(本文作者为 新眸,钛媒体经授权发布)
Related articles


文 | 新眸,作者 | 李小东
过去一年多,大模型圈每季度至少经历一次牌面重洗。有人在多模态端连出三张底牌,有人在 Agent 赛道一把梭哈,还有人干脆掀了桌子,把模型拆成零件来卖。

但所有人都在等一个人出牌。
这人一年多没动静。2025 年 1 月 R1 发布之后,他就像从牌桌上消失了。中间 V3.1、V3.2、FlashMLA、DualPath 这些零零散散的更新,充其量算在桌下换了一手牌,没人知道他手里到底攥着什么。
4 月 24 日,DeepSeek 终于把牌撂下来了——V4 预览版正式上线并开源,两个版本:V4-Pro 和 V4-Flash。
Pro 对标顶级闭源。Agent Coding 模式下,内部测评体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。世界知识测评大幅领先其他开源模型,仅稍逊于 Gemini Pro 3.1。数学和代码推理性能上,官方称“ 超越当前所有已公开评测的开源模型”。
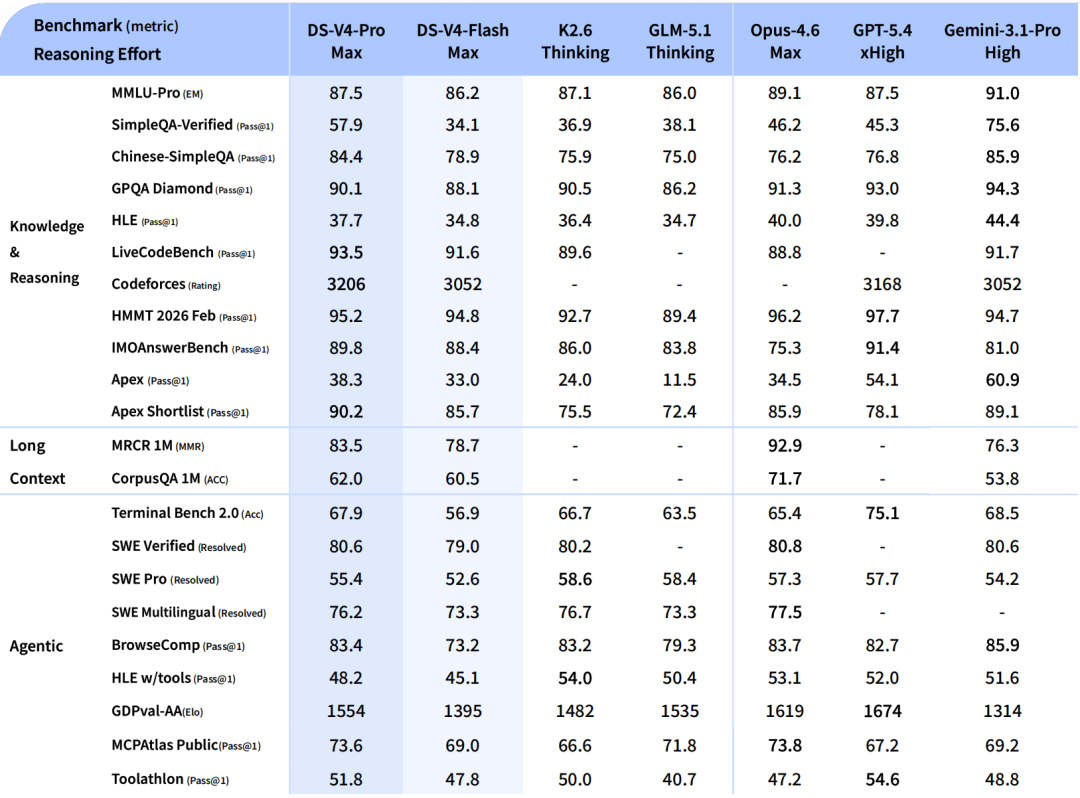
Flash 是轻量版,推理能力接近 Pro,但参数和激活更小,API 响应更快,成本更低。两款都支持百万 token 上下文—— 而且是标配。
问题来了:一家公司,在同行疯狂跑马圈地的十五个月里基本沉默,一出手却直接把自己钉回了行业锚点,这说明什么?
