时开源了模型检查点与训练框架 DeepSpec,以推动社区进一步研究。DeepSpec 是一个面向 speculative decoding 训练的代码库,包含 Eagle3、DFlash 和 DSpark。
【TechWeb】6 月 27 日,DeepSeek 团队联合北京大学发布名为 《DSpark》 的研究论文 (基于 speculative decoding 方向),提出一种用于加速大模型推理的新方法。
该技术在保持生成文本分布完全无损 (Lossless) 的前提下,成功突破了大语言模型 (LLM) 在高并发生产环境中的推理性能瓶颈,实测数据显示,其单用户生成速度较现有主流方案最高提升 85%。
目前,该框架已被部署在 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的真实线上流量中,大幅加速了大语言模型 (LLM) 的推理速度。
值得注意的是,DeepSeek 创始人梁文锋也位列论文作者名单之中。
大模型推理的 「速度焦虑」
据了解,主流语言模型生成文本时,基本采用 autoregressive(自回归) 方式。每生成一个新 token 都需要一次完整的前向传播,推理延迟随输出长度线性增长。这也造成了大模型回复总感觉很慢的原因。
在实时对话、多轮智能体工作流等高交互场景中,生成速度直接影响用户体验,也会影响 GPU 利用率。
推测解码技术提供了一条解决路径:用一个轻量级草稿模型快速生成若干候选 token,再由大模型批量验证。
然而,现有方案各有缺陷。自回归草稿模型逐 token 串行生成,质量虽高但生成延迟随候选长度线性增长;并行草稿模型虽能一次产出全部候选,但 token 间缺少依赖关系,导致后续候选被大量拒绝,浪费计算资源。
DSpark 的两把 「手术刀」
围绕上述两大瓶颈,DSpark 提出了两项互补机制。
一个是 「半自回归生成」 架构 (Semi-Autoregressive Generation)。
DSpark 在并行生成主干的基础上引入轻量级顺序模块,逐 token 注入前缀依赖信息。可以理解为:前面用并行方式快速铺开候选,后面再用一个很轻的顺序模块检查相邻 token 的衔接关系。
该模块提供两种实现——仅依赖前一个 token 的马尔可夫头,以及通过循环状态累积完整前缀信息的 RNN 头。实验表明,两层 Transformer 深度的 DSpark 即可在所有测试领域上超过五层 DFlash 的接受长度。
另一个是置信度调度验证机制。
传统方案对整段候选无差别校验,在高负载时大量算力被浪费在极可能被拒绝的尾部 token 上。
置信度调度验证机制,可根据不同请求的成功概率与系统负载,自适应调整验证长度,从而减少无效计算开销。
在离线测试中,该方法显著提升了可接受生成长度;在 DeepSeek-V4 线上系统中,相比基线模型,推理速度提升约 60%–85%,并有效降低高并发下的吞吐损耗。
DSpark 在每个候选位置输出置信度分数,预测该 token 的存活概率。硬件感知前缀调度器根据实时引擎吞吐量,为每个请求动态决定最优验证长度,优先将算力分配给预期回报最高的 token。
据了解,论文还同时开源了模型检查点与训练框架 DeepSpec,以推动社区进一步研究。DeepSpec 是一个面向 speculative decoding 训练的代码库,包含 Eagle3、DFlash 和 DSpark。