Related articles



北京时间 2026 年 4 月 3 日凌晨,Google DeepMind 正式发布新一代开放模型系列——Gemma 4。官方博客标题写:「Byte for byte, the most capable open models」——逐字节衡量,这是迄今为止最强悍的开源模型。
据官方发布的博客,在 Arena AI 文本排行榜上,Gemma 4 的 31B Dense 模型以 307 亿参数规模登上开源模型全球第三,26B A4B MoE 模型位居第六,后者推理时仅激活 38 亿参数,却击败了参数量数百亿乃至数千亿级别的竞品。
当整个行业还在为大模型 「越大越好」 的军备竞赛焦虑时,谷歌选择用工程效率与推理密度的极致优化,给出了一条截然不同的技术路径。
四款模型,四个战场
Gemma 4 此次一口气释放了四个规格,覆盖了从端侧嵌入式设备到本地开发工作站的完整算力梯度:

从关键技术数据看,26B A4B MoE 模型推理时仅激活 38 亿参数 (总参 252 亿),却在 Arena AI 排行榜击败了多款参数量达数百亿甚至数千亿级别的竞品,包括通义千问 Qwen3-235B(2350 亿) 和 Meta Llama-3.1-405B(4050 亿) 等。31B Dense 未量化版本可在单张 80GB NVIDIA H100 上运行,量化后可部署于消费级 GPU。
边缘模型 E2B/E4B 支持原生音频输入,可进行语音识别与理解。全系列模型均原生支持视频与图像处理,支持可变分辨率输入。
这一产品矩阵的逻辑在于:小模型打 「无处不在」,大模型打 「无处不在的前沿智能」。
E2B 和 E4B 被谷歌定义为核心战略——「移动优先 AI」(mobile-first AI),专为数十亿 Android 设备及物联网终端设计;26B 和 31B 则瞄准本地开发、IDE 辅助和 Agent 工作流。
与 Gemini 3 同源的技术底座
一个容易被忽略但至关重要的信息是:Gemma 4 基于与闭源旗舰模型 Gemini 3 相同的研究成果与技术架构构建。这意味着,开源社区获得了与谷歌内部顶级闭源模型处于同一技术世代的推理能力。
这种 「开源共享底层技术」 的做法,在 Gemma 系列中一直延续,但在第四代上更进一步。Gemma 4 在以下能力维度上实现提升:
• 高级推理 (Advanced Reasoning):支持多步规划与深度逻辑链,在数学和指令遵循基准测试上表现显著提升,不再止步于简单对话,而是能够处理复杂逻辑与 Agent 工作流。
• Agentic 工作流原生支持:内置函数调用 (function-calling)、结构化 JSON 输出、原生系统指令,使开发者能够直接构建自主智能体,与外部工具和 API 可靠交互并执行完整工作流。
• 高质量离线代码生成:将本地工作站转变为本地优先的 AI 编程助手。
• 多模态原生:全部模型原生处理视频和图像,支持可变分辨率输入,在 OCR 和图表理解等视觉任务上表现突出。E2B 和 E4B 还支持原生音频输入。
• 超长上下文:边缘模型支持 128K 上下文窗口,大模型最高支持 256K,可在单次提示中处理代码仓库或长篇文档。
• 140+语言原生训练:原生支持超过 140 种语言,覆盖全球用户群体。
Gemma 4 的另一层重大信号,在于其许可证选择——Apache 2.0。
此前 Gemma 系列采用的条件性许可协议曾引发社区持续争论。此次转向 Apache 2.0——业界最宽松、对商业用途最友好的开源许可证之一——意味着开发者获得了完全的数据主权、基础设施控制权和模型控制权,可在本地或云端自由构建和部署。
「Gemma 4 以 Apache 2.0 许可证发布是一个巨大的里程碑。我们非常激动能在发布首日就在 Hugging Face 上支持 Gemma 4 家族。」Clément Delangue,Hugging Face 联合创始人兼 CEO 表示。
谷歌官方在博文中明确表示,这一变化直接回应了开发者社区的反馈:「构建 AI 的未来需要协作方式,我们相信在不设限制性障碍的情况下赋能开发者生态系统。」
或许,对谷歌来说,许可证变更意味着一次战略定位的调整。当 Meta 的 Llama 系列已经以宽松许可占据开源生态心智时,谷歌如果继续在许可条款上设限,只会加速开发者向竞品生态迁移。Apache 2.0 是参与开源竞争的 「入场券」,而非 「加分项」。