说明牌桌上的人根本没离开过。他只是换了一种打法。
01 架构的延续性革命
要理解 V4,先得回看 V3。
2024 年底,当时大模型行业的主流叙事还是“ 参数越大越强”。训练一个大几千亿参数的模型,成本动辄千万美元起步。DeepSeek V3 用 6710 亿总参数、每次推理激活 37B 专家的 MoE 架构,把单次训练成本压到了 500 万美元出头。
不靠砍参数量,靠 MoE 路由策略、DSA 注意力机制和工程层面的极致优化,说白了,把每一分算力都花在刀刃上。

V4 走的还是这条路,但走到了更远的地方。
技术规格上,V4 完整版总参数跃升至 1.6 万亿,2850 亿的 Lite 版作为更经济的选项。注意力机制升级为 DSA2,整合了 DeepSeek V3/R1 中的 DSA 设计,同时引入今年初论文中提出的 NSA 稀疏注意力方案。MoE 系统启用 Mega 内核结构,每层配置 384 个专家,每次推理激活其中 6 个。残差连接沿用 Hyper-Connections 方案,这条路在近期的 DeepGemm 更新中已有预演。
这些名词堆在一起,外行看着像天书,但业内人一眼就能读出含义:V4 是 DeepSeek 过去两年来所有技术积累的集大成。
但最值得关注的变化,在于它的实现方式。
V4 延期发布的真正原因,不是什么 bug 修不完,而是 DeepSeek 把整套系统从英伟达生态搬到了华为昇腾芯片上。
这不是换个驱动的事儿。DeepSeek R1 当年对英伟达 GPU 的 PTX 底层做了极致优化,这是它“ 花小钱办大事” 的核心竞争力。PTX 是 CUDA 生态里的中间语言,深入到这层,才把当时能压榨的性能都压了出来。但转到华为昇腾之后,基于英伟达的所有工程积累全部作废。整套底层代码、调度逻辑、工程体系,要重写一遍。
难度在哪里?大模型参数达到万亿级别之后,算力压力从“ 纯计算” 转向了“ 系统调度与通信”。DeepSeek V4 虽然通过 MoE 降低了单次推理的计算量,但对内存带宽、芯片间互联、KV Cache 管理的要求反而更高了。
英伟达生态里,Hub 上关于 H100/B200 通过 NVLink 构建高带宽互联的讨论早已证实,其单节点 GPU 间带宽可达 TB/s 级别。昇腾在这些指标上有明显差距,更多依赖光模块进行跨节点扩展,会引入额外的延迟和同步开销。软件层面,昇腾的 CANN 框架在算子覆盖、自动并行、内核融合等方面的成熟度,与 CUDA 生态仍不是同一个量级。
代价就是时间。V4 原计划今年农历新年或 2-3 月发布,一路推到 4 月才亮相。按路透社的报道,V4 将运行在华为最新的昇腾芯片上,工程师花了大量时间重写核心代码。V4 计划发布两个版本:完整版面向华为昇腾芯片,轻量版可在其他国产芯片上运行。
这件事的意义怎么强调都不过分。过去两年,大模型世界建了一座巨大工厂,所有的工具、标尺、流水线都是英文写的。你在这个工厂里干活,就必须用别人的工具。英伟达 CEO 黄仁勋近期的反应很能说明问题,他说 DeepSeek 基于华为平台的新模型“ 对美国来说将是一个糟糕的结果”。这话从英伟达老板嘴里说出来,分量绝对不轻。
一旦有顶级模型在中国国产硬件上跑通了稳定高效的推理,美国芯片的护城河就不再牢固。而在 4 月 24 日的发布中,官方已明确回应,V4 在下半年将正式支持华为算力。
02 推理端开始降价,百万 token 的平权
架构的优化落到地面,看的是成本。而成本控制这件事,DeepSeek 以前干过一次了。
2025 年初,当各家大模型还在拼训练端烧钱速度的时候,DeepSeek V3 用一套优化到极致的 MoE 加 DSA 架构,把同等参数量级下的训练成本砍到了业内平均水平的几分之一。有评论称之为“ 训练端通缩奇迹”。
但过去一年,AI 行业的问题已经从“ 怎么训出一个好模型” 变成了“ 怎么让好模型被用得起”。2026 年中国日均 Token 调用量突破 140 万亿,两年间涨了一千多倍。当调用量以这个速度膨胀,推理成本就成了唯一的命门。
V4 在推理端做了两道减法。第一道在架构层面: 注意力机制从密集计算改为 DSA2 稀疏注意力,Token 维度直接做压缩。官方表述是“ 相比传统方法,对计算和显存的需求大幅降低”。第二道在精度层面:支持 FP4 精度,对显存的要求在 FP8 基础上再降一半。
路透社此前报道的推算也佐证了效率控制的成果:V4 每个 token 仅激活约 370 亿参数,推理成本与 V3 保持在同一量级。参数量翻了不止一倍,推理成本却没涨。这意味着大到需要算力集群的企业,小到调用 API 的创业者,都能在更大规模的模型上维持相近的预算。
而 DeepSeek 长期以来的定价也起到了降低门槛的作用。模型好用,用得便宜,调用量自然持续增长。反过来持续分摊摊销研发投入,再推动更大规模模型的开放,形成一个正向飞轮。
这个逻辑过去一年在开源模型里跑通了不止一家,V4 大概率是这条路上最新的加速器。
V4 还有一个容易被忽视的信号:百万 token 上下文成为标配。
一年前,1M 上下文还是 Gemini 独家的王牌,其他所有闭源模型普遍在 128K 或 200K 之间,开源生态几乎没人碰这个量级。DeepSeek 没有把它包装成高端增值服务,而是明确宣布从今天开始,V4 所有官方服务的上下文默认都是 1M。而且开源。
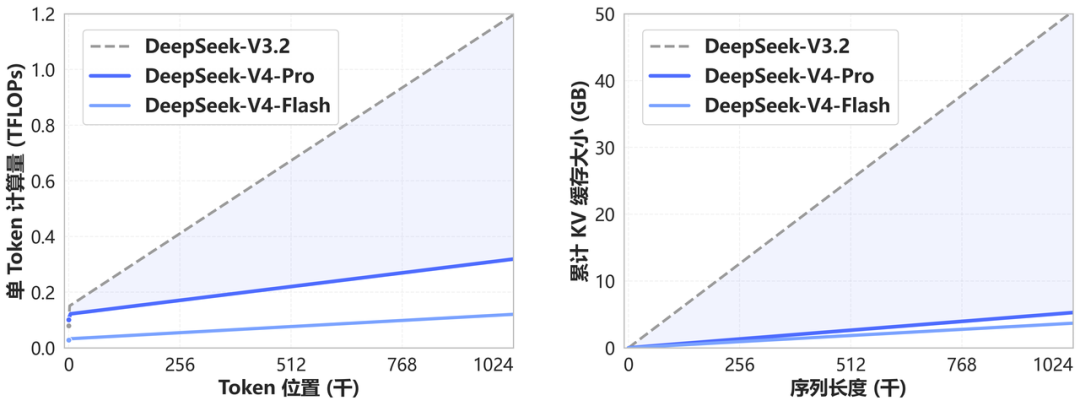
它的技术路线也解释得很干脆。用一种全新的注意力机制在 token 维度上做压缩,同时配合 DSA 稀疏注意力,直接把传统 Attention 的计算量和显存需求量削了下去,使得模型处理 1M 上下文时的实际开销并不比处理 128K 高多少,甚至可以忽略不计。
此前的方案为了支撑长上下文,往往要追加内存、增加缓存层级。而 V4 把这条路走了个捷径,且已经开放给所有人。
这意味着什么?中小开发者用零门槛把整本 《三体》 塞进提示词,法律合同分析可以全文一次性送入模型,长周期多轮 Agent 调用完全免去记忆压缩的魔改。
2025 年,大模型行业的叙事还是“ 能力平权”,开源模型追上闭源,大家都能用。2026 年,叙事进一步延伸,变成“ 使用平权”,好模型不仅要追得上,还得用得起、用得方便。
当把 1M 上下文和 Agent 能力同时开放,开发者的天花板一下子被抬高了很多。而这扇门打开之前,做 Agent 的团队光是处理超长上下文的记忆管理就要花掉一半精力。
03 大厂的焦灼和各自的算盘
V4 的发布会不是在真空中开的。牌桌上已经换了不知道几轮玩家。
大厂这边,各家动作密集到了“ 每周都有新东西” 的程度。2026 年马年春节前后,字节、阿里、腾讯、百度四家累计投入超 45 亿元,以红包、免单、科技礼品等形式推动 AI 应用走向全民。
技术竞赛进入胶着状态。2 月,阿里、字节、MiniMax 密集发布新一代模型产品,MiniMax M2.5、Kimi K2.5、GLM-5 等中国模型在 OpenRouters 上的 Tokens 消耗数已排进全球前三。
前不久,腾讯发布混元世界模型 2.0,支持二次编辑并直接导入 Unity 和 UE 引擎;阿里 ATH 事业部发布 HappyOyster 世界模拟器,支持高保真动态场景生成。同月,京东探索研究院开源自研的 JoyAI-Image-Edit 图像模型,切入了 AI 空间理解的核心难题。