从边缘到云端:端侧 AI 的 「填满」 攻势
Gemma 4 最值得产业界关注的战略动作,可能是其边缘侧布局。
E2B 和 E4B 从底层为计算与内存效率而设计,推理时仅分别激活 20 亿和 40 亿参数,以保护设备的 RAM 和电池寿命。谷歌 Pixel 团队与高通(Qualcomm)、联发科 (MediaTek) 深度合作,使这些多模态模型能在手机、树莓派、NVIDIA Jetson Orin Nano 等设备上完全离线运行,且延迟接近于零。
端侧生态整合要点:
• Android 开发者可通过 AICore Developer Preview 进行 Agent 流程原型设计,与未来的 Gemini Nano 4 保持向前兼容。
• Android Studio 中可驱动 Agent Mode 进行应用开发。
• ML Kit GenAI Prompt API 支持生产级 Android 应用构建。
• Google AI Edge Gallery 提供 E4B 和 E2B 的即时体验入口。
这释放了一个明确的信号:谷歌正在将端侧 AI 从 「实验品」 推向 「基础设施」。当 4B 参数级别模型能够在手机端实现多模态推理、OCR、语音识别,且完全离线运行,「云端依赖」 便不再是 AI 能力的必要前提。结合 256K 上下文窗口的处理能力,「长文档本地分析」「离线代码审查」 等场景将从概念走向日常。
在发布首日,Gemma 4 就获得了主流 AI 工具链的全面支持,这在开源模型发布史上并不多见:
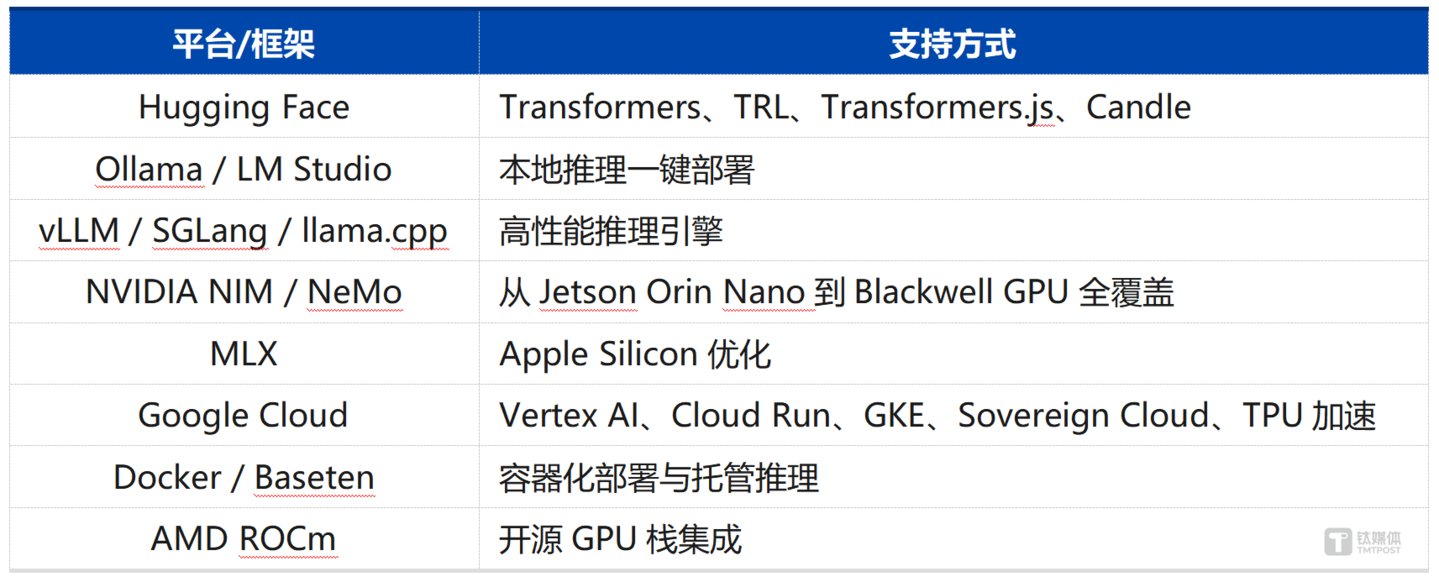
从 Hugging Face 到 NVIDIA NIM,从 Apple MLX 到 AMD ROCm,从 Docker 到 Google Cloud——Gemma 4 的部署路径覆盖了消费级硬件、企业级基础设施和三大云平台。值得注意的是,谷歌还提供了 Kaggle 上的 「Gemma 4 Good Challenge」 竞赛,鼓励开发者利用该模型构建有社会影响力的应用,延续 Gemma 系列的社区运营传统。
自第一代发布以来,Gemma 系列累计下载量已超过 4 亿次,衍生变体超过 10 万个。Apache 2.0 许可之下,这一生态有望在第四代上实现更大幅度的扩张。
开源模型进入 「效率竞赛」 阶段
Gemma 4 的发布,使开源大模型竞争进入了一个新阶段——「效率竞赛」 取代 「规模竞赛」 成为核心叙事。
当 26B A4B MoE 模型能以 38 亿激活参数击败参数量数百倍的竞品,「参数效率」(intelligence-per-parameter) 成为衡量开源模型价值的新标尺。这不仅是工程能力的体现,更是商业策略的选择:在消费级硬件上实现前沿推理能力,意味着更低的部署成本、更快的推理速度、更广泛的适用场景。
与闭源模型不同,开源模型的竞争逻辑天然是多维的——许可证宽松度、硬件适配广度、社区生态活跃度、微调友好度,每一项都可能成为决定胜负的关键变量。Gemma 4 在 Apache 2.0 许可、四规格矩阵、140+语言覆盖、首日工具链全支持上的组合拳,显然是经过精密计算的战略布局。
对于中国开发者而言,Gemma 4 的 256K 上下文窗口和原生中文支持 (140+语言包含中文),配合 Apache 2.0 的完全自由部署权,意味着在国内合规框架下也有本地化落地的技术空间。
Gemma 4 的发布不是一次简单的模型更新,而是开源 AI 领域的一次结构性位移。当端侧 4B 参数模型能够处理多模态、语音、长上下文任务,当 307 亿参数模型可以在单张 H100 上运行且跻身开源排行榜前三,「本地 AI」 与 「云端 AI」 的能力边界正在被重新定义。
谷歌选择了同时开放所有模型权重、拥抱 Apache 2.0、覆盖从手机到云端的全硬件栈——这种 「全栈开源」 策略,既是对 Meta Llama 系列和 Mistral 等开源竞品的正面回应,也是对 「闭源才能维持技术壁垒」 这一传统认知的直接挑战。
开源模型的下一个临界点,或许不再是 「谁参数更大」,而是 「谁在更小的体积内装进了更多的智能」。Gemma 4 给出的答案,至少在今天是:byte for byte,它是目前最强的。(本文首发钛媒体 APP,作者 | 硅谷 Tech_news,编辑 | 秦聪慧)