云厂商的模型策略也从“ 押注一颗独苗” 转向了多模型整合。“ 模型超市” 遍地开花,阿里云、百度智能云、腾讯云都在把多家不同厂商的模型集中纳入同一平台,按需分发推荐。这背后的逻辑很清楚,大模型正在从研发资产走向流通商品,掌握分发渠道比拥有单一模型的技术优势,市场回报更确定。
而 DeepSeek 面临的局面比一年前复杂得多。
2026 年的 Agent 繁荣带来了 Token 消耗的狂欢,从 OpenClaw 到 Hermas 都在朝同一个方向用力,把大模型调用频次推向指数级更高。智谱、MiniMax 等厂商凭借海量的 API 调用在推理端闷声发大财,甚至推动了阿里、智谱和 MiniMax 自身转向闭源。
当对手的战争已经推进到了多模态全能矩阵和业务深融的 Agent 生态时,单一的基座能力和文本推理已经不足以构成护城河。V4 不再打单点突破的孤胆英雄,而是必须同时在开源模型基准、超长上下文易用性、推理成本控制以及国产硬件支持等多个棋盘上取得优势。
从发布结果看,V4 交出的答卷确实验证了它对当下竞争焦点的理解。而它面临的核心考验,其实已经被精准概括,“ 积累的 Prompt 技巧,都是基于 DeepSeek 架构,那在一定程度上会增加开发者更换模型的成本,形成了隐形的技术定价权”。
技术定价权的持久性,取决于 V4 发布之后的开源生态运营节奏和商业模式的策略纵深。
回头看,DeepSeek V3 那一次,改变的是“ 训练成本”。当时行业共识是训练大几千亿参数的模型动辄几千万美元,DeepSeek 用 500 万美元证明这个数字可以压缩一个量级。之后各家的训练成本预估一路走低,开源和闭源的成本基线被重新书写。
V4 这次做的是另一件事:它用万亿参数级的模型,把基准能力、百万级上下文和 Agent 能力同时打包、拆开、开源,向行业宣告—— 成本这一刀接下来砍向推理端。
这对不同玩家的打击是不同的。对重注闭源的大厂来说,压力在于竞争不再只是性能对标,而是开源社区把“ 水电煤” 的价格压穿了之后,闭源要维持溢价变得越来越困难。
从 OpenAI 到 Anthropic,包括国内闭源巨头,面对 Arch Lint 的价格锚点,定价体系只会变得前所未有的透明。对于盯紧基础层算力供需的服务商来说,当推理效率大幅提高、能效持续优化,整个算力需求的预期反而可能被重新上修。
更深一层的意义在于硬件生态。黄仁勋说“DeepSeek 基于华为平台的新模型对美国来说将是一个糟糕的结果”,恰好点出了这轮 AI 竞争的核心,从算法比拼转到系统工程能力比拼,再到硬件生态的绑定与突围。
V4 会不会成为第一个真正跑通国产算力闭环的万亿级大模型,现在还没有定论,但它在“ 去 CUDA 化” 这条路上至少提供了一种可验证的参照系。
至于 DeepSeek 自己,融资、人才、商业化,该面对的问题一个不会少。据上海证券报消息,DeepSeek 已启动成立以来首次外部融资,目标估值不低于 100 亿美元,计划筹集至少 3 亿美元。首代模型核心作者之一罗福莉转投小米,R1 核心研究员、GRPO 核心发明者郭达雅加入字节跳动 Seed。
大模型赛道的残酷在于,你必须在飞驰的列车上边换轮子边踩油门,停下来哪怕三个月,就可能被甩出牌桌。
DeepSeek 停了一年多,这期间对面的人一直在不停地发牌。现在它终于亮出了自己的牌。只看一个开局,胜负还远未到来,但有一点确切无误:这家公司的牌,从 V3 打到 V4,不打散牌,一把王炸。
无论最终谁是赢家,这轮牌局的围观价值,远远胜过任何一个模型的跑分结果。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App